A Robust Splitter Aggregator Design Strategy – Messaging Gateway Adapter Pattern
What do we mean by robust?
In the context of this article, robustness refers to an ability to manage exception conditions within a flow without immediately returning to the caller. In some processing scenarios n of m responses is good enough to proceed to conclusion. Example processing scenarios that typically have these tendencies are:
- Quotations for finance, insurance and booking systems.
- Fan-out publishing systems.
Why do we need Robust Splitter Aggregator Designs?
First and foremost an introduction to a typical Splitter Aggregator pattern maybe necessary. The Splitter is an EIP pattern that describes a mechanism for breaking composite messages into parts in order that they can be processed individually. A Router is an EIP pattern that describes routing messages into channels – aiming them at specific messaging endpoints. The Aggregator is an EIP pattern that collates and stores a set of messages that belong to a group, and releases them when that group is complete.
Together, those three EIP constructs form a powerful mechanism for dividing processing into distinct units of work. Spring Integration (SI) uses the same pattern terminology as EIP and so readers of that methodology will be quite comfortable with Spring Integration Framework constructs. The SI Framework allows significant customisations of all three of those constructs and furthermore, by simply using asynchronous channels as you would in any other multi-threaded configuration, allows those units of work to be executed in parallel.
An interesting challenge working with SI Splitter Aggregator designs is building appropriately robust flows that operate predictably in a number of invocation scenarios. A simple splitter aggregator design can be used in many circumstances and operate without heavy customisation of the SI constructs. However, some service requirements demand a more robust processing strategy and therefore more complex configuration. The following sections describe and show what a Simple Splitter Aggregator design actually looks like, the type of processing your design must be able to deal with and then goes on to suggest candidate solutions for more robust processing.
A Simple Splitter Aggregator Design
The following Splitter Aggregator design shows a simple flow that receives document request messages into messaging gateway, splits the message into two processing routes and then aggregates the response. Note that the diagram has been built from EIP constructs in OmniGraffle rather than being an Integration Graph view from within STS; the channels are missing from the diagram for the sake of brevity.
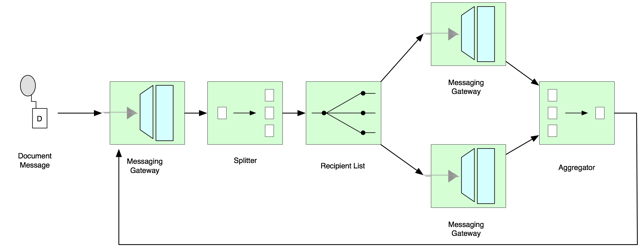
SI Constructs in detail:
Messaging Gateways – there are three messaging gateways. A number of configurations are available for gateway specifications but significantly can return business objects, exceptions and nulls (following a timeout). The gateway to the far left is the service gateway for which we are defining the flow. The other two gateways, between the Router and Aggregator, are external systems that will be providing responses to business questions that our flow generates.
The Splitter – a single splitter exists and is responsible for consuming the document message and producing a collection of messages for onward processing. The Java signature for the, most often, custom Splitter specifies a single object argument and a collection for return.
The Recipient List Router – a single router exists, any appropriate router can be used, chose the one that closely matches your requirements – you can easily route by expression or payload type. The primary purpose of the router is route a collection of messages supplied by the splitter. This is a pretty typical Splitter Aggregator configuration.
Aggregator – a single construct that is responsible for collecting messages together in a group in order that further processing can take place on the gateway responses. Although the Aggregator can be configured with attributes and bean definitions to provide alternative grouping and release strategies, most often the default aggregation strategy suffices.
Interesting Aspects of Splitter Aggregator Operation
- Gateway – the inbound gateway, the one on the far left, may or may not have an error handling bean reference defined on it. If it does then that bean will have an opportunity to handle an exceptions thrown within the flow to the right of that gateway. If not, any exception will be thrown straight out of the gateway.
- Gateway – an optional default-reply-timeout can be set on each of the gateways, there are significant implications for setting this value, ensure that they’re well understood. An expired timeout will result in a null being returned from the gateway. This is the very same condition that can lead to a thread getting parked if an upstream gateway also has no default-reply-timeout set.
- Splitter Input Channel – this can be a simple direct channel or a direct channel with a dispatcher defined on it. If the channel has a dispatcher specified the flow downstream of this point will be asynchronous, multi-threaded. This also changes the upstream gateway semantics as it usually means that an otherwise impotent default-reply-timeout becomes active.
- Splitter – the splitter must return a single object. The single object returned by the splitter is a collection, a java.util.List. The SI framework will take each member of that list and feed it into the output-channel of the Splitter – as with this example, usually straight into a router. The contract for Splitter List returns is as its use in Java – it may contain zero, one or more elements. If the splitter returns an empty list it’s unlikely that the router will have any work to do and so the flow invocation will be complete. However, if the List contains one item, the SI framework will extract that item from the list and push it into the router, if this gets routed successfully, the flow will continue.
- Router – the router will simply route messages into one of two gateways in this example.
- Gateways – the two gateways that are used between the Splitter and Aggregator are interesting. In this example I have used the generic gateway EIP pattern to represent a message sub-system but not defined it explicitly – we could use an HTTP outbound gateway, another SI flow or any other external system. Of course, for each of those sub-systems, a number of responses is possible. Depending on the protocol and external system, the message request may fail to send, the response fail to arrive, a long running process invoked, a network error or timeout or a general processing exception.
- Aggregator – the single aggregator will wait for a number of responses depending on what’s been created by the Splitter. In the case where the splitter return list is empty the Aggregator will not get invoked. In the case where the Splitter return list has one entry, the aggregator will be waiting for one gateway response to complete the group. In the case where the Splitter list has n entries the Aggregator will be waiting for n entries to complete the group. Custom correlation strategies, release strategies and message stores can be injected amongst a set of rich configuration aspects.
Interesting Aspects of Simple Splitter Aggregator Operation
The primary deciding factor for establishing whether this type of simple gateway is adequate for requirements is to understand what happens in the event of failure. If any exception occurring in your SI flow results in the flow invocation being abandoned and that suits your requirements, there’s no need to read any further. If, however, you need to continue processing following failure in one of the gateways the remainder of this article may be of more interest.
Exceptions, from any source, generated between the splitter and aggregator, will result in an empty or partial group being discarded by the Aggregator. The exception will propagate back to the closest upstream gateway for either handling by a custom bean or re-throwing by the gateway. Note that a custom release strategy on the Aggregator is difficult to use and especially so alongside timeouts but would not help in this case as the exception will propagate back to the leftmost gateway before the aggregator is invoked.
It’s also possible to configure exception handlers on the innermost gateways, the exception message could be caught but how do you route messages from a custom exception handler into the aggregator to complete the group, inject the aggregator channel definition into the custom exception handler? This is a poor approach and would involve unpacking an exception message payload, copying the original message headers into a new SI message and then adding the original payload – only four or five lines of code, but dirty it is.
Following exception generation, exception messages (without modification) cannot be routed into an Aggregator to complete the group. The original message, the one that contains the correlation and sequence ids for the group and group position are buried inside the SI messages exception payload.
If processing needs to continue following exception generation, it should be clear that in order to continue processing, the following must take place:
- the aggregation group needs to be completed,
- any exceptions must be caught and handled before getting back to the closet upstream gateway,
- the correlation and sequence identifiers that allow group completion in the aggregator are buried within the exception message payload and will require extraction and setting on the message that’s bound for the aggregator
A More Robust Solution – Messaging Gateway Adapter Pattern
Dealing with exceptions and null returns from gateways naturally leads to a design that implements a wrapper around the messaging gateway. This affords a level of control that would otherwise be very difficult to establish.
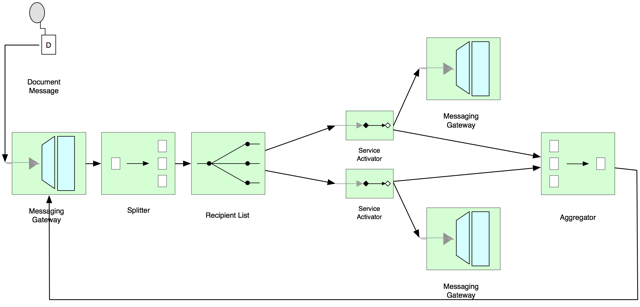
This adapter technique allows all returns from messaging gateways to be caught and processed as the messaging gateway is injected into the Service Activator and called directly from that. The messaging gateway no longer responds to the aggregator directly, it responds to a custom Java code Spring bean configured in the Service Activator namespace definition. As expected, processing that does not undergo exception will continue as normal. Those flows that experience exception conditions or unexpected or missing responses from messaging gateways need to process messages in such as way that message groups bound for aggregation can be completed. If the Service Activator were to allow the exception to be propagated outside of it’s backing bean, the group would not complete. The same applies not just for exceptions but any return object that does not carry the prerequisite group correlation id and sequence headers – this is where the adaptation is applied.
Exception messages or null responses from messaging gateways are caught and handled as shown in the following example code:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 | import com.l8mdv.sample.*;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.integration.Message;import org.springframework.integration.MessageHeaders;import org.springframework.integration.support.MessageBuilder;import org.springframework.util.Assert;public class AvsServiceImpl implements AvsService { private static final Logger logger = LoggerFactory.getLogger(AvsServiceImpl.class); public static final String MISSING_MANDATORY_ARG = "Mandatory argument is missing."; private AvsGateway avsGateway; public AvsServiceImpl(final AvsGateway avsGateway) { this.avsGateway = avsGateway; } public Message<AvsResponse> service(Message<AvsRequest> message) { Assert.notNull(message, MISSING_MANDATORY_ARG); Assert.notNull(message.getPayload(), MISSING_MANDATORY_ARG); MessageHeaders requestMessageHeaders = message.getHeaders(); Message<AvsResponse> responseMessage = null; try { logger.debug("Entering AVS Gateway"); responseMessage = avsGateway.send(message); if (responseMessage == null) responseMessage = buildNewResponse(requestMessageHeaders, AvsResponseType.NULL_RESULT); logger.debug("Exited AVS Gateway"); return responseMessage; } catch (Exception e) { return buildNewResponse(responseMessage, requestMessageHeaders, AvsResponseType.EXCEPTION_RESULT, e); } } private Message<AvsResponse> buildNewResponse(MessageHeaders requestMessageHeaders, AvsResponseType avsResponseType) { Assert.notNull(requestMessageHeaders, MISSING_MANDATORY_ARG); Assert.notNull(avsResponseType, MISSING_MANDATORY_ARG); AvsResponse avsResponse = new AvsResponse(); avsResponse.setError(avsResponseType); return MessageBuilder.withPayload(avsResponse) .copyHeadersIfAbsent(requestMessageHeaders).build(); } private Message<AvsResponse> buildNewResponse(Message<AvsResponse> responseMessage, MessageHeaders requestMessageHeaders, AvsResponseType avsResponseType, Exception e) { Assert.notNull(responseMessage, MISSING_MANDATORY_ARG); Assert.notNull(responseMessage.getPayload(), MISSING_MANDATORY_ARG); Assert.notNull(requestMessageHeaders, MISSING_MANDATORY_ARG); Assert.notNull(avsResponseType, MISSING_MANDATORY_ARG); Assert.notNull(e, MISSING_MANDATORY_ARG); AvsResponse avsResponse = new AvsResponse(); avsResponse.setError(avsResponseType, responseMessage.getPayload(), e); return MessageBuilder.withPayload(avsResponse) .copyHeadersIfAbsent(requestMessageHeaders).build(); }} |
Notice the last line of the catch clause of the exception handling block. This line of code copies the correlation and sequence headers into the response message, this is mandatory if the aggregation group is going to be allowed to complete and will always be necessary following an exception as shown here.
Consequences of using this technique
There’s no doubt that introducing a Messaging Gateway Adapter into SI config makes the configuration more complex to read and follow. The key factor here is that there is no longer a linear progression through the configuration file. This because the Service Activator must forward reference a Gateway or a Gateway defined before it’s adapting Service Activator – in both cases the result is the same.
Resources
Note:- The design for the software that drove creation of this meta-pattern was based on a requirement that a number of external risk assessment services would be accessed by a single, central Risk Assessment Service. In order to satisfy clients of the service, invocation had to take place in parallel and continue despite failure in any one of those external services. This requirement lead to the design of the Messaging Gateway Adapter Pattern for the project.
- Spring Integration Reference Manual
- The solution approach for this problem was discussed directly with Mark Fisher (SpringSource) in the context of building Risk Assessment flows for a large US financial institution. Although the configuration and code is protected by NDA and copyright, it’s acceptable to express the design intention and similar code in this article.
