A decompiler, simply put, attempts to reverse the transformation of source code to object code. But there are many interesting complexities—Java source code is structured; bytecode certainly isn’t. Moreover, the transformation isn’t one-to-one: two different Java programs may yield identical bytecode. We need to apply heuristics in order to get a reasonable approximation of the original source.
(A Tiny) Bytecode Refresher
In order to understand how a decompiler works, it’s necessary to understand the basics of byte code. If you’re already familiar with byte code, feel free to skip ahead to the next section.
The JVM is a stack-based machine (as opposed to a register-based machine), meaning instructions operate on an evaluation stack. Operands may be popped off the stack, various operations performed, and the results pushed back onto the stack for further evaluation. Consider the following method:
1 2 3 4 | public static int plus(int a, int b) { int c = a + b; return c;} |
Note: All byte code shown in this article is output from javap, e.g., javap -c -p MyClass.
1 2 3 4 5 6 7 8 9 | public static int plus(int, int); Code: stack=2, locals=3, arguments=2 0: iload_0 // load ‘x’ from slot 0, push onto stack 1: iload_1 // load ‘y’ from slot 1, push onto stack 2: iadd // pop 2 integers, add them together, and push the result 3: istore_2 // pop the result, store as ‘sum’ in slot 2 4: iload_2 // load ‘sum’ from slot 2, push onto stack 5: ireturn // return the integer at the top of the stack |
(Comments added for clarity.)
A method’s local variables (including arguments to the method) are stored in what the JVM refers to as the local variable array. We’ll refer to a value (or reference) stored in location #x in the local variable array as `slot #x’ for brevity (see JVM Specification §3.6.1).
For instance methods, the value in slot #0 is always the this pointer. Then come the method arguments, from left to right, followed by any local variables declared within the method. In the example above, the method is static, so there is no this pointer; slot #0 holds parameter x, and slot #1 holds parameter y. The local variable sum resides in slot #2.
It’s interesting to note that each method has a max stack size and max local variable storage, both of which are determined at compile time.
One thing that’s immediately obvious from here, which you might not initially expect, is that the compiler made no attempt to optimise the code. In fact, javac almost never emits optimized bytecode. This has multiple benefits, including the ability to set breakpoints at most locations: if we were to eliminate the redundant load/store operations, we’d lose that capability. Thus, most of the heavy lifting is performed at runtime by a just-in-time (JIT) compiler.
Decompiling
So, how can you take unstructured, stack-based byte code and translate it back into structured Java code? One of the first steps is usually to get rid of the operand stack, which we do by mapping stack values to variables and inserting the appropriate load and store operations.
A ‘stack variable’ is only assigned once, and consumed once. You might note that this will lead to a lot of redundant variables—more on this later! The decompiler may also reduce the byte code into an even simpler instruction set, but we won’t consider that here.
We’ll use the notation s0 (etc.) to represent stack variables, and v0 to represent true local variables referenced in the original byte code (and stored in slots).
| Bytecode | Stack Variables | Copy Propagation | |
|---|---|---|---|
| 0 1 2 3 4 5 | iload_0 iload_1 iadd istore_2 iload_2 ireturn | s0 = v0 s1 = v1 s2 = s0 + s1 v2 = s2 s3 = v2 return s3 | v2 = v0 + v1 return v2 |
We get from bytecode to variables by assigning identifiers to every value pushed or popped, e.g., iadd pops two operands to add and pushes the result.
We then apply a technique called copy propagation to eliminate some of the redundant variables. Copy propagation is a form of inlining in which references to variables are simply replaced with the assigned value, provided the transformation is valid.
What do we mean by “valid”? Well, there are some important restrictions. Consider the following:
1 2 3 | 0: s0 = v11: v1 = s42: v2 = s0 <-- s0 cannot be replaced with v1 |
Here, if we were to replace s0 with v0, the behavior would change, as the value of v0 changes after s0 is assigned, but before it is consumed. To avoid these complications, we only use copy propagation to inline variables that are assigned exactly once.
One way to enforce this might be to track all stores to non-stack variables, i.e., we know that v1 is assigned v10 at #0, and also v11 at #2. Since there is more than one assignment to v1, we cannot perform copy propagation.
Our original example, however, has no such complications, and we end up with a nice, concise result:
1 2 | v2 = v0 + v1return v2 |
Aside: Restoring Variable Names
If variables are reduced to slot references in the byte code, how then do we restore the original variable names? It’s possible we can’t. To improve the debugging experience, the byte code for each method may include a special section called the local variable table. For each variable in the original source, there exists an entry that specifys the name, the slot number, and the bytecode range for which the name applies. This table (and other useful metadata) can be included in the javap disassembly by including the -v option. For our plus() method above, the table looks like this:
1 2 3 4 | Start Length Slot Name Signature0 6 0 a I0 6 1 b I4 2 2 c I |
Here, we see that v2 refers to an integer variable originally named ‘c‘ at bytecode offsets #4-5.
For classes that have been compiled without local variable tables (or which had them stripped out by an obfuscator), we have to generate our own names. There are many strategies for doing this; a clever implementation might look at how a variable is used for hints on an appropriate name.
Stack Analysis
In the previous example, we could guarantee which value was on top of the stack at any given point, and so we could name s0, s1, and so on.
So far, dealing with variables has been pretty straightforward because we’ve only explored methods with a single code path. In a real world application, most methods aren’t going to be so accommodating. Each time you add a loop or condition to a method, you increase the number of possible paths a caller might take. Consider this modified version of our earlier example:
1 2 3 4 | public static int plus(boolean t, int a, int b) { int c = t ? a : b; return c;} |
Now we have control flow to complicate things; if try to perform the same assignments as before, we run into a problem.
| Bytecode | Stack Variables | |
|---|---|---|
| 0 1 4 5 8 9 10 11 | iload_0 ifeq 8 iload_1 goto 9 iload_2 istore_3 iload_3 ireturn | s0 = v0 if (s0 == 0) goto #8 s1 = v1 goto #9 s2 = v2 v3 = {s1,s2} s4 = v3 return s4 |
We need to be a little smarter about how we assign our stack identifiers. It’s no longer sufficient to consider each instruction on its own; we need to keep track of how the stack looks at any given location, because there are multiple paths we might take to get there.
When we examine #9, we see that istore_3 pops a single value, but that value has two sources: it might have originated at either #5 or #8. The value at the top of the stack at #9 might be either s1 or s2, depending on whether we came from #5 or #8, respectively. Therefore, we need to consider these to be the same variable—we merge them, and all references to s1 or s2 become references to the unambiguous variable s{1,2}. After this ‘relabeling’, we can safely perform copy propagation.
| After Relabeling | After Copy Propagation | |
|---|---|---|
| 0 1 4 5 8 9 10 11 | s0 = v0 if (s0 == 0) goto #8 s{1,2} = v1 goto #9 s{1,2} = :v2 v3 = s{1,2} s4 = v3 return s4 | if (v0 == 0) goto #8 s{1,2} = v1 goto #9 s{1,2} = v2 v3 = s{1,2}return v3 |
Notice the conditional branch at #1: if the value of s0 is zero, we jump to the else block; otherwise, we continue along the current path. It’s interesting to note that the test condition is negated when compared to the original source.
We’ve now covered enough to dive into…
Conditional Expressions
At this point, we can determine that our code could be modeled with a ternary operator (?:): we have a conditional, with each branch having a single assignment to the same stack variable s{1,2}, after which the two paths converge.
Once we’ve identified this pattern, we can roll the ternary up straight away.
| After Copy Prop. | Collapse Ternary | |
|---|---|---|
| 0 1 4 5 8 9 10 11 | if (v0 == 0) goto #8 s{1,2} = v1 goto 9 s{1,2} = v2 v3 = s{1,2}return v3 | v3 = v0 != 0 ? v1 : v2 return v3 |
Note that, as part of the transformation, we negated the condition at #9. It turns out that javac is fairly predictable in how it negates conditions, so we can more closely matche the original source if we flip those conditions back.
Aside – But what are the types?
When dealing with stack values, the JVM uses a more simplistic type system than Java source. Specifically, boolean, char, and short values are manipulated using the same instructions as int values. Thus, the comparison v0 != 0 could be interpreted as either:
1 | v0 != false ? v1 : v2 |
…or:
1 | v0 != 0 ? v1 : v2 |
…or even:
1 | v0 != false ? v1 == true : v2 == true |
…and so on!
In this case, however, we are fortunate to know the exact type of v0, as it is contained within the method descriptor:
1 2 | descriptor: (ZII)I flags: ACC_PUBLIC, ACC_STATIC |
This tells us the method signature is of the form:
1 | public static int plus(boolean, int, int) |
We can also infer that v3 should be an int (as opposed to a boolean) because it is used as the return value, and the descriptor tells us the return type. We are then left with:
1 2 | v3 = v0 ? v1 : v2return v3 |
As an aside, if v0 were a local variable (and not a formal parameter) then we might not know it represents a boolean value and not an int. Remember that local variable table we mentioned earlier, which tells us the original variable names? It also includes information about the variable types, so if your compiler is configured to emit debug information, we can look to that table for type hints. There is another, similar table called LocalVariableTypeTable that contains similar information; the key difference is that a LocalVariableTypeTable may include detailed information about generic types, whereas a LocalVariableTable cannot. It’s worth noting that these tables are unverified metadata, so they are not necessarily trustworthy. A particularly devious obfuscator might choose to fill these tables with lies, and the resulting bytecode would still be valid! Use them at your own discretion.
Short-Circuit Operators ('&&' and '||')
1 2 3 | public static boolean fn(boolean a, boolean b, boolean c){ return a || b && c;} |
How could anything be simpler? The bytecode is, unfortunately, a bit of a pain…
| Bytecode | Stack Variables | After Copy Propagation | |
|---|---|---|---|
| 0 1 4 5 8 9 12 13 16 17 | iload_0 ifne #12 iload_1 ifeq #16 iload_2 ifeq #16 iconst_1 goto #17 iconst_0 ireturn | s0 = v0 if (s0 != 0) goto #12 s1 = v1 if (s1 == 0) goto #16 s2 = v2 if (s2 == 0) goto #16 s3 = 1 goto 17 s4 = 0 return s{3,4} | if (v0 != 0) goto #12if (v1 == 0) goto #16 if (v2 == 0) goto #16 |
The ireturn instruction at #17 could return either s3 or s4, depending on what path is taken. We alias them as described above, and then we perform copy propagation to eliminate s0, s1, and s2.
We are left with three consecutive conditionals at #1, #5 and #7. As we mentioned earlier, conditional branches either jump or fall through to the next instruction.
The bytecode above contains sequences of conditional branches that follow specific and very useful patterns:
| Conditional Conjunction (&&) | Conditional Disjunction (||) | ||||
|---|---|---|---|---|---|
|
|
If we consider neighbouring pairs of conditionals above, #1...#5 do not conform to either of these patterns, but #5...#9 is a conditional disjunction (||), so we apply the appropriate transformation:
1 2 3 4 5 6 | 1: if (v0 != 0) goto #12 5: if (v1 == 0 || v2 == 0) goto #1612: s{3,4} = 113: goto #1716: s{3,4} = 017: return s{3,4} |
Note that every transform we apply might create opportunities to perform additional transforms. In this case, applying the || transform restructured our conditions, and now #1...#5 conform to the && pattern! Thus, we can further simplify the method by combining these lines into a single conditional branch:
1 2 3 4 5 | 1: if (v0 == 0 && (v1 == 0 || v2 == 0)) goto #1612: s{3,4} = 113: goto #1716: s{3,4} = 017: return s{3,4} |
Does this look familiar? It should: this bytecode now conforms to the ternary (?:) operator pattern we covered earlier. We can reduce #1...#16 to a single expression, then use copy propagation to inline s{3,4} into the return statement at #17:
1 | return (v0 == 0 && (v1 == 0 || v2 == 0)) ? 0 : 1; |
Using the method descriptor and local variable type tables described earlier, we can infer all the types necessary to reduce this expression to:
1 | return (v0 == false && (v1 == false || v2 == false)) ? false : true; |
Well, this is certainly more concise than our original decompilation, but it’s still pretty jarring. Let’s see what we can do about that. We can start by collapsing comparisons like x == true and x == false to x and !x, respectively. We can also eliminate the ternary operator by reducing x ? false : true as the simple expression !x.
1 | return !(!v0 && (!v1 || !v2)); |
Better, but it’s still a of a handful. If you remember your high school discrete maths, you can see that De Morgan’s theorem can be applied here:
1 2 | !(a || b) --> (!a) && (!b) !(a && b) --> (!a) || (!b) |
And thus:
1 | return ! ( !v0 && ( !v1 || !v2 ) ) |
…becomes:
1 | return ( v0 || !(!v1 || !v2 ) ) |
…and eventually:
1 | return ( v0 || (v1 && v2) ) |
Hurrah!
Dealing with Method Calls
We’ve already seen what it looks like for a method to be called: arguments ‘arrive’ in the locals array. To call a method, arguments must be pushed onto the stack, following a this pointer in the case of for instance methods). Calling a method in bytecode is as you’d expect:
1 2 3 | push arg_0 push arg_1 invokevirtual METHODREF |
We’ve specified invokevirtual above, which is the instruction used to invoke most instance methods. The JVM actually has a handful of instructions used for method calls, each with different semantics:
invokeinterfaceinvokes interface methods.invokevirtualinvokes instance methods using virtual semantics, i.e., the call is dispatched to the proper override based on the runtime type of the target.invokespecialinvokes invokes a specific instance method (without virtual sematics); it is most commonly used for invoking constructors, but is also used for calls likesuper.method().invokestaticinvokes static methods.invokedynamicis the least common (in Java), and it uses a ‘bootstrap’ method to invoke a custom call site binder. It was created to improve support for dynamic languages, and has been used in Java 8 to implement lambdas.
The important detail for a decompiler writer is that the class’s constant pool contains details for any method called, including the number and type of its arguments, as well as its return type. Recording this information in the caller class allows the runtime to verify that the intended method exists at runtime, and that it conforms to the expected signature. If the target method is in third party code, and its signature changes, then any code that attempts to call the old version will throw an error (as opposed to producing undefined behavior).
Going back to our example above, the presence of the invokevirtual opcode tells us that the target method is an instance method, and therefore requires a this pointer as an implicit first argument. The METHODREF in the constant pool tells us that the method has one formal parameter, so we know we need to pop an argument off of the stack in addition to the target instance pointer. We can then rewrite the code as:
1 | arg_0.METHODREF(arg_1) |
Of course, bytecode isn’t always so friendly; there’s no requirement that stack arguments be pushed neatly onto the stack, one after the other. If, for example, one of the arguments was a ternary expression, then there would be intermediate load, store, and branch instructions that will need to be transformed independently. Obfuscators might rewrite methods into a particularly convoluted sequence of instructions. A good decompiler will need to be flexible enough to handle many interesting edge cases that are beyond the scope of this article.
There has to be more to it than this…
So far, we’ve limited ourselves to analyzing a single sequence of code, beginning with a list of simple instructions and applying transformations that produce more familiar, higher-level constructs. If you are thinking that this seems a little too simplistic, then you are correct. Java is a highly structured language with concepts like scopes and blocks, as well as more complicated control flow mechanisms. In order to deal with constructs like if/else blocks and loops, we need to perform a more rigorous analysis of the code, paying special attention to the various paths that might be taken. This is called control flow analysis.
We begin by breaking down our code into contiguous blocks that are guaranteed to execute from beginning to end. These are called basic blocks, and we construct them by splitting up our instruction list along places where we might jump to another block, as well as any instructions which might be jump targets themselves.
We then build up a control flow graph (CFG) by creating edges between the blocks to represent all possible branches. Note that these edges may not be explicit branches; blocks containing instructions that might throw exceptions will be connected to their respective exception handlers. We won’t go into detail about constructing CFGs, but some high level knowledge is required to understand how we use these graphs to detect code constructs like loops.
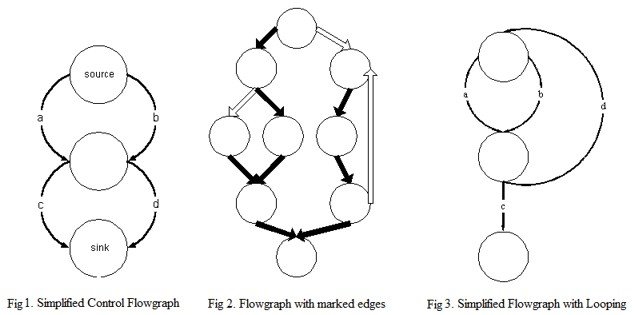
Examples of control flow graphs.
The aspects of control flow graphs that we are most interested in are domination relationships:
- A node
Dis said to dominate another nodeNif all paths toNpass throughD. All nodes dominate themselves; ifDandNare different nodes, thenDis said to strictly dominateN. - If
Dstrictly dominatesNand does not strictly dominate any other node that strictly dominatesN, thenDcan be said to immediately dominateN. - The dominator tree is a tree of nodes in which each node’s children are the nodes it immediately dominates.
- The dominance frontier of
Dis the set of all nodesNsuch thatDdominates an immediate predecessor ofNbut does not strictly dominateN. In other words, it is the set of nodes whereD‘s dominance ends.
Basic Loops and Control Flow
Consider the following Java method:
1 2 3 4 5 | public static void fn(int n) { for (int i = 0; i < n; ++i) { System.out.println(i); }} |
…and its disassembly:
01 02 03 04 05 06 07 08 09 10 11 | 0: iconst_0 1: istore_1 2: iload_1 3: iload_0 4: if_icmpge 20 7: getstatic #2 // System.out:PrintStream10: iload_111: invokevirtual #3 // PrintStream.println:(I)V14: iinc 1, 117: goto 220: return |
Let’s apply what we discussed above to convert this into a more readable form, first by introducing stack variables, then performing copy propagation.
| Bytecode | Stack Variables | After Copy Propagation | |
|---|---|---|---|
| 0 1 2 3 4 7 10 11 14 17 20 | iconst_0 istore_1 iload_1 iload_0 if_icmpge 20 getstatic #2 iload_1 invokevirtual #3 iinc 1, 1 goto 2 return | s0 = 0 v1 = s0 s2 = v1 s3 = v0 if (s2 >= s3) goto 20 s4 = System.out s5 = v1 s4.println(s5) v1 = v1 + 1 goto 2 return | v1 = 0if (v1 >= v0) goto 20 System.out.println(v1) |
Notice how the conditional branch at #4 and the goto at #17 create a logical loop. We can see this more easily by looking at a control flow graph:
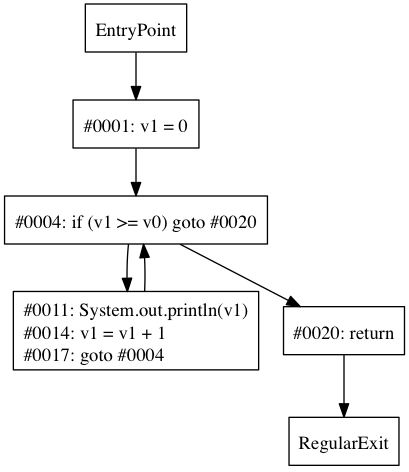
From the graph, it’s obvious that we have a neat cycle, with an edge from the goto back to a conditional branch. In this case, the conditional branch is referred to as a loop header, which can be defined as a dominator with a loop-forming backward edge. A loop header dominates all nodes within the loop’s body.
We can determine whether a condition is a loop header by looking for a loop-forming back edge, but how do we do that? A simple solution is to test whether the condition node is in its own dominance frontier. Once we know we have a loop header, we have to figure out which nodes to pull into the loop body; we can do that by finding all nodes dominated by the header. In pseudocode, our algorithm would look something like this:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 | findDominatedNodes(header) q := new Queue() r := new Set() q.enqueue(header) while (not q.empty()) n := q.dequeue() if (header.dominates(n)) r.add(n) for (s in n.successors()) q.enqueue(n) return r |
Once we’ve figured out the loop body, we can transform our code into a loop. Keep in mind that our loop header may be a conditional jump out of the loop, in which case we need to negate the condition.
1 2 3 4 5 6 | v1 = 0while (v1 < v0) { System.out.println(v1) v1 = v1 + 1}return |
And voila, we have a simple pre-condition loop! Most loops, including while, for and for-each, compile down to the same basic pattern, which we detect as a simple while loop. There’s no way to know for sure what kind of loop the programmer originally wrote, but for and for-each follow pretty specific patterns that we can look for. We won’t go into the details, but if you look at the while loop above, you can see how the original for loop’s initializer (v1 = 0) precedes the loop, and its iterator (v1 = v1 + 1) has been inserted at the end of the loop body. We’ll leave it as an exercise to think about when and how one might transform while loops into for or for-each. It’s also interesting to think about how we might have to adjust our logic to detect post-conditional (do/while) loops.
We can apply a similar technique to decompile if/else statements. The bytecode pattern is pretty straightforward:
01 02 03 04 05 06 07 08 09 10 11 12 | begin: iftrue(!condition) goto #else // `if` block begins here ... goto #endelse: // `else` block begins here ...end: // end of `if/else` |
Here, we use iftrue as a pseudo-instruction to represent any conditional branch: test a condition, and if it passes, then branch; otherwise, continue. We know that the if block starts at the instruction following the condition, and the else block starts at the condition’s jump target. Finding the contents of those blocks is as simple as finding the nodes dominated by those starting nodes, which we can do using the same algorithm we described above.
We’ve now covered basic control flow mechanisms, and while there are others (e.g., exception handlers and subroutines), those are beyond the scope of this introductory article.
Wrap-Up
Writing a decompiler is no simple task, and the experience easily translates into a book’s worth of material—perhaps even a series of books! Obviously, we could not cover everything in a single blog post, and you probably wouldn’t want to read it if we’d tried. We hope that by touching on the most common constructs—logical operators, conditionals, and basic control flow—we have given you an interesting glimpse into the world of decompiler development.
Lee Benfield is the author of the CFR Java decompiler.
Mike Strobel is the author of Procyon, a Java decompiler and metaprogramming framework.
Now go write your own! :)

This article should be credited to Mike Strobel and Lee Benfield, not Attila Mihaly Balazs (who merely hosted the article). Please correct it.
Thanks!
Mike
Hi,
thank you for the article and the software itself!
Now both Procyon and CFR Java decompilers are available in the cloud: http://www.javadecompilers.com/