Hibernate, as stated at the official “about” page of the product, is a high-performance Object/Relational persistence and query service. The most flexible and powerful Object/Relational solution on the market, Hibernate takes care of the mapping from Java classes to database tables and from Java data types to SQL data types. It provides data query and retrieval facilities that significantly reduce development time.
For the purpose of this article we will use the aforementioned, well known, products as the actual implementations of the persistence API. Our goal is to be able to compare their performance when applying CRUD (Create – Retrieve – Update – Delete) operations against a database.
To do so, we are going to implement two distinct Spring based WEB applications that will act as our “test bases”. The two applications will be identical in terms of their service and data access layer definitions – interfaces and implementation classes. For data access we will utilize JPA2 as the Java Persistence API. For the database we will use an embedded Derby instance. Last but not least we are going to implement and perform the same suit of performance tests against the five “basic” data access operations described below :
- Persist a record
- Retrieve a record by its ID
- Retrieve all records
- Update an existing record
- Delete a record
All tests are performed against a Sony Vaio with the following characteristics :
- System : openSUSE 11.1 (x86_64)
- Processor (CPU) : Intel(R) Core(TM)2 Duo CPU T6670 @ 2.20GHz
- Processor Speed : 1,200.00 MHz
- Total memory (RAM) : 2.8 GB
- Java : OpenJDK 1.6.0_0 64-Bit
The following tools are used :
- Spring framework 3.0.1
- Apache Derby 10.6.1.0
- Hibernate 3.5.1
- DataNucleus 3.0.0-m1
- c3p0 0.9.1.2
- Java Benchmarking framework from Brent Boyer
Final notices :
- You can download the full source code for the two “test bases” here and here. These are Eclipse – Maven based projects.
- In order to be able to compile and run the tests yourself you will need to install the Java Benchmarking framework binary – jar files to your Maven repository. Alternatively, as a “one click” solution, you may use the Java Benchmarking Maven bundle created by us. You can download it from here, unzip it to your Maven repository and you are good to go.
The “test bases” …
We will start by providing information on how we have implemented the “test base” projects. This is imperative in order to be crystal clear about the specifics of the environment our tests will run against. As previously stated, we have implemented two multi-tier Spring based WEB applications. In each application two layers have been implemented, the Service Layer and the Data Access Layer. These layers have identical definitions – interfaces and implementation specifics.
Our domain model consists of just an “Employee” object. The Service Layer provides a trivial “business” service that exposes CRUD (Create – Retrieve – Update – Delete) functionality for the “Employee” object whereas the Data Access Layer consists of a trivial Data Access Object that utilizes Spring JpaDaoSupport abstraction in order to provide the actual interoperability with the database.
Below are the Data Access Layer specific classes :
import javax.annotation.PostConstruct;
import javax.persistence.EntityManagerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;
import com.javacodegeeks.springdatanucleus.dto.EmployeeDTO;
@Repository("employeeDAO")
public class EmployeeDAO extends JpaDAO<Long, EmployeeDTO> {
@Autowired
EntityManagerFactory entityManagerFactory;
@PostConstruct
public void init() {
super.setEntityManagerFactory(entityManagerFactory);
}
}
As you can see our Data Access Object (DAO) extends the JpaDAO class. This class is presented below :
import java.lang.reflect.ParameterizedType;
import java.util.List;
import javax.persistence.EntityManager;
import javax.persistence.PersistenceException;
import javax.persistence.Query;
import org.springframework.orm.jpa.JpaCallback;
import org.springframework.orm.jpa.support.JpaDaoSupport;
public abstract class JpaDAO<K, E> extends JpaDaoSupport {
protected Class<E> entityClass;
@SuppressWarnings("unchecked")
public JpaDAO() {
ParameterizedType genericSuperclass = (ParameterizedType) getClass()
.getGenericSuperclass();
this.entityClass = (Class<E>) genericSuperclass
.getActualTypeArguments()[1];
}
public void persist(E entity) {
getJpaTemplate().persist(entity);
}
public void remove(E entity) {
getJpaTemplate().remove(entity);
}
public E merge(E entity) {
return getJpaTemplate().merge(entity);
}
public void refresh(E entity) {
getJpaTemplate().refresh(entity);
}
public E findById(K id) {
return getJpaTemplate().find(entityClass, id);
}
public E flush(E entity) {
getJpaTemplate().flush();
return entity;
}
@SuppressWarnings("unchecked")
public List<E> findAll() {
Object res = getJpaTemplate().execute(new JpaCallback() {
public Object doInJpa(EntityManager em) throws PersistenceException {
Query q = em.createQuery("SELECT h FROM " +
entityClass.getName() + " h");
return q.getResultList();
}
});
return (List<E>) res;
}
@SuppressWarnings("unchecked")
public Integer removeAll() {
return (Integer) getJpaTemplate().execute(new JpaCallback() {
public Object doInJpa(EntityManager em) throws PersistenceException {
Query q = em.createQuery("DELETE FROM " +
entityClass.getName() + " h");
return q.executeUpdate();
}
});
}
}
Following is our domain class, the EmployeeDTO class :
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name = "EMPLOYEE")
public class EmployeeDTO implements java.io.Serializable {
private static final long serialVersionUID = 7440297955003302414L;
@Id
@Column(name="employee_id")
private long employeeId;
@Column(name="employee_name", nullable = false, length=30)
private String employeeName;
@Column(name="employee_surname", nullable = false, length=30)
private String employeeSurname;
@Column(name="job", length=50)
private String job;
public EmployeeDTO() {
}
public EmployeeDTO(int employeeId) {
this.employeeId = employeeId;
}
public EmployeeDTO(long employeeId, String employeeName, String employeeSurname,
String job) {
this.employeeId = employeeId;
this.employeeName = employeeName;
this.employeeSurname = employeeSurname;
this.job = job;
}
public long getEmployeeId() {
return employeeId;
}
public void setEmployeeId(long employeeId) {
this.employeeId = employeeId;
}
public String getEmployeeName() {
return employeeName;
}
public void setEmployeeName(String employeeName) {
this.employeeName = employeeName;
}
public String getEmployeeSurname() {
return employeeSurname;
}
public void setEmployeeSurname(String employeeSurname) {
this.employeeSurname = employeeSurname;
}
public String getJob() {
return job;
}
public void setJob(String job) {
this.job = job;
}
}
Last but not least the “business” service interface and implementation classes are presented below :
import java.util.List;
import com.javacodegeeks.springdatanucleus.dto.EmployeeDTO;
public interface EmployeeService {
public EmployeeDTO findEmployee(long employeeId);
public List<EmployeeDTO> findAllEmployees();
public void saveEmployee(long employeeId, String name, String surname, String jobDescription) throws Exception;
public void updateEmployee(long employeeId, String name, String surname, String jobDescription) throws Exception;
public void saveOrUpdateEmployee(long employeeId, String name, String surname, String jobDescription) throws Exception;
public void deleteEmployee(long employeeId) throws Exception;
}
import java.util.List;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Propagation;
import org.springframework.transaction.annotation.Transactional;
import com.javacodegeeks.springdatanucleus.dao.EmployeeDAO;
import com.javacodegeeks.springdatanucleus.dto.EmployeeDTO;
import com.javacodegeeks.springdatanucleus.services.EmployeeService;
@Service("employeeService")
public class EmployeeServiceImpl implements EmployeeService {
@Autowired
private EmployeeDAO employeeDAO;
@PostConstruct
public void init() throws Exception {
}
@PreDestroy
public void destroy() {
}
public EmployeeDTO findEmployee(long employeeId) {
return employeeDAO.findById(employeeId);
}
public List<EmployeeDTO> findAllEmployees() {
return employeeDAO.findAll();
}
@Transactional(propagation=Propagation.REQUIRED, rollbackFor=Exception.class)
public void saveEmployee(long employeeId, String name, String surname, String jobDescription) throws Exception {
EmployeeDTO employeeDTO = employeeDAO.findById(employeeId);
if(employeeDTO == null) {
employeeDTO = new EmployeeDTO(employeeId, name,surname, jobDescription);
employeeDAO.persist(employeeDTO);
}
}
@Transactional(propagation=Propagation.REQUIRED, rollbackFor=Exception.class)
public void updateEmployee(long employeeId, String name, String surname, String jobDescription) throws Exception {
EmployeeDTO employeeDTO = employeeDAO.findById(employeeId);
if(employeeDTO != null) {
employeeDTO.setEmployeeName(name);
employeeDTO.setEmployeeSurname(surname);
employeeDTO.setJob(jobDescription);
}
}
@Transactional(propagation=Propagation.REQUIRED, rollbackFor=Exception.class)
public void deleteEmployee(long employeeId) throws Exception {
EmployeeDTO employeeDTO = employeeDAO.findById(employeeId);
if(employeeDTO != null)
employeeDAO.remove(employeeDTO);
}
@Transactional(propagation=Propagation.REQUIRED, rollbackFor=Exception.class)
public void saveOrUpdateEmployee(long employeeId, String name, String surname, String jobDescription) throws Exception {
EmployeeDTO employeeDTO = new EmployeeDTO(employeeId, name,surname, jobDescription);
employeeDAO.merge(employeeDTO);
}
}
What follows is the “applicationContext.xml” file that drives the Spring IoC container. The contents of this file is also identical between the two “test base” projects.
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:context="http://www.springframework.org/schema/context" xmlns:jee="http://www.springframework.org/schema/jee" xmlns:tx="http://www.springframework.org/schema/tx" xmlns:task="http://www.springframework.org/schema/task" xsi:schemaLocation=" http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-3.0.xsd http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.0.xsd http://www.springframework.org/schema/jee http://www.springframework.org/schema/jee/spring-jee-3.0.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-3.0.xsd http://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task-3.0.xsd"> <context:component-scan base-package="com.javacodegeeks.springdatanucleus" /> <tx:annotation-driven /> <bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalEntityManagerFactoryBean"> <property name="persistenceUnitName" value="MyPersistenceUnit" /> </bean> <bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager"> <property name="entityManagerFactory" ref="entityManagerFactory" /> </bean> </beans>
To be able to launch the Spring application from a Servlet container (do not forget that we have implemented Spring based WEB applications) we have included the following listener into the “web.xml” file for both our “test base” applications :
<listener> <listener-class>org.springframework.web.context.ContextLoaderListener</listener-class> </listener>
The only file that is different between the two “test base” projects is the one that defines the actual implementation of the Java Persistent API (JPA) to be used – the “persistence.xml” file. Below is the one that we have used to utilize DataNucleus Access Platform :
<persistence xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd" version="2.0"> <persistence-unit name="MyPersistenceUnit" transaction-type="RESOURCE_LOCAL"> <provider>org.datanucleus.api.jpa.PersistenceProviderImpl</provider> <class>com.javacodegeeks.springdatanucleus.dto.EmployeeDTO</class> <exclude-unlisted-classes>true</exclude-unlisted-classes> <properties> <property name="datanucleus.storeManagerType" value="rdbms"/> <property name="datanucleus.ConnectionDriverName" value="org.apache.derby.jdbc.EmbeddedDriver"/> <property name="datanucleus.ConnectionURL" value="jdbc:derby:runtime;create=true"/> <!-- <property name="datanucleus.ConnectionUserName" value=""/> <property name="datanucleus.ConnectionPassword" value=""/> --> <property name="datanucleus.autoCreateSchema" value="true"/> <property name="datanucleus.validateTables" value="false"/> <property name="datanucleus.validateConstraints" value="false"/> <property name="datanucleus.connectionPoolingType" value="C3P0"/> <property name="datanucleus.connectionPool.minPoolSize" value="5" /> <property name="datanucleus.connectionPool.initialPoolSize" value="5" /> <property name="datanucleus.connectionPool.maxPoolSize" value="20" /> <property name="datanucleus.connectionPool.maxStatements" value="50" /> </properties> </persistence-unit> </persistence>
What follows is the “persistence.xml” file that we have used to utilize Hibernate as our JPA2 implementation framework :
<persistence xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd" version="2.0"> <persistence-unit name="MyPersistenceUnit" transaction-type="RESOURCE_LOCAL"> <provider>org.hibernate.ejb.hibernatePersistence</provider> <class>com.javacodegeeks.springhibernate.dto.EmployeeDTO</class> <exclude-unlisted-classes>true</exclude-unlisted-classes> <properties> <property name="hibernate.hbm2ddl.auto" value="update" /> <property name="hibernate.show_sql" value="false" /> <property name="hibernate.dialect" value="org.hibernate.dialect.DerbyDialect" /> <property name="hibernate.connection.driver_class" value="org.apache.derby.jdbc.EmbeddedDriver" /> <property name="hibernate.connection.url" value="jdbc:derby:runtime;create=true" /> <!-- <property name="hibernate.connection.username" value="" /> <property name="hibernate.connection.password" value="" /> --> <property name="hibernate.c3p0.min_size" value="5" /> <property name="hibernate.c3p0.max_size" value="20" /> <property name="hibernate.c3p0.timeout" value="300" /> <property name="hibernate.c3p0.max_statements" value="50" /> <property name="hibernate.c3p0.idle_test_period" value="3000" /> </properties> </persistence-unit> </persistence>
Finally we demonstrate the class that implements all test cases to be executed. This class is identical for both the “test base” projects :
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.assertNotNull;
import static org.junit.Assert.assertNull;
import static org.junit.Assert.fail;
import java.util.List;
import java.util.concurrent.Callable;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import bb.util.Benchmark;
import com.javacodegeeks.springhibernate.dto.EmployeeDTO;
import com.javacodegeeks.springhibernate.services.EmployeeService;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations={"file:src/main/webapp/WEB-INF/applicationContext.xml"})
public class EmployeeServiceTest {
@Autowired
EmployeeService employeeService;
@Test
public void testSaveEmployee() {
try {
employeeService.saveEmployee(1, "byron", "kiourtzoglou", "master software engineer");
employeeService.saveEmployee(2, "ilias", "tsagklis", "senior software engineer");
} catch (Exception e) {
fail(e.getMessage());
}
}
@Test
public void testFindEmployee() {
assertNotNull(employeeService.findEmployee(1));
}
@Test
public void testFindAllEmployees() {
assertEquals(employeeService.findAllEmployees().size(), 2);
}
@Test
public void testUpdateEmployee() {
try {
employeeService.updateEmployee(1, "panagiotis", "paterakis", "senior software engineer");
assertEquals(employeeService.findEmployee(1).getEmployeeName(), "panagiotis");
} catch (Exception e) {
fail(e.getMessage());
}
}
@Test
public void testDeleteEmployee() {
try {
employeeService.deleteEmployee(1);
assertNull(employeeService.findEmployee(1));
} catch (Exception e) {
fail(e.getMessage());
}
}
@Test
public void testSaveOrUpdateEmployee() {
try {
employeeService.saveOrUpdateEmployee(1, "byron", "kiourtzoglou", "master software engineer");
assertEquals(employeeService.findEmployee(1).getEmployeeName(), "byron");
} catch (Exception e) {
fail(e.getMessage());
}
}
@Test
public void stressTestSaveEmployee() {
Callable<Integer> task = new Callable<Integer>() {
public Integer call() throws Exception {
int i;
for(i = 3;i < 2048; i++) {
employeeService.saveEmployee(i, "name-" + i, "surname-" + i, "developer-" + i);
}
return i;
}
};
try {
System.out.println("saveEmployee(...): " + new Benchmark(task, false, 2045));
} catch (Exception e) {
fail(e.getMessage());
}
assertNotNull(employeeService.findEmployee(1024));
}
@Test
public void stressTestFindEmployee() {
Callable<Integer> task = new Callable<Integer>() {
public Integer call() {
int i;
for(i = 1;i < 2048; i++) {
employeeService.findEmployee(i);
}
return i;
}
};
try {
System.out.println("findEmployee(...): " + new Benchmark(task, 2047));
} catch (Exception e) {
fail(e.getMessage());
}
}
@Test
public void stressTestFindAllEmployees() {
Callable<List<EmployeeDTO>> task = new Callable<List<EmployeeDTO>>() {
public List<EmployeeDTO> call() {
return employeeService.findAllEmployees();
}
};
try {
System.out.println("findAllEmployees(): " + new Benchmark(task));
} catch (Exception e) {
fail(e.getMessage());
}
}
@Test
public void stressTestUpdateEmployee() {
Callable<Integer> task = new Callable<Integer>() {
public Integer call() throws Exception {
int i;
for(i=1;i<2048;i++) {
employeeService.updateEmployee(i, "new_name-" + i, "new_surname-" + i, "new_developer-" + i);
}
return i;
}
};
try {
System.out.println("updateEmployee(...): " + new Benchmark(task, false, 2047));
} catch (Exception e) {
fail(e.getMessage());
}
assertEquals("new_name-1", employeeService.findEmployee(1).getEmployeeName());
}
@Test
public void stressTestDeleteEmployee() {
Callable<Integer> task = new Callable<Integer>() {
public Integer call() throws Exception {
int i;
for(i = 1;i < 2048; i++) {
employeeService.deleteEmployee(i);
}
return i;
}
};
try {
System.out.println("deleteEmployee(...): " + new Benchmark(task, false, 2047));
} catch (Exception e) {
fail(e.getMessage());
}
assertEquals(true, employeeService.findAllEmployees().isEmpty());
}
}
The results …
All test results are presented in the graph below. The vertical axis represents the mean execution time for each test in microseconds (us) thus lower values are better. The horizontal axis represents the test types. As you can see from the test cases presented above, we insert a total number of 2047 “employee” records to the database. For the retrieval test cases (findEmployee(…) and findAllEmployees(…)) the benchmarking framework performed 60 repeats of each test case in order to calculate statistics. All other test cases are executed just once.
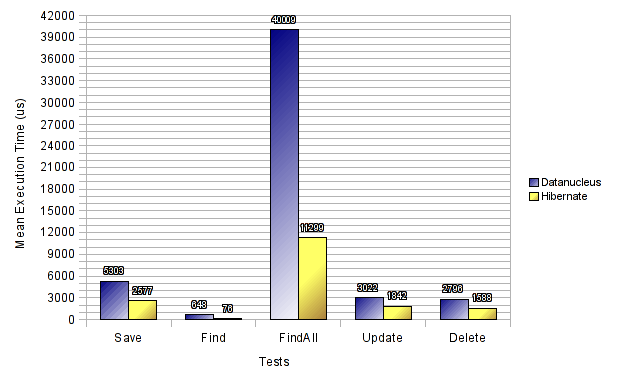
As you can see, Hibernate outperforms DataNucleus in every test case. Especially in the retrieval by ID (Find) scenario Hibernate is almost 9 times faster than DataNucleus!
To my opinion DataNucleus is a fine platform. It can be used when you want to handle data in all of its forms, wherever it is stored. This goes from persistence of data into heterogeneous data-stores, to providing methods of retrieval using a range of query languages.
The main advantage of using such a versatile platform to manage your application data, is that you don’t need to take significant time in learning the oddities of particular data-stores, or query languages. Additionally you can use a single common interface for all of your data, thus your team can concentrate their application development time on adding business logic and let DataNucleus take care of data management issues.
On the other hand versatility comes to a cost. Being a “hard-core” Object to Relational Mapping (ORM) framework, Hibernate easily outperformed DataNucleus in all of our ORM tests.
Like most of the time, its up to the application architect to decide what best suits his needs – versatility or performance, until the DataNucleus team evolve their product to the point where it can excel Hibernate that is ;-)
Happy coding and do not forget to share!
Byron
Related Articles:

So you take some “milestone” release (i.e subject to major refactoring … this is milestone 1 also so even more so), don’t bother configuring it, and then compare it to the JPA implementation you have experience with and decide something.
Doesn’t strike me as a very intelligent comparison.
As for the “idea” of drawing wideranging conclusions based on very limited operations, well you won’t be coming anywhere near my projects with that mantra
well, neil – byron has done something and contributed from his side – even if it is not to someone’s expectations; and anyone interested to take it further with any kind of combinations in testing scenarios, can do so which will be a contribution like byron did.
i wud say that the demoralizing comments that you have put is in no way that suits a professional…..
Well “NAbeel”, I made suitable points about the validity of such a comparison, which in turn should be used to improve any such comparison between any comparable pieces of software. That is what a “professional” is supposed to do, rather than blindly taking what is “presented” on such sites without questioning. Obviously, if you had a valid comment to make on how you think such a comparison should impact on what a project does, how you think performance of an ORM layer would be significant (compared to the other aspects involved in a system), etc … then we could have… Read more »