Java is becoming new C/C++ , it is extensively used in developing High Performance System. Good for millions of Java developer like me!
In this blog i will share my experiment with different types of memory allocation that can be done in java and what type of benefit you get with that.
Memory Allocation In Java
What type of support Java provide for memory allocation:
– Heap Memory
I don’t i have to explain this, all java application starts with this. All object allocated using “new” keyword goes under Heap Memory
– Non Direct ByteBuffer
It is wrapper over byte array, just flavor of Heap Memory.
ByteBuffer.allocate() can be used to create this type of object, very useful if you want to deal in terms of bytes not Object.
– Direct ByteBuffer
This is the real stuff that java added since JDK 1.4.
Description of Direct ByteBuffer based on Java Doc
“A direct byte buffer may be created by invoking the allocateDirect factory method of this class. The buffers returned by this method typically have somewhat higher allocation and deallocation costs than non-direct buffers. The contents of direct buffers may reside outside of the normal garbage-collected heap, and so their impact upon the memory footprint of an application might not be obvious. It is therefore recommended that direct buffers be allocated primarily for large, long-lived buffers that are subject to the underlying system’s native I/O operations. In general it is best to allocate direct buffers only when they yield a measureable gain in program performance.”
Important thing to note about Direct Buffer is
- It is Outside of JVM
- Free from Garbage Collector reach.
These are very important things if you care about performance.
MemoryMapped file are also flavor of Direct byte buffer, i shared some of my finding with that in below blogs:
Off Heap or Direct Memory
This is almost same as Direct ByteBuffer but with little different, it can be allocated by unsafe.allocateMemory, as it is direct memory so it creates no GC overhead. Such type of memory must be manually released.
In theory Java programmer are not allowed to do such allocation and i think reason could be
- It is complex to manipulate such type of memory because you are only dealing with bytes not object
- C/C++ community will not like it
Lets take deep dive into memory allocation
For memory allocation test i will use 13 byte of message & it is broken down into
- int – 4 byte
- long – 8 byte
- byte – 1 byte
I will only test write/read performance, i am not testing memory consumption/allocation speed.
Write Performance
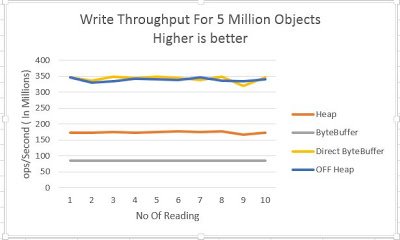
X Axis – No Of Reading
Y Axis – Op/Second in Millions
5 Million 13 bytes object are written using 4 types of allocation.
- Direct ByteBuffer & Off Heap are best in this case, throughput is close to
- 350 Million/Sec
- Normal ByteBuffer is very slow, TP is just 85 Million/Sec
- Direct/Off Heap is around 1.5X times faster than heap
I did same test with 50 Million object to check how does it scale, below is graph for same.
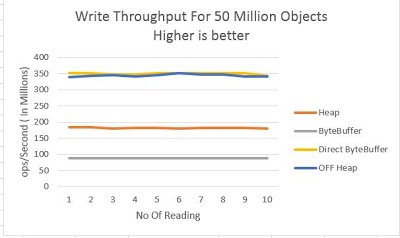
X Axis – No Of Reading
Y Axis – Op/Second in Millions
Numbers are almost same as 5 Million.
Read Performance
Lets look at read performance
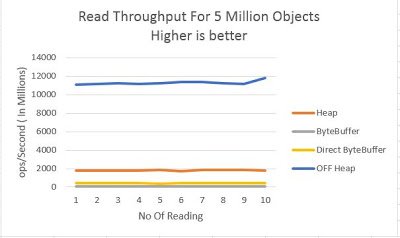
X Axis – No Of Reading
Y Axis – Op/Second in Millions
This number is interesting, OFF heap is blazing fast throughput for 12,000 Millions/Sec. Only close one is HEAP read which is around 6X times slower than OFF Heap.
Look at Direct ByteBuffer , it is tanked at just 400 Million/Sec, not sure why it is so.
Lets have look at number for 50 Million Object
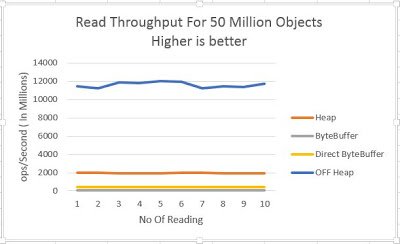
X Axis – No Of Reading
Y Axis – Op/Second in Millions
Not much different.
Conclusion
Off heap via Unsafe is blazing fast with 330/11200 Million/Sec.
Performance for all other types of allocation is either good for read or write, none of the allocation is good for both.
Special note about ByteBuffer, it is pathetic , i am sure you will not use this after seeing such number. DirectBytebuffer sucks in read speed, i am not sure why it is so slow.
So if memory read/write is becoming bottle neck in your system then definitely Off-heap is the way to go, remember it is highway, so drive with care.
Code is available @git hub

Ashkrit, Thanks for this analysis. ByteBuffer.allocateDirect(); also uses Unsafe by using DirectByteBuffer, so how is Unsafe.allocateMemory() different? The results you have shown are really fascinating in favor of Off-Heap using Unsafe. Some of the questions to you here: 1. you never used setMemory() function. why? is it because Unsafe.putXXX() anyways were going to overwrite any pre-existing values? 2. when you perform operations inside the off-heap class, like identifyIndex(), etc, where are they getting executed? on-heap/off-heap? I ask this because, using Unsafe.putXXX() you use off-heap memory but all other operations like getDeclaredFields() of a particular class to get its data, and… Read more »
1 – Regarding you question of why i did’t use setMemory. This function is used to set some initial value to the memory that is allocated , if you don’t do it then you will see some garbage, just like c/c++. i did’t do it because it was ok for my test to ignore that step, but in real word we must set value to 0. 2 – Regarding you second question. All the functions of Unsafe operate in JVM space, so there is cost of transfer because all function are native, but native function of Unsafe are special they… Read more »
Ashkrit, Thanks for your reply. I understood the answer to the first question. I asked it because, I thought setMemory(offset, size, 0) is a standard practice in Unsafe to make sure the entire block is set to ZERO. Was suspecting that you dint do it because it could cause some additional time. Do you think additional time Vs data corruption? what would you risk? For the 2nd questions, I understand that Unsafe method calls are using intrinsic functions of java which are native like, Unsafe.allocate(), Unsafe.putXXX(), Unsafe.getXXX(). But, my question is different. I want to know that a function like… Read more »
For 1st – It is more data corruption than time. If data structure using off heap can manage the pointer in such a way that it never allow access to corrupted data or invalid/slate data then we can get rid of resetting. 2nd – identifyindex is executed off heap. JVM does lot of smart thing for intrinsic, like it will do method inline, which i think does’t not happen with native method, in many case intrinsic will try to use feature of underlying platform. for eg – Integer.bitCount() is intrinsic ,if you look in source code, it has java impl… Read more »
Ashkrit, Thanks again for this information and explanation. My question of off-heap usage is more related to code execution that necessarily uses heap like TestMemoryAllocator.java should be using java heap while as you said identifyindex () should still be off-heap because its related to Unsafe’s positioning. So, if I am designing a system for high speeds, what should I presume to be off-heap? Would it be all the code restricted to the usage Unsafe? If that’s the case, then what’s with the communication between objects on heap and data off-heap? Intrinsic functions are very useful. thanks for the link and… Read more »
Forgot to mention that DirectByteBuffer implementation and off-heap implementation looks identical. However, their read times are different most likely because while writing its both underlying implementations are using Unsafe but while reading, DirectByteBuffer is bringing data to heap. Any data brought from native memory to JVM will need to be converted into a byte array (its allocation on heap as an object takes time) that’s why it seems to be taking so much more time, even more than the direct heap implementation. This is a thought, but I havent verified it through tests.
With numbers it looked like DirectByteBuffer brings all data in Heap, but i did’t spend time to confirm that.
I have to also do some test to confirm this fact.
Ok sure some test data will be great but reading DirectByteBuffer to JVM heap is done via byte[] and that’s when it takes a lot of time.
I don’t follow this explanation – the Off-heap implementation is calling:
@Override
public byte getByte() {
return unsafe.getByte(pos + byte_offset);
}
the DirectMeomoryBuffer implementation is calling:
public byte More …get() {
return ((unsafe.getByte(ix(nextGetIndex()))));
}
Where is the “bringing memory to heap space” happening in DMB vs off heap objects?
Ashkrit,
One more question on why havent you used ByteBuffer class functions?
Reply option is disable on the original thread, so using this one I use below approach to solve the problem of building high speed application Stay away from class like object model because it hurts performance due to memory indirection – Keep data in memory using simple array like structure, best is column like approach which gives excellent performance because data is laid out linearly and you get benefit of hardware CPU cache, Prefetcher etc. In this approach you can get reasonable performance but GC comes in picture and you have to deal with it. – If you want to… Read more »
Ashkrit, Thanks for your reply again. I certainly appreciate it. ByteBuffer functions like position(),limit(), put()/get(), etc. which are defined in the API. I think you havent used them because it would be done on JAVA heap, esp. for writing. So, you got similar to Unsafe results for writing. However, I think because reads still bring the data to JAVA heap, the results are poor. I just wanted to check with you, if its true. I am going to read upon your memory-mapped article files later. Thanks for great postings. Yes, there is a lot of great opportunity here, but I… Read more »
I have one further question based on the article presented here:
http://mentablog.soliveirajr.com/2012/11/which-one-is-faster-java-heap-or-native-memory/
It seems to me you are using the same technique to access Off-heap memory, and yet you experience much better results, clearly unaffected by the JNI calls. Could you explain why that might be the case?
My this article was as part of curiosity from the article you mention above, i have commented on it with my result before writing this blog!
Difference is that i am allocating one big array for all the objects and the blog that you mention allocate memory per object
Allocating one big array has lot of nice benefit
– Predictable memory access
– Most of the data will be prefetched
This type of allocation will be more cpu cache friendly.
It seem that your implementation of HeapAllocatedObject is not apple-to-apple comparison, as you added extra layer HeapValue and caused addition index-lookup and memory fragmentation.
As the Object construct and GC are only happen in HeapAllocatedObject, but not others. it supposed to be slowest.
One of the reason to write this blog is to share the overhead you have with plain java object. Heapvalue will have all the overhead that is associated with any object due to layout used by java, all the heap allocation will have GC overhead also and direct memory is free from it and that is one of the big reason of write speed you get with direct memory. Bytebuffer shows interesting result , it has worst write performance although it is just backed by bytearray and most compact way to store data on heap. Access by index is not… Read more »
Thanks for your interesting posts. So what is the reason caused ByteBuffer slower than Heap in both read and write performance?
I have to do some more investigation to workout the cause, but some of the factor to consider are
– for ByteBuffer data is stored in bytearray , so every time you ask for long fair bit of shift operation happens for converting byte to Long value because of bigEndian/littleendian on both read & write side.
– Another thing to consider can be bigEndian/littleendian, for littleendian byte array is read in reverse order(8th byte to 1th byte), so there is high chance that CPU prefetchers are not of much use, i have not benchmarked this assumption
The Unsafe is (btw) just like memcpy(&arr, (char*)&integer, 4);
You cannot compare this to manual encoding (like bitshifting…).
I mean the ByteBuffer which located on heap, not the directBuffer, so there is no unsafe usage.
“This is almost same as Direct ByteBuffer but with little different, it can be allocated by unsafe.allocateMemory, as it is direct memory so it creates no GC overhead”
Should’ve explained this properly. You are showing huge differences in results, but describing as “little different”. Shows you also don’t know much about it.
“C/C++ community will not like it”
Shows your immaturity… why on earth they won’t like it.
That sentence was more from API usage point of view not on real result. I not expert in this area, i am just sharing my observation and if you don’t like it then it is fine. It would be nice if you can share your experience with Direct Bytebuffer.
Regarding C/C++ community you missed the whole context
Would you be willing to share the code you used for this test? I performed a similar test, but using 100M int primitives, and found on-heap (via int[]) to be fastest for both read and write. I’d be curious to see where the difference lies. I suspect your more complex data structure might kill on-heap due to additional pointer redirection and loss of locality, but as always, the devil’s in the details. As for my own version of the test, I’ve just started looking at output from -XX:+PrintAssembly but it seems like the JIT is better able to optimize serialized… Read more »
Link to code is broken on this page.
Code is available @ https://github.com/ashkrit/blog/tree/master/src/main/java/allocation
Test code is also available @ https://github.com/ashkrit/blog/blob/master/src/main/java/allocation/TestMemoryAllocator.java
Can you share your test env details.
My testing was done on below specs.
OS : Windows 8
JDK : 1.7 build 45+
Processor : i7-3632QM @ 2.20 GHz
My test environment is: OS : Ubuntu 14.04 JDK : OpenJDK 1.7.0_91 CPU: Xeon E5-1650 Measured average time per item over 100M integers is as follows… Writes: int[] – 0.952ns = 1050 Mops/sec Unsafe – 1.228ns = 814 Mops/sec direct ByteBuffer – 1.328ns = 753 Mops/sec heap ByteBuffer – 1.886ns = 530 Mops/sec Reads: int[] – 0.502ns = 1992 Mops/sec Unsafe – 0.872ns = 1146 Mops/sec direct ByteBuffer – 0.944ns = 1059 Mops/sec heap ByteBuffer – 2.175ns = 459 Mops/sec I’ve posted the source of my test here: https://docs.google.com/document/d/1_Mi8atjsYqGtuWUDmfTnnVG0qaeS2f6j3th9oeMXXKs/edit?usp=sharing I’ve placed each individual test into a single method and all… Read more »
Bench mark code for read function had “dead code elimination” problem due to which that numbers were wrong!
Later code was fixed but i forgot to update the blog with latest result. Numbers shared by you are very much close to what i am also getting.
Yes agree JDK9 will do something to improve object layout.
Gil Tene from azul started with library that optimized memory layout of object.
you can have look @ http://objectlayout.github.io/ObjectLayout/ for more details.
Thanks, nice post
what is the difference between off heap & Direct buffer
well done