In my previous post I showed how to setup a complete Maven based project to create a Hadoop job in Java. Of course it wasn’t complete because it is missing the unit test part . In this post I show how to add MapReduce unit tests to the project I started previously. For the unit test I make use of the MRUnit framework.
- Add the necessary dependency to the pom
Add the following dependency to the pom:
1 2 3 4 5 6 7 | <dependency> <groupId>org.apache.mrunit</groupId> <artifactId>mrunit</artifactId> <version>1.0.0</version> <classifier>hadoop1</classifier> <scope>test</scope></dependency> |
This will made the MRunit framework available to the project.
- Add Unit tests for testing the Map Reduce logic
The use of this framework is quite straightforward, especially in our business case. So I will just show the unit test code and some comments if necessary but I think it is quite obvious how to use it. The unit test for the Mapper ‘MapperTest’:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | package net.pascalalma.hadoop;import org.apache.hadoop.io.Text;import org.apache.hadoop.mrunit.mapreduce.MapDriver;import org.junit.Before;import org.junit.Test;import java.io.IOException;/** * Created with IntelliJ IDEA. * User: pascal */public class MapperTest { MapDriver<Text, Text, Text, Text> mapDriver; @Before public void setUp() { WordMapper mapper = new WordMapper(); mapDriver = MapDriver.newMapDriver(mapper); } @Test public void testMapper() throws IOException { mapDriver.withInput(new Text("a"), new Text("ein")); mapDriver.withInput(new Text("a"), new Text("zwei")); mapDriver.withInput(new Text("c"), new Text("drei")); mapDriver.withOutput(new Text("a"), new Text("ein")); mapDriver.withOutput(new Text("a"), new Text("zwei")); mapDriver.withOutput(new Text("c"), new Text("drei")); mapDriver.runTest(); }} |
This test class is actually even simpler than the Mapper implementation itself. You just define the input of the mapper and the expected output and then let the configured MapDriver run the test. In our case the Mapper doesn’t do anything specific but you see how easy it is to setup a testcase. For completeness here is the test class of the Reducer:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | package net.pascalalma.hadoop;import org.apache.hadoop.io.Text;import org.apache.hadoop.mrunit.mapreduce.ReduceDriver;import org.junit.Before;import org.junit.Test;import java.io.IOException;import java.util.ArrayList;import java.util.List;/** * Created with IntelliJ IDEA. * User: pascal */public class ReducerTest { ReduceDriver<Text, Text, Text, Text> reduceDriver; @Before public void setUp() { AllTranslationsReducer reducer = new AllTranslationsReducer(); reduceDriver = ReduceDriver.newReduceDriver(reducer); } @Test public void testReducer() throws IOException { List<Text> values = new ArrayList<Text>(); values.add(new Text("ein")); values.add(new Text("zwei")); reduceDriver.withInput(new Text("a"), values); reduceDriver.withOutput(new Text("a"), new Text("|ein|zwei")); reduceDriver.runTest(); }} |
- Run the unit tests it
With the Maven command “mvn clean test” we can run the tests:
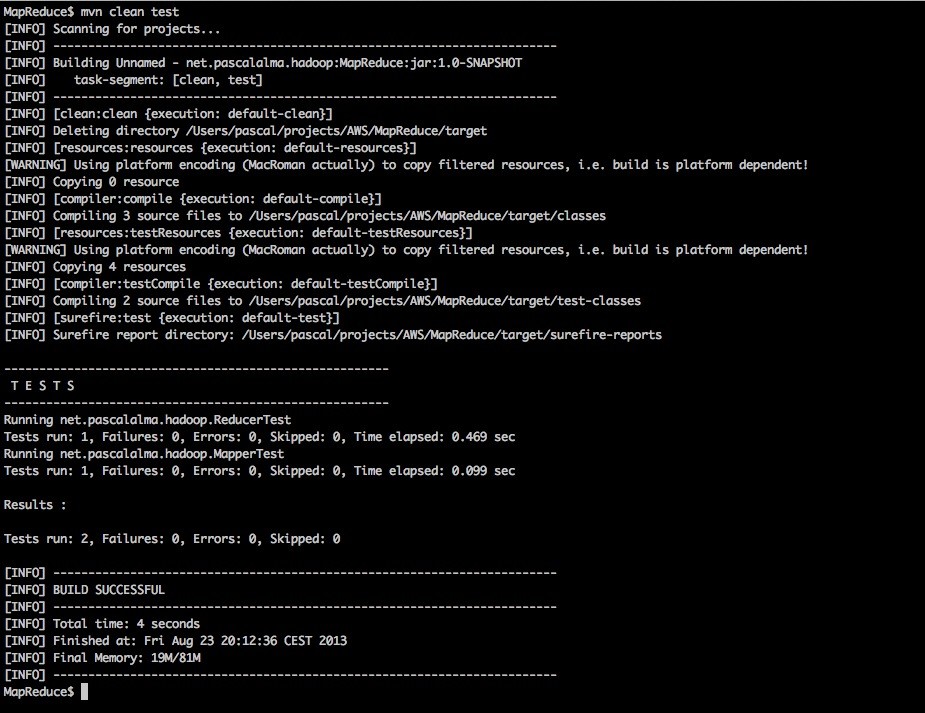
With the unit tests in place I would say we are ready to build the project and deploy it to an Hadoop cluster, which I will describe in the next post.

Hi,
First of all thanks a lot for the example.
I am getting this error while running the test case .
ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
)
When I googled it, I found all the answer for this prob happening in actual hadoop environment , I am not sure how to remove this from Junit
Hi Koushik,
It appears to have Hadoop running on Windows it requires some libraries to be installed. It is discussed here: http://stackoverflow.com/questions/19620642/failed-to-locate-the-winutils-binary-in-the-hadoop-binary-path
I am not using Windows so I haven’t run into this issue, but it sounds like the link should help you out.