Let’s face it. The systems we are creating are not perfect. Sooner or later, one of our applications will fail, one of our services will not be able to handle the increased load, one of our commits will introduce a fatal bug, a piece of hardware will break, or something entirely unexpected will happen.
How do we fight the unexpected? Most of us are trying to develop a bullet proof system. We are attempting to create what no one did before. We strive for the ultimate perfection, hoping that the result will be a system that does not have any bugs, is running on hardware that never fails, and can handle any load. Here’s a tip. There is no such thing as perfection. No one is perfect, and nothing is without fault. That does not mean that we should not strive for perfection. We should, when time and resources are provided. However, we should also embrace the inevitable, and design our systems not to be perfect, but able to recuperate from failures, and able to predict likely future. We should hope for the best but prepare for the worst.
There are plenty of examples of resilient systems outside software engineering, none of them better than life itself. We can take ourselves, humanity, as an example. We’re the result of a very long experiment based on small and incremental evolutionary improvements, performed over millions of years. We can learn a lot from a human body, and apply that knowledge to our software and hardware. One of the fascinating abilities we (humans) posses is the capacity to self-heal.
Human body has an amazing capacity to heal itself. The most fundamental unit of human body is cell. Throughout our life, cells inside our body are working to bring us back to a state of equilibrium. Each cell is a dynamic, living unit that is continuously monitoring and adjusting its own processes, working to restore itself according to the original DNA code it was created with, and to maintain balance within the body. Cells have the ability to heal themselves, as well as to make new cells that replace those that have been permanently damaged or destroyed. Even when a large number of cells are destroyed, the surrounding cells replicate to make new cells, thereby quickly replacing the cells that were destroyed. This ability does not make us, individuals, immune to death, but it does make us very resilient. We are continuously attacked by viruses. We succumb to diseases and yet, in most cases, we come out victorious. However, looking at us as individuals would mean that we are missing the big picture. Even when our own lives end, the life itself not only survives, but thrives, ever growing, and ever adapting.
We can think of a computer system as a human body that consists of cells of various types. They can be hardware or software. When they are software units, the smaller they are, the easier it is for them to self-heal, recuperate from failures, multiply, or even get destroyed when that is needed. We call those small units microservices, and they can, indeed, have behaviors similar to those observed in a human body. The microservices-based system we are building can be made in a way that is can self-heal. That is not to say that self-healing we are about to explore is applicable only to microservices. It is not. However, like most other techniques we explored, self-healing can be applied to almost any type of architecture, but provides best results when combined with microservices. Just like life that consists of individuals that form a whole ecosystem, each computer system is part of something bigger. It communicates, cooperates, and adapts to other systems forming a much larger whole.
Self-Healing Levels and Types
In software systems, the self-healing term describes any application, service, or a system that can discover that it is not working correctly and, without any human intervention, make the necessary changes to restore itself to the normal or designed state. Self-healing is about making the system capable of making its decisions by continually checking and optimizing its state and automatically adapting to changing conditions. The goal is to make fault tolerant and responsive system capable of responding to changes in demand and recuperation from failures.
Self-healing systems can be divided into three levels, depending on size and type of resources we are monitoring, and acting upon. Those levels are as follows.
- Application level
- System level
- Hardware level
We’ll explore each of those three types separately.
Self-Healing on the Application Level
Application level healing is the ability of an application, or a service, to heal itself internally. Traditionally, we’re used to capturing problems through exceptions and, in most cases, logging them for further examination. When such an exception occurs, we tend to ignore it and move on (after logging), as if nothing happened, hoping for the best in the future. In other cases, we tend to stop the application if an exception of certain type occurs. An example would be a connection to a database. If the connection is not established when the application starts, we often stop the whole process. If we are a bit more experienced, we might try to repeat the attempt to connect to the database. Hopefully, those attempts are limited, or we might easily enter a never ending loop, unless database connection failure was temporary and the DB gets back online soon afterwards. With time, we got better ways to deal with problems inside applications. One of them is Akka. It’s usage of supervisor, and design patterns it promotes, allow us to create internally self-healing applications and services.
Akka is not the only one. Many other libraries and frameworks enable us to create fault tolerant applications capable of recuperation from potentially disastrous circumstances. Since we are trying to be agnostic to programming languages, I’ll leave it to you, dear reader, investigation of ways to self-heal your applications internally. Bear in mind that self-healing in this context refers to internal processes and does not provide, for example, recuperation from failed processes. Moreover, if we adopt microservices architecture, we can quickly end up with services written in different languages, using different frameworks, and so on. It is truly up to developers of each service to design it in a way that it can heal itself and recuperate from failures.
Let’s jump into the second level.
Self-Healing on the System Level
Unlike the application level healing that depends on a programming language and design patterns that we apply internally, system level self-healing can be generalized and be applied to all services and applications, independently from their internals. This is the type of self-healing that we can design on the level of the whole system. While there are many things that can happen at the system level, the two most commonly monitored aspects are failures of processes and response time. If a process fails, we need to redeploy the service, or restart the process. On the other hand, if the response time is not adequate, we need to scale, or descale, depending whether we reached upper or lower response time limits.
Recuperating from process failures is often not enough. While such actions might restore our system to the desired state, human intervention is often still needed. We need to investigate the cause of the failure, correct the design of the service, or fix a bug. That is, self-healing often goes hand in hand with investigation of the causes of that failure. The system automatically recuperates and we (humans) try to learn from those failures, and improve the system as a whole. For that reason, some kind of a notification is required as well. In both cases (failures and increased traffic), the system needs to monitor itself and take some actions.
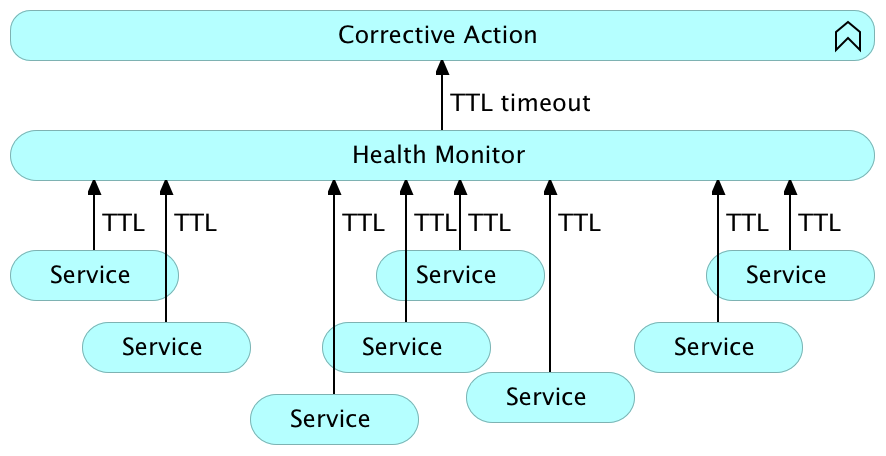
How does the system monitor itself? How does it check the status of its components? There are many ways, but two most commonly used are TTLs and pings.
Time-To-Live (TTL)
Time-to-live (TTL) checks expect a service, or an application, to periodically confirm that it is operational. The system that receives TTL signals keeps track of the last known reported state for a given TTL. If that state is not updated within a predefined period, the monitoring system assumes that the service failed and needs to be restored to its designed state. For example, a healthy service could send an HTTP request announcing that it is alive. If the process the service is running in fails, it will be incapable to send the request, TTL will expire, and reactive measures will be executed.
The main problem with TTL is coupling. Applications and services need to be tied to the monitoring system. Implementing TTL would be one of the microservices anti-patterns since we are trying to design them in a way that they are as autonomous as possible. Moreover, microservices should have a clear function and a single purpose. Implementing TTL requests inside them would add additional functionality and complicate the development.
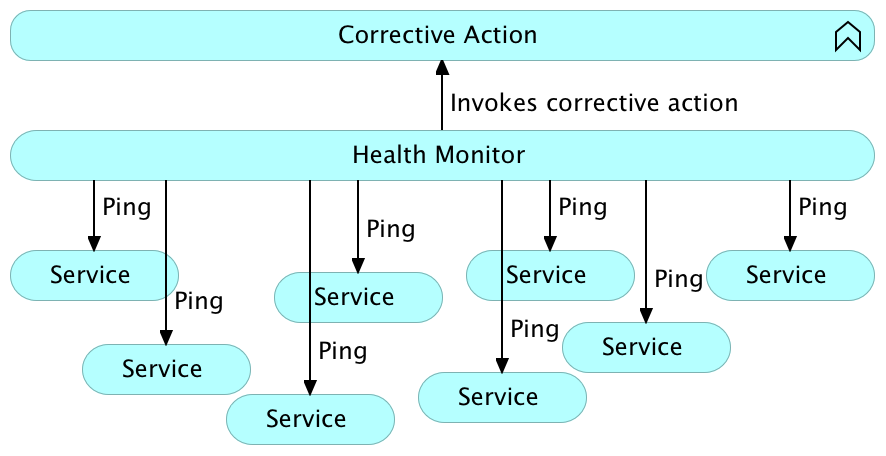
Pinging
The idea behind pinging is to check the state of an application, or a service, externally. The monitoring system should ping each service periodically and, if no response is received, or the content of the response is not adequate, execute healing measures. Pinging can come in many forms. If a service exposes HTTP API, it is often a simple request, where desired response should be HTTP status in 2XX range. In other cases, when HTTP API is not exposed, pinging can be done with a script, or any other method that can validate the state of the service.
Pinging is opposite from TTL, and, when possible, is a preferable way of checking the status of individual parts of the system. It removes repetition, coupling, and complications that could occur when implementing TTL inside each service.
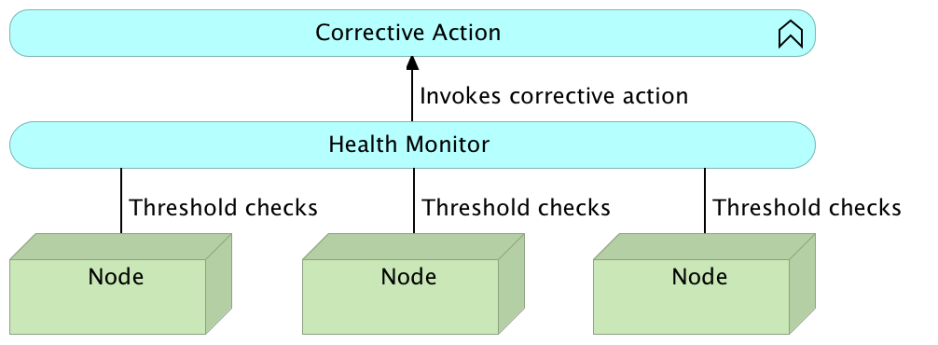
Self-Healing on the Hardware Level
Truth be told, there is no such a thing as hardware self-healing. We cannot have a process that will automatically heal failed memory, repare broken hard disk, fix malfunctioning CPU, and so on. What healing on this level truly means is redeployment of services from an unhealthy to one of the healthy nodes. As with the system level, we need to periodically check the status of different hardware components, and act accordingly. Actually, most healing caused due to hardware level will happen at the system level. If hardware is not working correctly, chances are that the service will fail, and thus be fixed by system level healing. Hardware level healing is more related to preventive types of checks that we’ll discuss shortly.
Besides the division based on the check levels, we can also divide it based on the moment actions are taken. We can react to a failure, or we can try to prevent it.
Reactive healing
Most of the organizations that implemented some kind of self-healing systems focused on reactive healing. After a failure is detected, the system reacts and restores itself to the designed state. A service process is dead, ping returns the code 404 (not found), corrective actions are taken, and the service is operational again. This works no matter whether service failed because its process failed, or the whole node stopped being operational (assuming that we have a system that can redeploy to a healthy node). This is the most important type of healing and, at the same time, the easiest one to implement. As long as we have all the checks in place, as well as actions that should be performed in case of a failure, and we have each service scaled to at least two instances distributed on separate physical nodes, we should (almost) never have downtime. I said almost never because, for example, the whole datacenter might loose power, thus stopping all nodes. It’s all about evaluating risks against costs of preventing those risks. Sometimes, it is worthwhile to have two datacenters in different locations, and in other cases it’s not. The objective is to strive towards zero-downtime, while accepting that some cases are not worthwhile trying to prevent.
No matter whether we are striving for zero-downtime, or almost zero-downtime, reactive self-healing should be a must for any but smallest settings, especially since it does not require big investment. You might invest in spare hardware, or you might invest in separate datacenters. Those decisions are not directly related with self-healing, but with the level of risks that are acceptable for a given use case. Reactive self-healing investment is primarily in knowledge how to do it, and time to implement it. While time is an investment in itself, we can spend it wisely, and create a general solution that would work for (almost) all cases, thus reducing the time we need to spend implementing such a system.
Preventive healing
The idea behind preventive healing is to predict the problems we might have in the future, and act in a way that those problems are avoided. How do we predict the future? To be more precise, what data do we use to predict the future?
Relatively easy, but less reliable way of predicting the future, is to base assumptions on (near) real-time data. For example, if one of the HTTP requests we’re using to check the health of a service responded in more than 500 milliseconds, we might want to scale that service. We can even do the opposite. Following the same example, if it took less than 100 milliseconds to receive the response, we might want to descale the service, and reassign those resources to another one that might need it more. The problem with taking into account the current status when predicting the future is variability. If it took a long time between the request and the response, it might indeed be the sign that scaling is needed, but it might also be a temporary increase in traffic, and the next check (after the traffic spike is gone) will deduce that there is a need to descale. If microservices architecture is applied, this can be a minor issue, since they are small and easy to move around. They are easy to scale, and descale. Monolithic applications are often much more problematic if this strategy is chosen.
If historical data is taken into account, preventive healing becomes much more reliable but, at the same time, much more complicated to implement. Information (response times, CPU, memory, and so on) needs to be stored somewhere and, often complex, algorithms need to be employed to evaluate tendencies, and make conclusions. For example, we might observe that, during the last hour, memory usage has been steadily increasing, and that it reached a critical point of, let’s say, 90%. That would be a clear indication that the service that is causing that increase needs to be scaled. The system could also take into account longer period of time, and deduce that every Monday there is a sudden increase in traffic, and scale services well in advance to prevent long responses. What would be, for example, the meaning of a steady increase in memory usage from the moment a service is deployed, and sudden decrease when a new version is released? Probably memory leaks and, in such a case, the system would need to restart the application when certain threshold is reached, and hope that developers would fix the issue (hence the need for notifications).
The DevOps 2.0 Toolkit
 This post is a copy of the beginning of the Self-Healing Systems chapter of The DevOps 2.0 Toolkit: Automating the Continuous Deployment Pipeline with Containerized Microservices book. The chapter continues exploring self-healing architecture. Provides hands-on examples of setting up self-healing with Docker, Consul Watches, and Jenkins for monitoring both hardware and deployed services. That is followed by a discussion and examples of setting up preventive healing through scheduled scaling and descaling. Moreover, the chapter is only the first part of the subject study, that will be continued after the exploration of centralized logging and collection and storage of historical data required for more advanced self-healing use cases.
This post is a copy of the beginning of the Self-Healing Systems chapter of The DevOps 2.0 Toolkit: Automating the Continuous Deployment Pipeline with Containerized Microservices book. The chapter continues exploring self-healing architecture. Provides hands-on examples of setting up self-healing with Docker, Consul Watches, and Jenkins for monitoring both hardware and deployed services. That is followed by a discussion and examples of setting up preventive healing through scheduled scaling and descaling. Moreover, the chapter is only the first part of the subject study, that will be continued after the exploration of centralized logging and collection and storage of historical data required for more advanced self-healing use cases.
This book is about different techniques that help us architect software in a better and more efficient way with microservices packed as immutable containers, tested and deployed continuously to servers that are automatically provisioned with configuration management tools. It’s about fast, reliable and continuous deployments with zero-downtime and ability to roll-back. It’s about scaling to any number of servers, design of self-healing systems capable of recuperation from both hardware and software failures and about centralized logging and monitoring of the cluster.
In other words, this book envelops the whole microservices development and deployment lifecycle using some of the latest and greatest practices and tools. We’ll use Docker, Kubernetes, Ansible, Ubuntu, Docker Swarm and Docker Compose, Consul, etcd, Registrator, confd, Jenkins, and so on. We’ll go through many practices and, even more, tools.
Give the book a try and let me know what you think.
| Reference: | Self-Healing Systems from our JCG partner Viktor Farcic at the Technology conversations blog. |
