According to Wikipedia, Parallelism is the ‘simultaneous execution of some combination of multiple instances of programmed instructions and data on multiple processors’ and Java has classes and interfaces to achieve this (sort of…) since DAY 1. You may know them as: java.lang.Thread, java.lang.Runnable, etc… What Concurrency Utilities ( java.util.concurrent package) does is simplify the way we code concurrent tasks, so our code is much simpler and cleaner. As developers we haven’t had to do anything when running our applications in machines with higher processing resources, obviously, the performance of our applications will improve, but are we really using the processing resources to the maximum? The answer is big NO.
This post will show you how the Fork/Join framework will help us in using the processing resources to the maximum when dealing with problems that can be divided into small problems and all the solutions to each one of those small problems produce the solution of the big problem (like recursion, divide and conquer).
What you need
NetBeans 7+ or any other IDE that supports Java 7 JDK 7+
Blur on an image, example from Oracle
The Basics
The Fork/Join framework focuses on using all the processing resources available in the machine to improve the performance of the applications. It was designed to simplify parallelism in Divide and Conquer algorithms. The magic behind the Fork/Join framework is its work-stealing algorithm in which work threads that are free steal tasks from other busy threads, so all threads are working at all times. Following are the basics you should know in order to start using the framework:
- Fork means splitting the task into subtasks and work on them.
- Join means merging the solution of every subtask into one general solution.
- java.lang.Runtime use this class in order to obtain the number of processors available to the Java virtual machine. Use the method +availableProcessors():int in order to do so.
- java.util.concurrent.ForkJoinPool Main class of the framework, is the one that implements the work-stealing algorithm and is responsible for running the tasks.
- java.util.concurrent.ForkJoinTask Abstract class for the tasks that run in a java.util.concurrent.ForkJoinPool. Understand a task as a portion of the whole work, for example, if you need to to do something on an array, one task can work on positions 0 to n/2 and another task can work on positions (n/2) +1 to n-1, where n is the length of the array.
- java.util.concurrent.RecursiveAction Subclass of the abstract task class, use it when you don’t need the task to return a result, for example, when the task works on positions of an array, it doesn’t return anything because it worked on the array. The method you should implement in order to do the job is compute():void, notice the void return.
- java.util.concurrent.RecursiveTask Subclass of the abstract task class, use it when your tasks return a result. For example, when computing Fibonacci numbers, each task must return the number it computed in order to join them and obtain the general solution. The method you should implement in order to do the job is compute():V, where V is the type of return; for the Fibonacci example, V may be java.lang.Integer.
When using the framework, you should define a flag that indicates whether it is necessary to fork/join the tasks or whether you should compute the work directly. For example, when working on an array, you may specify that if the length of the array is bigger than 500_000_000 you should fork/join the tasks, otherwise, the array is small enough to compute directly. In essence, the algorithm you should follow is shown next:
1 2 3 4 5 6 7 8 9 | if(the job is small enough){ compute directly}else{ split the work in two pieces (fork) invoke the pieces and join the results (join)} |
OK, too much theory for now, let’s review an example.
The Example
Blurring an image requires to work on every pixel of the image. If the image is big enough we are going to have a big array of pixels to work on and so we can use fork/join to work on them and use the processing resources to the maximum. You can download the source code from the Java™ Tutorials site.
Once you download the source code, open NetBeans IDE 7.x and create a new project:

Then select Java Project with Existing Sources from the Java category in the displayed pop-up window:

Select a name and a project folder and click Next >

Now, select the folder where you downloaded the source code for the Blur on an image example:
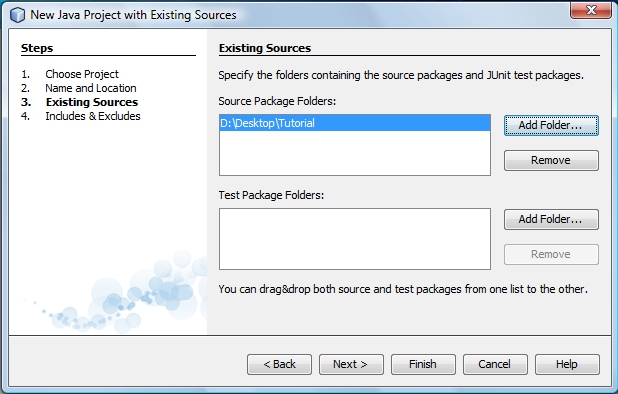
And select the file ForkBlur.java then click finish:

The source code will be imported and a new project will be created. Notice that the new project is shown with erros, this is because Java 7 is not enable for default:

To fix this, right click on the project name and select the option Properties. On the pop-up dialog, go to Libraries and select JDK 1.7 from the Java Platform ComboBox:

Now, go to the option Sources and select JDK 7 from the Source/Binary Format ComboBox:

Last but not least, increase the memory assigned to the virtual machine when running this application as we’ll be accessing a 5 million positions array (or more). Go to the option Run and insert -Xms1024m -Xmx1024m on the VM Options TextBox:

Click OK and your project should be compiling with no errors. Now, we need to find an image bigger enough so we can have a large array to work on. After a while, I found some great images (around 150 MB) from planet Mars, thanks to the curiosity robot, you can download yours from here. Once you download the image, past it on the project’s folder.
Before we run the example, we need to modify the source code in order to control when to run it using the Fork/Join framework. In the ForkBlur.java file, go to line 104 in order to change the name of the image that we are going to use:
1 2 3 | //Change for the name of the image you pasted //on the project's folder.String filename = 'red-tulips.jpg'; |
Then, replace lines 130 to 136 with the following piece of code:
01 02 03 04 05 06 07 08 09 10 11 | ForkBlur fb = new ForkBlur(src, 0, src.length, dst); boolean computeDirectly = true; long startTime = System.currentTimeMillis(); if (computeDirectly) { fb.computeDirectly(); } else { ForkJoinPool pool = new ForkJoinPool(); pool.invoke(fb); } long endTime = System.currentTimeMillis(); |
Notice the computeDirectly flag. When true, we’ll NOT be using the fork/Join Framework, instead we will compute the task directly. When false, the fork/join framework will be used.
The compute():void method in the ForkBlur class implements the fork/join algorithm. It’s based on the length of the array, when the length of the array is bigger than 10_000, the task will be forked, otherwise, the task will be computed directly.
Following you can see my 2 processors when executing the Blur on an image example without using the Fork/Join framework ( computeDirectly = true), it took about 14s to finish the work:

You can see that the processors are working, but not to the maximum. When using the Fork/Join framework ( computeDirectly = false) you can see them working at 100% and it took almost 50% less time to finish the work:

This video shows the complete process:
I hope you can see how useful this framework is. Of course, you cannot use it all around your code, but whenever you have a task that can be divided into small tasks then you know who to call.
Reference: Java 7: Meet the Fork/Join Framework from our JCG partner Alexis Lopez at the Java and ME blog.

11 screenshots explaining how to create a project in NetBeans and almost no code in an article about Fork/Join pool?