Although Hadoop Framework itself is created with Java the MapReduce jobs can be written in many different languages. In this post I show how to create a MapReduce job in Java based on a Maven project like any other Java project.
- Prepare the example input
Lets start with a fictional business case. In this case we need a CSV file with English words from a dictionary and all translations in other languages added to it, separated by a ‘|’ symbol. I have based this example on this post. So the job will read dictionaries of different languages and match each English word with a translation in another language. The input dictionaries for the job is taken from here. I downloaded a few files in different languages and put them together in one file (Hadoop is better to process one large file than multiple small ones). My example file can be found here.
- Create the Java MapReduce project
Next step is creating the Java code for the MapReduce job. Like I said before I use a Maven project for this so I created a new empty Maven project in my IDE, IntelliJ. I modified the default pom to add the necessary plugins and dependencies:
The dependency I added:
1 2 3 4 5 6 | <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-core</artifactId> <version>1.2.0</version> <scope>provided</scope></dependency> |
The Hadoop dependency is necessary to make use of the Hadoop classes in my MapReduce job. Since I want to run the job on AWS EMR I make sure I have a matching Hadoop version. Furthermore the scope can be set to ‘provided’ since the Hadoop framework will be available on the Hadoop cluster.
Beside the dependency I added the following two plugins to the pom.xml:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 | <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <configuration> <archive> <manifest> <addClasspath>true</addClasspath> <mainClass>net.pascalalma.hadoop.Dictionary</mainClass> </manifest> </archive> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.6</source> <target>1.6</target> </configuration> </plugin></plugins> |
The first plugin is used to create an executable jar of our project. This makes the running of the JAR on the Hadoop cluster easier since we don’t have to state the main class.
The second plugin is necessary to make the created JAR compatible with the instances of the AWS EMR cluster. This AWS cluster comes with a JDK 1.6. If you omit this one the cluster will fail (I got a message like ‘Unsupported major.minor version 51.0′). I will show later in another post how to setup this AWS EMR cluster.
That is the basic project, just like a regular Java project. Lets implement the MapReduce jobs next.
- Implement the MapReduce classes
I have described the functionality that we want to perform in the first step. To achieve this I created three Java classes in my Hadoop project. The first class is the ‘Mapper‘:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | package net.pascalalma.hadoop;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;import java.util.StringTokenizer;/** * Created with IntelliJ IDEA. * User: pascal * Date: 16-07-13 * Time: 12:07 */public class WordMapper extends Mapper<Text,Text,Text,Text> { private Text word = new Text(); public void map(Text key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString(),","); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(key, word); } }} |
This class isn’t very complicated. It just receives a row from the input file and creates a Map of it in which each key will have one value (and multiple keys are allowed at this stage).
The next class is the ‘Reducer‘ which reduces the map to the wanted output:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | package net.pascalalma.hadoop;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/** * Created with IntelliJ IDEA. * User: pascal * Date: 17-07-13 * Time: 19:50 */public class AllTranslationsReducer extends Reducer<Text, Text, Text, Text> { private Text result = new Text(); @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { String translations = ""; for (Text val : values) { translations += "|" + val.toString(); } result.set(translations); context.write(key, result); }} |
This Reduce steps collects all values for a given key and put them after each other separated with a ‘|’ symbol.
The final class left is the one that is putting it all together to make it a runnable job:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | package net.pascalalma.hadoop;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;/** * Created with IntelliJ IDEA. * User: pascal * Date: 16-07-13 * Time: 12:07 */public class Dictionary { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, "dictionary"); job.setJarByClass(Dictionary.class); job.setMapperClass(WordMapper.class); job.setReducerClass(AllTranslationsReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setInputFormatClass(KeyValueTextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); }} |
In this main method we put together a Job and run it. Please note that I simply expect the args[0] and args[1] to be the name of the input file and output directory (non existing). I didn’t add any check for this. Here is my ‘Run Configuration’ in IntelliJ:
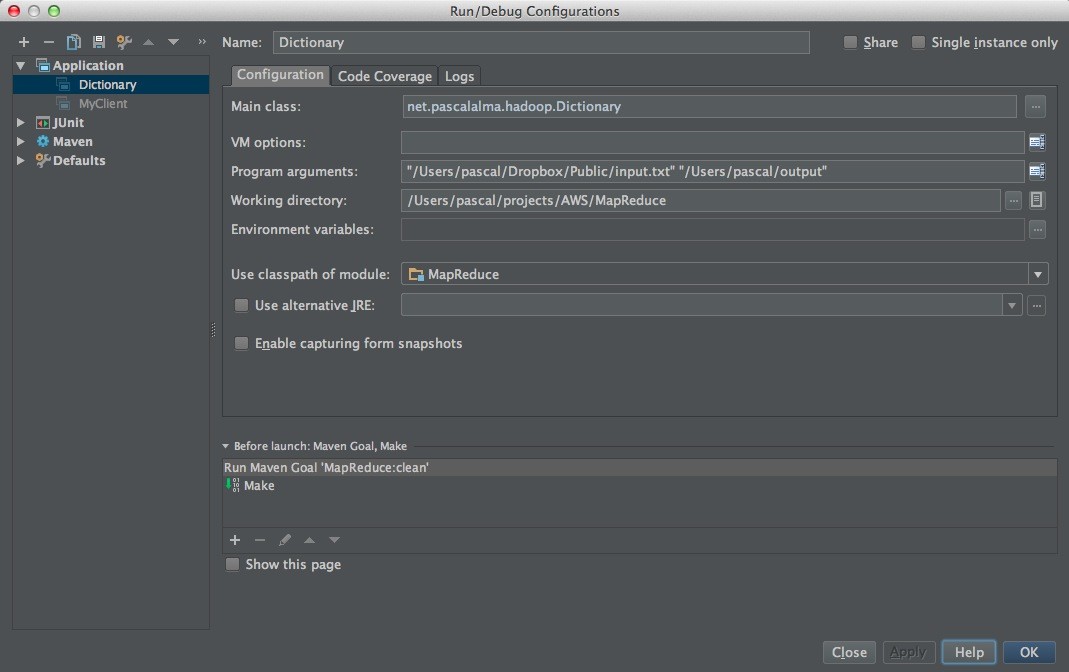
Just make sure the output directory is not existing at the time you run the class. The logging output created by the job looks like this:
001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050 051 052 053 054 055 056 057 058 059 060 061 062 063 064 065 066 067 068 069 070 071 072 073 074 075 076 077 078 079 080 081 082 083 084 085 086 087 088 089 090 091 092 093 094 095 096 097 098 099 100 101 102 103 104 105 106 107 | 2013-08-15 21:37:00.595 java[73982:1c03] Unable to load realm info from SCDynamicStoreaug 15, 2013 9:37:01 PM org.apache.hadoop.util.NativeCodeLoader <clinit>WARNING: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableaug 15, 2013 9:37:01 PM org.apache.hadoop.mapred.JobClient copyAndConfigureFilesWARNING: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.aug 15, 2013 9:37:01 PM org.apache.hadoop.mapred.JobClient copyAndConfigureFilesWARNING: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).aug 15, 2013 9:37:01 PM org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatusINFO: Total input paths to process : 1aug 15, 2013 9:37:01 PM org.apache.hadoop.io.compress.snappy.LoadSnappy <clinit>WARNING: Snappy native library not loadedaug 15, 2013 9:37:01 PM org.apache.hadoop.mapred.JobClient monitorAndPrintJobINFO: Running job: job_local_0001aug 15, 2013 9:37:01 PM org.apache.hadoop.mapred.Task initializeINFO: Using ResourceCalculatorPlugin : nullaug 15, 2013 9:37:01 PM org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>INFO: io.sort.mb = 100aug 15, 2013 9:37:01 PM org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>INFO: data buffer = 79691776/99614720aug 15, 2013 9:37:01 PM org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>INFO: record buffer = 262144/327680aug 15, 2013 9:37:02 PM org.apache.hadoop.mapred.MapTask$MapOutputBuffer flushINFO: Starting flush of map outputaug 15, 2013 9:37:02 PM org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpillINFO: Finished spill 0aug 15, 2013 9:37:02 PM org.apache.hadoop.mapred.Task doneINFO: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commitingaug 15, 2013 9:37:02 PM org.apache.hadoop.mapred.JobClient monitorAndPrintJobINFO: map 0% reduce 0%aug 15, 2013 9:37:04 PM org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdateINFO: aug 15, 2013 9:37:04 PM org.apache.hadoop.mapred.Task sendDoneINFO: Task 'attempt_local_0001_m_000000_0' done.aug 15, 2013 9:37:04 PM org.apache.hadoop.mapred.Task initializeINFO: Using ResourceCalculatorPlugin : nullaug 15, 2013 9:37:04 PM org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdateINFO: aug 15, 2013 9:37:04 PM org.apache.hadoop.mapred.Merger$MergeQueue mergeINFO: Merging 1 sorted segmentsaug 15, 2013 9:37:04 PM org.apache.hadoop.mapred.Merger$MergeQueue mergeINFO: Down to the last merge-pass, with 1 segments left of total size: 524410 bytesaug 15, 2013 9:37:04 PM org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdateINFO: aug 15, 2013 9:37:05 PM org.apache.hadoop.mapred.Task doneINFO: Task:attempt_local_0001_r_000000_0 is done. And is in the process of commitingaug 15, 2013 9:37:05 PM org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdateINFO: aug 15, 2013 9:37:05 PM org.apache.hadoop.mapred.Task commitINFO: Task attempt_local_0001_r_000000_0 is allowed to commit nowaug 15, 2013 9:37:05 PM org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTaskINFO: Saved output of task 'attempt_local_0001_r_000000_0' to /Users/pascal/outputaug 15, 2013 9:37:05 PM org.apache.hadoop.mapred.JobClient monitorAndPrintJobINFO: map 100% reduce 0%aug 15, 2013 9:37:07 PM org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdateINFO: reduce > reduceaug 15, 2013 9:37:07 PM org.apache.hadoop.mapred.Task sendDoneINFO: Task 'attempt_local_0001_r_000000_0' done.aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.JobClient monitorAndPrintJobINFO: map 100% reduce 100%aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.JobClient monitorAndPrintJobINFO: Job complete: job_local_0001aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Counters: 17aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: File Output Format Counters aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Bytes Written=423039aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: FileSystemCountersaug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: FILE_BYTES_READ=1464626aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: FILE_BYTES_WRITTEN=1537251aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: File Input Format Counters aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Bytes Read=469941aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Map-Reduce Frameworkaug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Reduce input groups=11820aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Map output materialized bytes=524414aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Combine output records=0aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Map input records=20487aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Reduce shuffle bytes=0aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Reduce output records=11820aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Spilled Records=43234aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Map output bytes=481174aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Total committed heap usage (bytes)=362676224aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Combine input records=0aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Map output records=21617aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: SPLIT_RAW_BYTES=108aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Reduce input records=21617Process finished with exit code 0 |
The output file created by this job can be found in the supplied output directory as can be seen in the next screenshot:
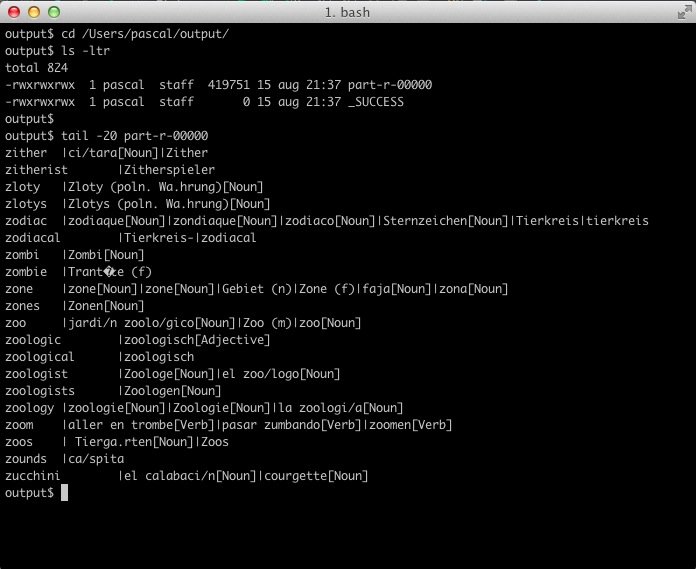
As you have seen we can run this main method in an IDE (or from the command line) but I would like to see some unit tests performed on the Mapper and Reducer before we go there. I will show this in another post how to do that.

Tried to run the job as described – in intellij with the config (paths changed, obviously, but otherwise the same).
The run doesn’t seem to be able to find the configuration class…
Is there a dependency I’m missing in the pom? I just added the one hadoop dependency per the instructions.
Here’s what I get:
Exception in thread “main” java.lang.NoClassDefFoundError: org/apache/hadoop/conf/Configuration
at com.maffy.example.mapreduce.Dictionary.main(Dictionary.java:23)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:120)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.conf.Configuration
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
… 6 more
I think you are using a different version of Hadoop or you don’t have the hadoop-common in your POM/classpath.
Thanks for your post. To perform a MapReduce job, we need a mapper implementation and a reducer implementation. As you can see in the above code, mapper and reducer classes are defined as inner classes. Also MapReduce job configuration happens within its main method, mainly with the use of an instance of Job class. You can go through the WordCount.java code and refer the comments I’ve added in there, to understand these configurations. https://intellipaat.com/
i want a sample program to give a ppt
good explaination about hadoop and map reduce ,
i found more resources where you can find tested source code of map reduce programs
refere this
top 10 map reduce program sources code
top 10 Read Write fs program using java api
top 30 hadoop shell commands
Thanks for sharing info, to perform a MapReduce task, we want a mapper implementation and a reducer implementation. As you could see within the above code, mapper and reducer training are defined as inner training. additionally MapReduce job configuration happens within its major technique, in particular with using an instance of activity elegance. you may go through the WordCount.java code and refer the comments I’ve delivered in there, to apprehend these configurations.
I really enjoy to read your information about Hadoop MapReduce task. Thanks for sharing Appreciate your work. I would like to share about online training. it will be helpful
Thanks for sharing Appreciate your work. the blog above explains the code which will help you use java programming.
Learn Artificial Intelligence Advance Online Certification Training with Assured Placement Support
I really enjoy to read your information about Hadoop MapReduce task. Thanks for sharing Appreciate your work. I would like to share about online training. it will be helpful
Thank you for sharing
Hi, Thanks for sharing
Thanks for sharing
Thanks for sharing article
Thanks, It helped a lot. I was looking for below
Here’s what I get:
Exception in thread “main” java.lang.NoClassDefFoundError: org/apache/hadoop/conf/Configuration
at com.maffy.example.mapreduce.Dictionary.main(Dictionary.java:23)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:120)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.conf.Configuration
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
Can we do this way Replace the build.gradle in the project with the following, apply plugin: 'java-library' apply plugin: 'application' mainClassName = "AlphaCounter" jar { manifest { attributes 'Main-Class': "$mainClassName"} } repositories { jcenter() } dependencies { compile 'org.apache.hadoop:hadoop-client:2.7.3'} <a href=”https://madanswer.com/agile”> agile Interview questions Answers </a> <a href=”https://madanswer.com/javascript”> Java script Interview questions Answers </a> <a href=”https://madanswer.com/ansible”> ansible Interview questions Answers </a> <a href=”https://madanswer.com/bootstrap”> bootstrap Interview questions Answers </a> <a href=”https://madanswer.com/angular”> Angular Interview questions Answers </a> <a href=”https://madanswer.com/android”> Android Interview questions Answers </a> <a href=”https://madanswer.com/Linux”> Linux Interview questions Answers </a> <a href=”https://madanswer.com/Kibana”> Kibana Interview questions Answers </a> <a… Read more »
We appreciate you sharing this information. In order to complete a MapReduce task, we need both a Mapper and a Reducer implementation. Mapper and reducer training are referred to as inner training in the code above, as you can see. Furthermore, MapReduce job configuration takes place within its primary method, particularly when employing an example of activity elegance. To understand these configurations, you can look through the WordCount.java code and refer to the comments I’ve left there. https://infycletechnologies.com/