The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures. The Hadoop library contains two major components HDFS and MapReduce, in this post we will go inside each HDFS part and discover how it works internally.
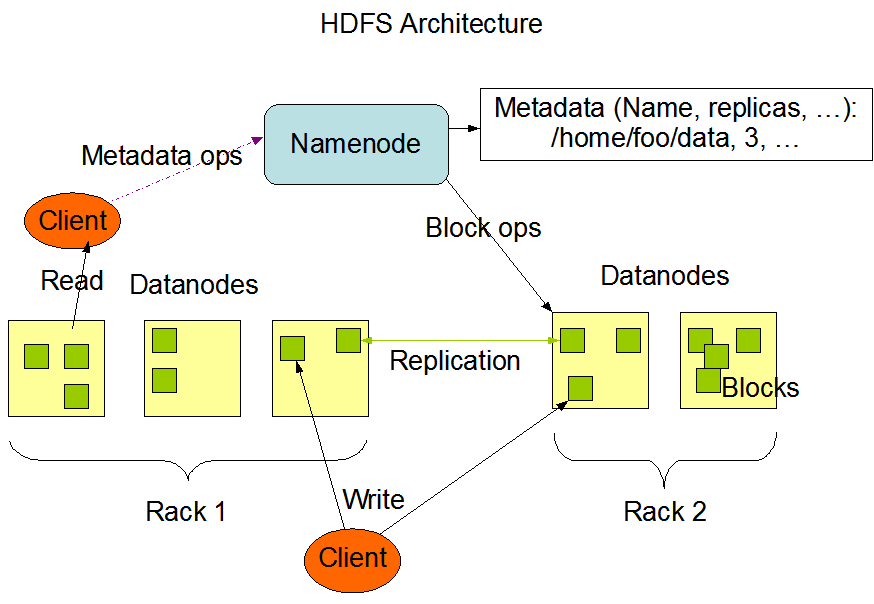
HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on.
HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
HDFS analysis
After the analysis of the Hadoop with JArchitect, here’s the dependency graph of the hdfs project.
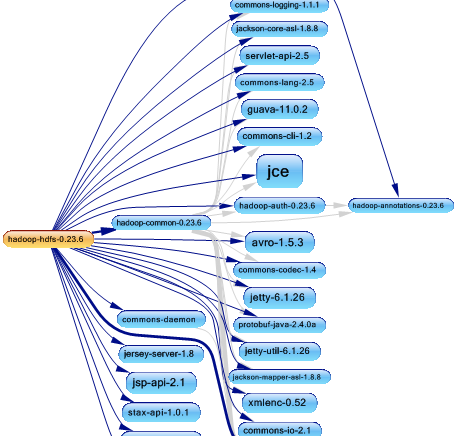
To achieve its job, hdfs uses many third party libs like guava, jetty, jackson and others. The DSM (Design Structure Matrix) give us more info about the weight of using each lib.
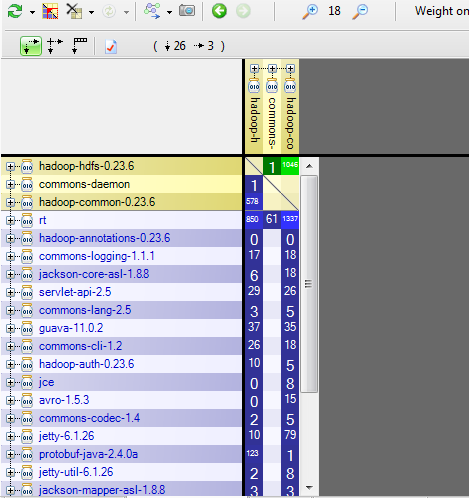
HDFS use mostly rt, hadoop-common and protobuf libraries. When external libs are used, it’s better to check if we can easily change a third party lib by another one without impacting the whole application, there are many reasons that can encourage us to change a third party lib. The other lib could:
- Have more features
- More performent
- More secure
Let’s take the example of jetty lib and search which methods from hdfs use it directly. from m in Methods where m.IsUsing (“jetty-6.1.26″) && m.ParentProject.Name==”hadoop-hdfs-0.23.6″ select new {m, m.NbBCInstructions}
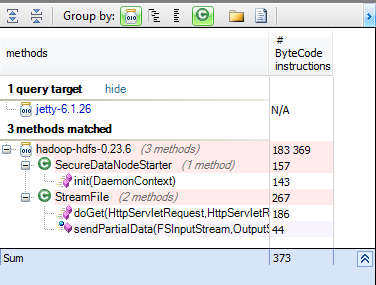
Only few methods use directly jetty lib, and changing it with another one will be very easy. In general it’s very interesting to isolate when you can the using of an external lib in only some classes, it can help to maintain and evolve the project easily. Let’s discover now the major HDFS components:
I-DataNode
Startup
To discover how to launch a data node, let’s search before all entry points of the hdfs jar. from m in Methods where m.Name.Contains(“main(String[])”) && m.IsStatic select new {m, m.NbBCInstructions}
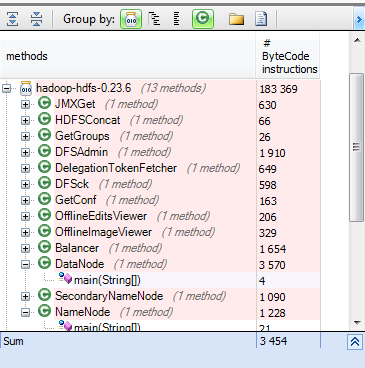
hdfs has many entries like DFSAdmin, DfSsc, Balancer and HDFSConcat. For the data node the entry point concerned is the DataNode class, and here’s what happen when its main method is invoked.
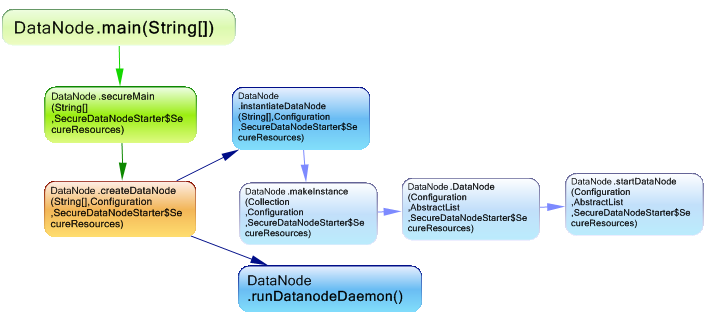
The main method invoke first securemain and pass the param securityresources to it, when the node is started in a not secure cluster this param is null, however in the case of starting it in a secure environment, the param is assigned with the secure resources. The SecureResources class contains two attributes:
- streamingSocket: secure port for data streaming to datanode.
- listner: a secure listener for the web server.
And here are the methods invoked from DataNode.StartDataNode.
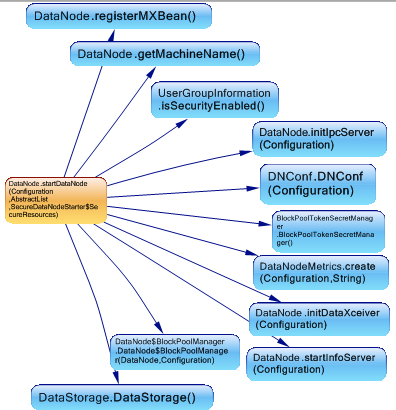
This method initialize IPCServer,DataXceiver which is the thread for processing incoming/outgoing data stream, create data node metrics instance.
How data is managed?
The DataNode class has an attribute named data of type FSDatasetinterface. FSDatasetinterface is an interface for the underlying storage that stores blocks for a data node. Let’s search which implementations are available in Hadoop. from t in Types where t.Implement (“org.apache.hadoop.hdfs.server.datanode.FSDatasetInterface”) select new {t, t.NbBCInstructions}
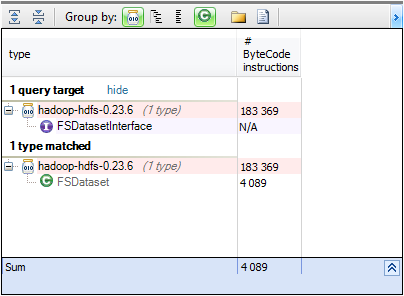
Hadoop provides FSDataset which manages a set of data blocks and store them on dirs. Using interfaces enforce low coupling and makes the design very flexible, however if the implementation is used instead of the interface we lose this advantage, and to check if interfaceDataSet is used anywhere to represent the data, let’s search for all methods using FSDataSet. from m in Methods where m.IsUsing (“org.apache.hadoop.hdfs.server.datanode.FSDataset”) select new {m, m.NbBCInstructions}
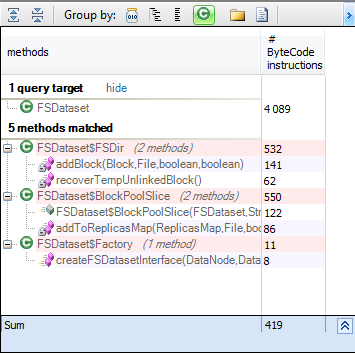
Only FSDataSet inner classes use it directly, and for all the other places the interfaceDataSet is used instead, what makes the possibility to change the dataset kind very easy. But how can I change the interfaceDataSet and give my own implementation? For that let’s search where the FSDataSet is created.
from m in Methods let depth0 = m.DepthOfCreateA(“org.apache.hadoop.hdfs.server.datanode.FSDataset”) where depth0 == 1 select new {m, depth0}

The factory pattern is used to create the instance; the problem is if this factory create the implementation directly inside getFactory method, we have to change the Hadoop code to give it our custom DataSet manager. Let’s discover which methods are used by the getFactory method. from m in Methods where m.IsUsedBy (“org.apache.hadoop.hdfs.server.datanode.FSDatasetInterface$Factory.getFactory(Configuration)”) select new {m, m.NbBCInstructions}
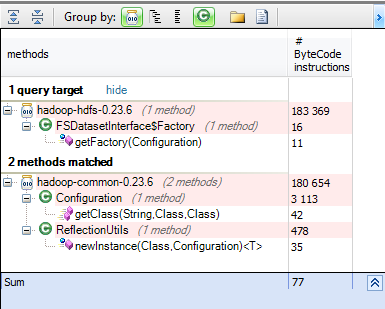
The good news is that the factory uses the Configuration to get the class implementation, so we can only by configuration gives our custom DataSet, we can also search for all classes that can be given by configuration.
from m in Methods where m.IsUsing (“org.apache.hadoop.conf.Configuration.getClass(String,Class,Class)”) select new {m, m.NbBCInstructions}
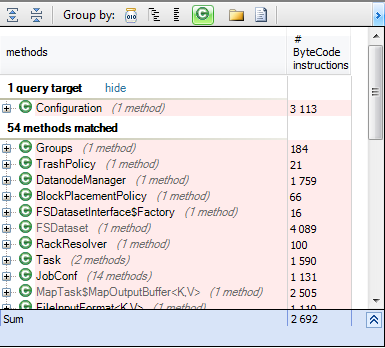
Many classes could be injected inside the Hadoop framework without changing its source code, what makes it very flexible.
NameNode
The NameNode is the arbitrator and repository for all HDFS metadata. The system is designed in such a way that user data never flows through the NameNode. Here are some methods invoked when the name node is launched.
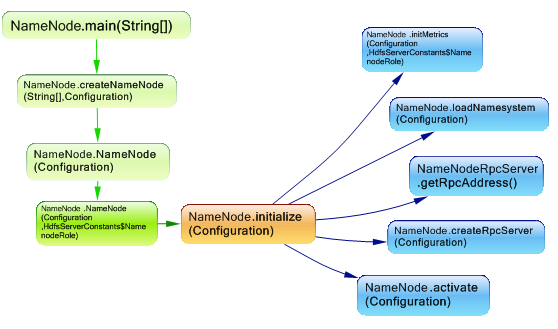
The RPC Server is created, and the fsnamesystem is loaded, here’s a quick look to these two components:
NameNodeRpcServer
NameNodeRpcServer is responsible for handling all of the RPC calls to the NameNode. For example when a data node is launched, it must register itself with the NameNode, the rpc server receive this request and forward it to fsnamesystem, which redirect it to dataNodeManager.
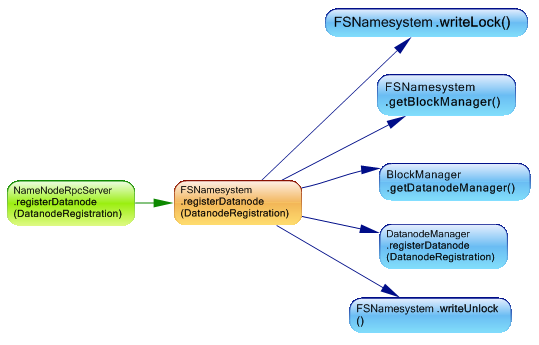
Another example is when a block of data is received. from m in Methods where m.IsUsedBy (“org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.blockReceived(DatanodeRegistration,String,Block[],String[])”) select new {m, m.NbBCInstructions}
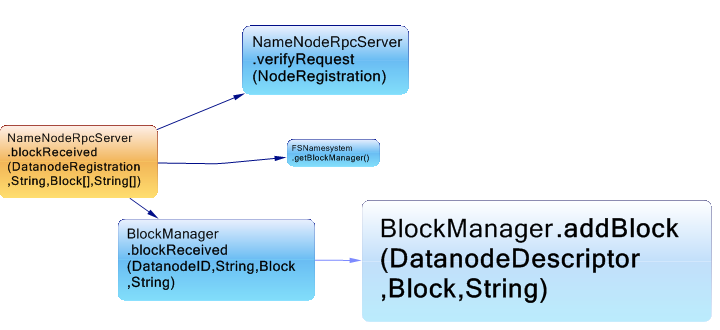
Each rectangle in the graph is proportional to the number of bytes of code instructions, and we can observe the BlockManager.addBlock do the most of the job. What’s interesting with Haddop is that each class has a specific responsibility, and any request is redirected to the corresponding manager.
FSnamesystem
HDFS supports a traditional hierarchical file organization. A user or an application can create directories and store files inside these directories. The file system namespace hierarchy is similar to most other existing file systems; one can create and remove files, move a file from one directory to another, or rename a file. For example here’s a dependency graph concerning the creation of a symbolic link.

HDFS Client
DFSClient can connect to a Hadoop Filesystem and perform basic file tasks. It uses the ClientProtocol to communicate with a NameNode daemon, and connects directly to DataNodes to read/write block data.
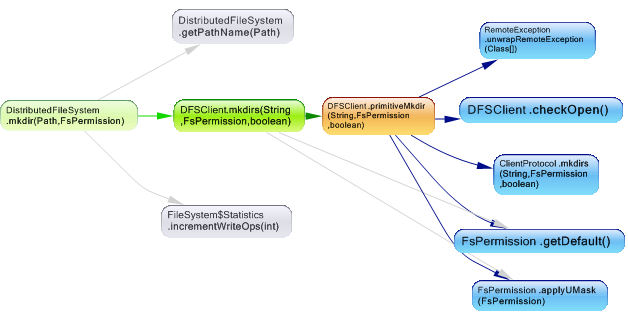
Hadoop DFS users should obtain an instance of DistributedFileSystem, which uses DFSClient to handle filesystem tasks. DistributedFileSystem act as facade and redirect requests to the DFSClient class, here’s the dependency graph concerning the creation of a directory request.
Conclusion:
Using frameworks as user is very interesting, but going inside this framework could give us more info suitable to understand it better, and adapt it to our needs easily. Hadoop is a powerful framework used by many companies, and most of them need to customize it, fortunately Hadoop is very flexible and permit us to change the behavior without changing the source code.

How do you issue these queries? Does this query language have a name?
The language used is CQLinq(http://www.jarchitect.com/Doc_CQLinq_Syntax) it’s based on Linq.