Building an application with a microservice architecture is an excellent long-term decision if you can afford the increase in upfront time investment to do it properly. Heroku provides a platform that most developers know for simple deployment, but it also dramatically simplifies microservices architecture.
What are these “microservices” of which you speak?
If you’ve been around web development before the term microservices existed, you’ll know it as Service Oriented Architecture (SOA). The biggest difference is that SOA was more generally associated with WSDL/SOAP/XML-based web services being isolated by general functionality, teams, and data access, while the general tone of microservices goes deeper. Microservices also focus on isolating applications by functionality but moreso revolve around cloud deployments, continuous delivery, scaling, agile development, and interdependency reduction.
When developing a web application, there are generally two approaches to the problem: Monolith or Microservice.
Monoliths are significantly easier and faster to build… in the beginning. Your entire application can be managed in a single IDE. All of your data lives in a single database. You can cross-query against an assortment of disparate parts to assemble reports. You can ensure data integrity by wrapping codependent inserts/updates into a single transaction that can be rolled back in the event of a failure. Your controllers can easily pull in data from different related models without the need to create an API. This type of development absolutely leads to the ability to get a lot of features out the door, very quickly.
“Monoliths are significantly easier and faster to build… in the beginning.” via @codeship
Microservices focus on taking functional sets and reducing them to many smaller applications. Smaller test suites, smaller library dependencies, smaller hosting requirements, smaller code base, smaller documentation, smaller learning curve, and easier-to-scale individual parts. The downside is that you have to develop ways for the pieces to communicate with each other, usually via REST API or shared queues, and that takes more time. Additionally, you have to be concerned about hosting each service.
Monolith vs. Microservice Tradeoffs
Let’s look at a few of the trade offs you’ll experience when choosing either a microservice or monolith architectural approach.
Dependency Interlocks
The first and most noticeable problem with monoliths is dependency locks. Ruby gems and other libraries that follow the pattern of being able to specify other gem dependencies for their own functionality will create cross compatibility issues eventually.
At the time you develop a feature, you just add the gem to your Gemfile, do a quick bundle install, and you’re off. Over time, you’ll realize that some of those gems have the same gem dependencies, and specific versions of them at that. When you want to upgrade one to get a new feature or improvement, you’ll find that you can’t because other libraries that haven’t been updated as frequently by their authors will have an incompatible version of one of its backbone libraries. You can’t upgrade one without the other. This spans from minor functionality all the way to language versions and frameworks.
With a microservice architecture, the problem is less likely to happen since the parts will be separated into different sets of library dependencies. There’s a chance the libraries in conflict won’t even be in the same service, but even if they are it reduces the scope of impact to a much smaller part of your application, instead of holding back the entire system. This makes implementing the buffalo theory on your application a lot simpler by rewriting that part of the system without the dependency, killing it off completely, or replacing it with a language that could better suit its functionality. That could mean anything from using Go for concurrency to R for data analysis, but the entire process is simplified when the parts you are replacing are smaller.
Now it can be argued that the exact same thing can be done with a monolith by creating a new service for a particular piece of functionality and having the monolith utilize it in place of the original. This approach is perfectly fine if you have a simple way to verify everywhere that dependencies are being used, every place the code being replaced is utilized, and that no other logic will be affected by removing those parts and replacing it with a service.
In my experience, verifying all of that before the new service is written and then potentially migrating data to the new service is a lot harder than it sounds… and it already sounds hard.
Hosting Challenges
Deploying and hosting your monolith is never complicated at the first commit. As it grows and grows and grows, deployments take longer, server RAM requirements increase, boot time increases, database size increases. That’s before we factor in traffic itself increasing.
Even if it’s only a small part of your application seeing a sudden boost in traffic, burst periods or server stress… it affects the whole thing. To scale it, you have to scale the whole thing with the massive server requirements that we’ve worked our way up to by this point. Want to create a new subdomain to direct certain types of calls, like API calls, so you can at least isolate the most stressful traffic? Still have to maintain the giant servers for it, and now you’ve got extra load balancers while cutting redundancy/capacity in half so that you could achieve that isolation.
Microservice hosting complexity tends to vary by the language(s) involved. If everything was done with Java, then something like the JBoss App Server could deploy multiple isolated applications as containers across a cluster, communicating with each other, distributing the load, and even distributing the background jobs. The time investment and sophistication involved with that type of setup can create infrastructure-level dependencies and investment bias. That’s because upgrading things for some services can mean investing in an entire new cluster. But for the most part, the Java world makes that easier because of backwards compatibility. There’s a reason so many languages want to run on the JVM and access to these infrastructure tools without having to develop with Java itself is one of the biggest reasons.
With Go or Node.js, it’s usually just a matter of starting things up because the servers are a part of the language.
With PHP or Perl, as long as you’re on the same version of the language, it’s simple enough to deploy hundreds of services to the same server. However, managing resources to scale them independently is more complicated.
With Ruby, deploying multiple services to the same server is more complicated and resource intensive, unless you’re leveraging something like Torquebox to get the JBoss App Server benefits via jRuby. Otherwise, standing up multiple production Ruby apps on the same virtual machine or container can become fairly taxing on the RAM.
Database Challenges
There are two schools of thought around databases in a microservice architecture. One states that each service should have its own isolated datasource. The other calls for multiple microservices to share the same database and allow the database itself to house a lot of the logic shared between applications. Neither of these are wrong… it simply depends on which parts of the application you’re talking about, and there is no reason you can’t do both where they are the best fit.
Databases like PostgreSQL make it possible for the database to do things you didn’t know a database could do AND offer several different languages for you to write that internal functionality (SQL, Javascript(V8), Python, Perl, R, etc…). That’s before you even factor in tools like LISTEN/NOTIFY for PubSub that your other services could use. Other times you’re going to have data that gains little from being interconnected, may have different I/O or caching needs, and could be better off growing independently in a specialized datasource.
The most important thing is to avoid adhering to some type of ideological architectural purity to the detriment of the best solution for your problem. Isolation is usually simpler in concept but gets significantly more complicated as you find yourself constantly caching, replicating, or syncing certain data between services to relieve stress or speed up certain parts of the system.
Where does Heroku come into all of this…exactly?
Here’s what you’re thinking in your head when you design a microservice architecture:
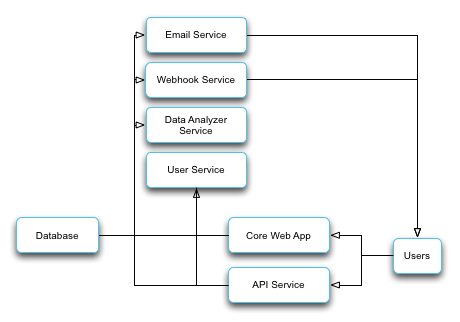
Here’s what’s actually going on:
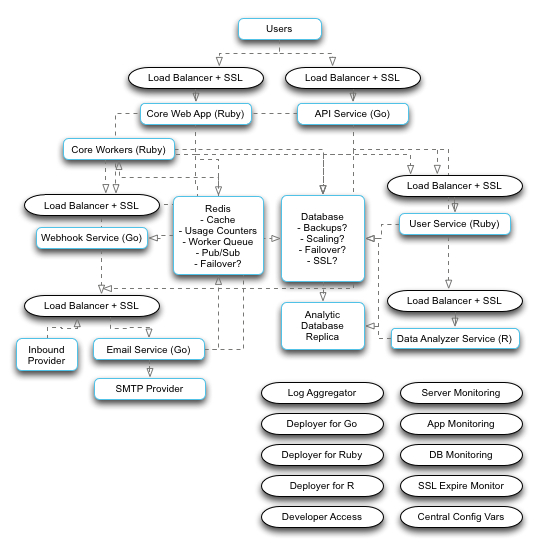
Heroku simplifies a lot of that for you by reducing common-in-theory infrastructure and deployment logic to common-in-practice infrastructure and deployment logic, while removing the language restriction of doing so.
These types of infrastructure concerns are the sort of thing you want no part in having to care about when you’re trying to get an idea to market. You’re focused on what your system is going to do, how it’s going to do it, technological constraints to solving it well, and what your services will need to talk to each other. What you’re not focused on is managing shared configuration variables across multiple services, with multiple environments, multiple deployment processes, variable amounts of servers, whether or not you need to bother with load balancers for each service right now, managing DNS entries and routing as IPs change across instances, or managing and updating secure certificates across a bunch of different subdomains for services.
Load Balancers
With Heroku’s Dyno (VM) setup, you get the ability to increase your dynos on the fly at any time and get billed by the microscopic units of time that you use them for. In order to do that with the web, your dynos are behind a load balancer. When you increase them or decrease them, the dyno is booting up, verifying success, checking in with the load balancer, and then unregistering itself when it shuts down.
If you’re setting up your own instances, you have to setup your own load balancers in front of them to prepare for this and automate the registration and deregistration process. Or just point straight to the VM and hope you don’t need to scale out.
SSL Management
Secure certificates are one of those necessary details that tend to be a headache if you have to manage them yourself. Publicly facing URLs that your users will see, such as your API and your application frontend, will absolutely require that you get your own cert, pay for it for X number of years, update it whenever it needs to be replaced, turn off certain types of encryption/handshakes based on security exploits, etc… on every server and load balancer that you have.
Within a VPC, it’s less risky to go without it behind the public URLs because the VPC is encrypting everything. But without that, you need SSL all over your cloud infrastructure. Every Heroku service gets an internal Heroku subdomain. That URL has Heroku’s SSL. You don’t have to pay extra for it, you don’t have to keep up with it, monitor its expiration, or plan on reissuing it every so often. If it’s not public facing, you can simplify your whole internal service process by just using those Heroku URLs.
Language Specific Features
Multilingual microservice architecture is an area where Heroku gives you a big win. If a company is standardized on a single language, it becomes easier for them to invest time in developing language-specific tools for deployment, server configuration, application monitoring, and configuration variables.
In many cases, configurations will just be loaded in a language file or something that’s dropped on the server and parsed with a library for the language via XML, JSON, or YAML. The biggest problem that this creates is a technology investment. Not only have you committed to the language, but you’ve also committed to tools around it which creates a barrier to other languages that don’t have access to all of the tools that you’ve invested time into perfecting.
Heroku goes a long way toward removing those investments. For deployment, regardless of language, it’s a simple:
git push heroku master
From there, Heroku receives the push, configures the dynos, loads libraries in the proper manner for each language, and then boots up the dyno. If there is a problem, rolling back the deployment follows the same rules regardless of language. For rolling restarts, you can simply turn on the preboot feature to have it start an equal number of dynos to what you had running. Then you wait for them all to boot successfully, swap out the load balancer, and kill the old dynos.
Configuration is centralized via the Heroku Config tool. It can be centrally updated and is automatically pushed to all of your dynos. There’s no need to build a tool to have them read from, push a file, and source it via SSH with a language-specific reboot, include it in a language file as part of a repo, or manage it in your database and develop logic in each language to understand it. They’re simple environment vars as far as the app is concerned, and setting, reading, writing, changing, and publishing them are all managed with a single command regardless of application language.
These aspects of the platform reduce your investment in a language or even a restriction on versions of a language that you may encounter with a vertically scaled server configuration (read, “enterprise application servers”). Upgrades can be done easily on a per-service basis. Rollbacks are consistent. Configuration is consistent. Deployment is consistent. A monolith only has one set of everything, so these aren’t usually concerns. A microservice architecture has to consider them on a per-service basis, and Heroku removes most of those decisions.
Removing the technology investment (aside from learning it) allows you to more easily select the right tool for the job at hand.
- Leverage Rails to quickly develop a full-featured web app with all of the peripheral details to handle HTML and assets smoothly.
- Use Go for high concurrency, low I/O workloads like delivering emails, sending webhooks, or throttling and passing through API requests.
- Use R for data analysis.
- Use Java for something where there’s a library that isn’t available in other languages or because you have one of those “do everything in Java” people on your team (kidding…mostly).
You get the idea. This becomes an enabler for your entire system by opening all of the technology doors that are out there.
Logs and Monitoring
Regardless of Linux version, application language, or the number of services running, Heroku aggregates all of your logs for a service into one place. You can open a log tail on the email service with 50 dynos running and see every server in one place in real time. You can integrate with third-party services to harvest, parse, and analyze your logs, or even setup your own log drain to do something with them yourself.
Heroku handles the actual dyno monitoring and response, so that becomes one less thing to worry about. Tools to do monitoring within the running application are still going to be language specific, but New Relic’s free plan makes this a lot more manageable (Heroku or otherwise).
Development/Staging Environments
Another major factor in a microservice architecture is that you have to replicate your production setup for development, UAT, or staging environments. Heroku’s free dyno plans make this a trivial issue versus replicating the entire stack on virtual machines. Just create the environments and change the configurations… done.
Developer Access
Access control for your team isn’t something that’s usually at the forefront of your mind when you start building a system. At best, you’re worried about restricting access to the production environment. With Heroku, the entire process gets easier because you’re able to add specific people to specific projects. You can give them access to the application for things like running jobs without having to provide SSH access into a server that could be exposing more than you wanted.
Number of users doesn’t cost anything. Heroku provides an interface for them to manage their own RSA/DSA keys and passwords without you have to circulate them around to different sets of servers. All those “Hey, can I get access to…” requests just become a couple of clicks in the specific environments where you want to allow them.
To Summarize
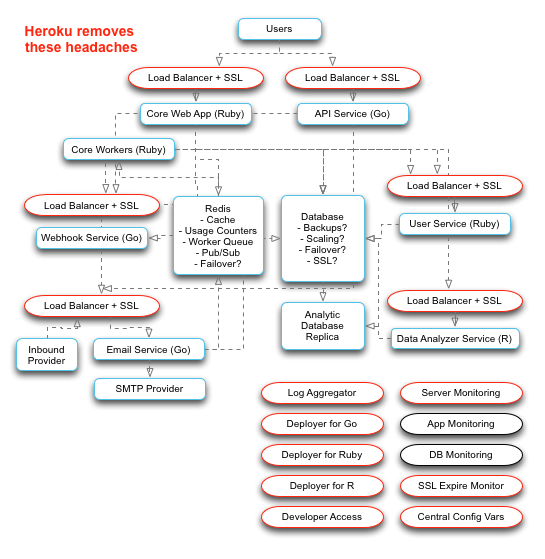
Container technologies like Docker are enabling a lot more competition in this space, but it isn’t perfect. Docker shows enough promise that Heroku is even supporting it now, while a number of major market players are pooling resources to polish the technology’s rough edges. One day, they might make this as easy as Heroku currently does, but time will tell.
Individual microservices are an ideal fit with continuous integration/delivery workflows because the smaller parts can more easily be deployed without disruption to the entire system. Taking advantage of these flows to auto-deploy to dev/staging/uat environments after builds complete successfully creates another great opportunity to grease the wheel of time in your favor.
Heroku removes most of the upfront investments involved in developing with a microservice architecture. It makes working with a virtually unlimited number of pieces fairly trivial, which is exactly what you need in order to keep track of microservices in a way that keeps you sane. Without dedicated IT staff, microservices using more than a single language can create a lot of DevOps issues, and Heroku alleviates the vast majority of those so you can focus on your application.
When using Heroku, this changes the decision-making formula between the question of monolith versus microservices. A lot of the advantages that a monolith provides in the short term are placed on more equal footing with microservices, and that should make focusing on the long term a much easier choice.
Every application and businesses requirements will vary. Which is best for your setup? What concerns do you have when making decisions on between microservice or monolith architecture?
“Exploring microservices architecture on Heroku” via @codeship
| Reference: | Exploring Microservices Architecture on Heroku from our JCG partner Barry Jones at the Codeship Blog blog. |


Typo: and JVM for serious stuff (kidding…mostly)