
What is Lucene?
Apache LuceneTM is a high-performance, full-featured text search engine library written entirely in Java. It is a technology suitable for nearly any application that requires full-text search, especially cross-platform.
Lucene can plain text, integers, index PDF, Office Documents. etc.,
How Lucene enables Faster Search?
Lucence creates something called Inverted Index. Normally we map document -> terms in the document. But, Lucene does the reverse. Creates a index term -> list of documents containing the term, which makes it faster to search.
Install Lucene
Maven Dependency
1 2 3 4 5 6 7 | <pre class='brush:xml'><dependency> <groupid>org.apache.lucene</groupid> <artifactid>lucene-core</artifactid> <version>3.0.2</version> <type>jar</type> <scope>compile</scope></dependency> |
Download Dependency
Download Lucene from http://lucene.apache.org/ and add the lucene-core.jar in the classpath
How does Lucene Work?
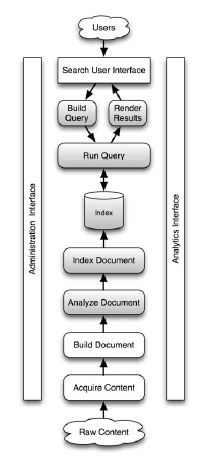
Let’s understand the picture first from bottom – Center. The Raw Text is used to create a Lucene ‘Document’ which is analyzed using the specified Analyzer and Document is added to the index based on the Store, TermVector and Analzed property of the Fields.
Next, the search from top to center. The users specify the query in a text format. The query Object is build based on the query text and the result of the executed query is returned as TopDocs.
Core Lucene Classes
| Directory, FSDirectory, RAMDirectory | Directory containing Index File system based index dir Memory based index dir | Directory indexDirectory = FSDirectory.open(new File(‘c://lucene//nodes’)); |
| IndexWriter | Handling writing to index – addDocument, updateDocument, deleteDocuments, merge etc | IndexWriter writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_30), new MaxFieldLength(1010101)); |
| IndexSearcher | Search using indexReader – search(query, int) | IndexSearcher searcher = new IndexSearcher(indexDirectory); |
| Document | DTO used to index and search | Document document = new Document(); |
| Field | Each document contains multiple fields. Has 2 part, name, value. | new Field(‘id’, ‘1’, Store.YES, Index.NOT_ANALYZED) |
| Term | A word from test. Used in search.2 parts.Field to search and value to search | Term term = new Term(‘id’, ‘1’); |
| Query | Base of all types of queries – TermQuery, BooleanQuery, PrefixQuery, RangeQuery, WildcardQuery, PhraseQuery etc. | Query query = new TermQuery(term); |
| Analyzer | Builds tokens from text, and helps in building index terms from text | new StandardAnalyzer() |
The Lucene Directory
Directory – is the data space on which lucene operates. It can be a File System or a Memory.
Below are the often used Directory
| Directory | Description | Example |
| FSDirectory | File System based Directory | Directory = FSDirectory.open(File file); // File -> Directory path |
| RAMDirectory | Memory based Lucene directory | Directory = new MemoryDirectory() Directory = new MemoryDirectory(Directory dir) // load File based Directory to memory |
Create an Index Entry
Lucene ‘Document’ object is the main object used in indexing. Documents contain multiple fields. The Analyzers work on the document fields to break them down into tokens and then writes the Directory using an Index Writer.
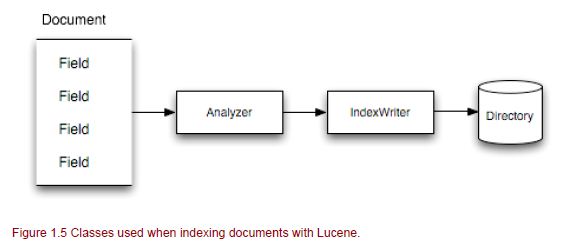
IndexWriter
1 | IndexWriter writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_30), true, MaxFieldLength.UNLIMITED); |
Analyzers
The job of analyzing text into tokens or keywords to be searched. There are few default Analyzers provided by Lucene. The choice of Analyzer defined how the indexed text is tokenized and searched.
Below are some standard analyzers.
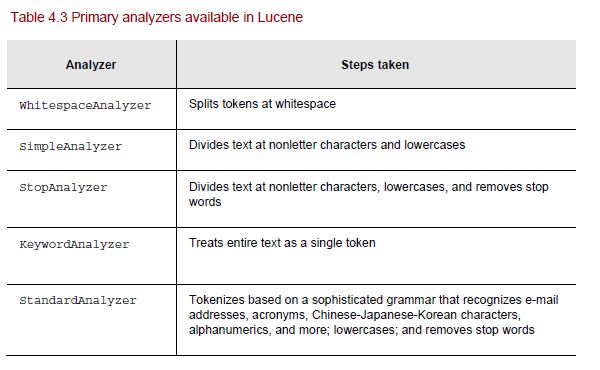
Example – How analyzers work on sample text

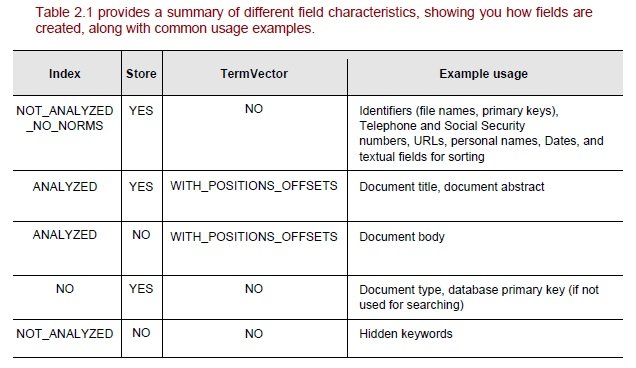
Properties that define Field indexing
- Store – Should the Field be stored to retrieve in the future
- ANALYZED – Should the contents be split into tokens
- TermVECTOR – Term based details to be stored or not
Store :
Should the field be stored to retreive later
| STORE.YES | Store the value, can be retrieved later from the index |
| STORE.NO | Don’t store. Used along with Index.ANALYZED. When token are used only for search |
Analyzed:
How to analyze the text
| Index.ANALYZED | Break the text into tokens, index each token make them searchable |
| Index.NOT_ANALYZED | Index the whole text as a single token, but don’t analyze (split them) |
| Index.ANALYZED_NO_NORMS | Same as ANALYZED, but does not store norms |
| Index.NOT_ANALYZED_NO_NORMS | Same as NOT_ANALYZED, but without norms |
| Index.NO | Don’t make this field searchable completely |
Term Vector
Need Term details for similar, highlight etc.
| TermVector.YES | Record UNIQUE TERMS + COUNTS + NO POSITIONS + NO OFFSETSin each document |
| TermVector.WITH_POSITIONS | Record UNIQUE TERMS + COUNTS + POSITIONS + NO OFFSETSin each document |
| TermVector.WITH_OFFSETS | Record UNIQUE TERMS + COUNTS + NO POSITIONS + OFFSETSin each document |
| TermVector.WITH_POSITIONS_OFFSETS | Record UNIQUE TERMS + COUNTS + POSITIONS + OFFSETSin each document |
| TermVector.NO | Don’t record term vector information |
Example of Creating Index
1 2 3 4 5 6 7 | IndexWriter writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_30), true,MaxFieldLength.UNLIMITED);Document document = new Document();document.add(new Field('id', '1', Store.YES, Index.NOT_ANALYZED));document.add(new Field('name', 'user1', Store.YES, Index.NOT_ANALYZED));document.add(new Field('age', '20', Store.YES, Index.NOT_ANALYZED));writer.addDocument(document); |
Example of Updating Index
1 2 3 4 5 6 7 | IndexWriter writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_30), true,MaxFieldLength.UNLIMITED); Document document = new Document();document.add(new Field("id", "1", Store.YES, Index.NOT_ANALYZED));document.add(new Field("name", "user1", Store.YES, Index.NOT_ANALYZED));document.add(new Field("age", "20", Store.YES, Index.NOT_ANALYZED));writer.addDocument(document); |
Example of Deleting Index
1 2 3 4 | IndexWriter writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_30), MaxFieldLength.UNLIMITED);Term term = new Term('id', '1');writer.deleteDocuments(term); |
Searching an Index : 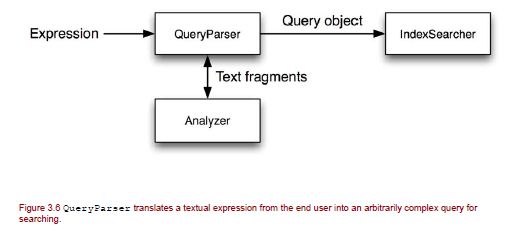 The users specify the query in a text format. The query Object is built based on the query text, analyzed and the result of the executed query is returned as TopDocs.
The users specify the query in a text format. The query Object is built based on the query text, analyzed and the result of the executed query is returned as TopDocs.
Queries are the main input for the search.
| TermQuery | |
| BooleanQuery | AND or not ( combine multiple queries)
|
| PrefixQuery | Starts with |
| WildcardQuery | ? And * – * not allowed in the beginning |
| PhraseQuery | Exact phrase |
| RangeQuery | Term range or numeric range |
| FuzzyQuery | Similar words search |

Sample Queries
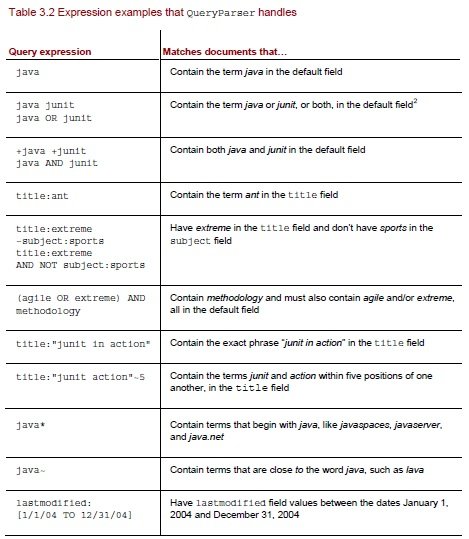
Example on Search:
1 2 3 4 5 6 7 8 | IndexSearcher searcher = new IndexSearcher(indexDirectory);Term term = new Term('id', '1');Query query = new TermQuery(term);TopDocs docs = searcher.search(query, 3);for (int i = 1; i <= docs.totalHits; i++){ System.out.println(searcher.doc(i));} |
Lucene Diagnostic Tools:
- Luke – http://code.google.com/p/luke/
Luke is a handy development and diagnostic tool, which accesses already existing Lucene indexes and allows you to display and modify their content in several ways: - Limo – http://limo.sourceforge.net/
The idea is to have a small tool, running as a web application, that gives basic information about indexes used by the Lucene search engine
Complete Example:
Download here : LuceneTester.java
Resources
- http://lucene.apache.org/core/
- http://www.amazon.com/Lucene-Action-Second-Edition-Covers/dp/1933988177/ref=dp_ob_title_bk
Reference: Lucene – Quickly add Index and Search Capability from our JCG partner Srividhya Umashanker at the Thoughts of a Techie blog.

good article! but the link seems to be wrong ;-)