This post demonstrates a Groovy script for uncompressing files with the 7-Zip archive format. The two primary objectives of this post are to demonstrate uncompressing 7-Zip files with Groovy and the handy 7-Zip-JBinding and to call out and demonstrate some key characteristics of Groovy as a scripting language.
The 7-Zip page describes 7-Zip as “a file archiver with a high compression ratio.” The page further adds, “7-Zip is open source software. Most of the source code is under the GNU LGPL license.” More license information in available on the site along with information on the 7z format (“LZMA is default and general compression method of 7z format”).
The 7-Zip page describes it as “a Java wrapper for 7-Zip C++ library” that “allows extraction of many archive formats using a very fast native library directly from Java through JNI.” The 7z format is based on “LZMA and LZMA2 compression.” Although there is an LZMA SDK available, it is easier to use the open source (SourceForge) 7-Zip-JBinding project when manipulating 7-Zip files with Java.
A good example of using Java with 7-Zip-JBinding to uncompress 7z files is available in the StackOverflow thread Decompress files with .7z extension in java. Dark Knight‘s response indicates how to use Java with 7-Zip-JBinding to uncompress a 7z file. I adapt Dark Knight’s Java code into a Groovy script in this post.
To demonstrate the adapted Groovy code for uncompressing 7z files, I first need a 7z file that I can extract contents from. The next series of screen snapshots show me using Windows 7-Zip installed on my laptop to compress the six PDFs available under the Guava Downloads page into a single 7z file called Guava.7z.
Six Guava PDFs Sitting in a Folder
Contents Selected and Right-Click Menu to Compress to 7z Format
Guava.7z Compressed Archive File Created
With a 7z file in place, I now turn to the adapted Groovy script that will extract the contents of this Guava.7z file. As mentioned previously, this Groovy script is an adaptation of the Java code provided by Dark Knight on a StackOverflow thread.
unzip7z.groovy
//
// This Groovy script is adapted from Java code provided at
// http://stackoverflow.com/a/19403933
import static java.lang.System.err as error
import java.io.File
import java.io.FileNotFoundException
import java.io.FileOutputStream
import java.io.IOException
import java.io.RandomAccessFile
import java.util.Arrays
import net.sf.sevenzipjbinding.ExtractOperationResult
import net.sf.sevenzipjbinding.ISequentialOutStream
import net.sf.sevenzipjbinding.ISevenZipInArchive
import net.sf.sevenzipjbinding.SevenZip
import net.sf.sevenzipjbinding.SevenZipException
import net.sf.sevenzipjbinding.impl.RandomAccessFileInStream
import net.sf.sevenzipjbinding.simple.ISimpleInArchive
import net.sf.sevenzipjbinding.simple.ISimpleInArchiveItem
if (args.length < 1)
{
println "USAGE: unzip7z.groovy <fileToUnzip>.7z\n"
System.exit(-1)
}
def fileToUnzip = args[0]
try
{
RandomAccessFile randomAccessFile = new RandomAccessFile(fileToUnzip, "r")
ISevenZipInArchive inArchive = SevenZip.openInArchive(null, new RandomAccessFileInStream(randomAccessFile))
ISimpleInArchive simpleInArchive = inArchive.getSimpleInterface()
println "${'Hash'.center(10)}|${'Size'.center(12)}|${'Filename'.center(10)}"
println "${'-'.multiply(10)}+${'-'.multiply(12)}+${'-'.multiply(10)}"
simpleInArchive.getArchiveItems().each
{ item ->
final int[] hash = new int[1]
if (!item.isFolder())
{
final long[] sizeArray = new long[1]
ExtractOperationResult result = item.extractSlow(
new ISequentialOutStream()
{
public int write(byte[] data) throws SevenZipException
{
//Write to file
try
{
File file = new File(item.getPath())
file.getParentFile()?.mkdirs()
FileOutputStream fos = new FileOutputStream(file)
fos.write(data)
fos.close()
}
catch (Exception e)
{
printExceptionStackTrace("Unable to write file", e)
}
hash[0] ^= Arrays.hashCode(data) // Consume data
sizeArray[0] += data.length
return data.length // Return amount of consumed data
}
})
if (result == ExtractOperationResult.OK)
{
println(String.format("%9X | %10s | %s",
hash[0], sizeArray[0], item.getPath()))
}
else
{
error.println("Error extracting item: " + result)
}
}
}
}
catch (Exception e)
{
printExceptionStackTrace("Error occurs", e)
System.exit(1)
}
finally
{
if (inArchive != null)
{
try
{
inArchive.close()
}
catch (SevenZipException e)
{
printExceptionStackTrace("Error closing archive", e)
}
}
if (randomAccessFile != null)
{
try
{
randomAccessFile.close()
}
catch (IOException e)
{
printExceptionStackTrace("Error closing file", e)
}
}
}
/**
* Prints the stack trace of the provided exception to standard error without
* Groovy meta data trace elements.
*
* @param contextMessage String message to precede stack trace and provide context.
* @param exceptionToBePrinted Exception whose Groovy-less stack trace should
* be printed to standard error.
* @return Exception derived from the provided Exception but without Groovy
* meta data calls.
*/
def Exception printExceptionStackTrace(
final String contextMessage, final Exception exceptionToBePrinted)
{
error.print "${contextMessage}: ${org.codehaus.groovy.runtime.StackTraceUtils.sanitize(exceptionToBePrinted).printStackTrace()}"
}In my adaptation of the Java code into the Groovy script shown above, I left most of the exception handling in place. Although Groovy allows exceptions to be ignored whether they are checked or unchecked, I wanted to maintain this handling in this case to make sure resources are closed properly and that appropriate error messages are presented to users of the script.
One thing I did change was to make all of the output that is error-related be printed to standard error rather than to standard output. This required a few changes. First, I used Groovy’s capability to rename something that is statically imported (see my related post Groovier Static Imports) to reference “java.lang.System.err” as “error” so that I could simply use “error” as a handle in the script rather than needing to use “System.err” to access standard error for output.
Because Throwable.printStackTrace() already writes to standard error rather than standard output, I just used it directly. However, I placed calls to it in a new method that would first run StackTraceUtils.sanitize(Throwable) to remove Groovy-specific calls associated with Groovy’s runtime dynamic capabilities from the stack trace.
There were some other minor changes to the script as part of making it Groovier. I used Groovy’s iteration on the items in the archive file rather than the Java for loop, removed semicolons at the ends of statements, used Groovy’s String GDK extension for more controlled output reporting [to automatically center titles and to multiply a given character by the appropriate number of times it needs to exist], and took advantage of Groovy’s implicit inclusion of args to add a check to ensure file for extraction was provided to the script.
With the file to be extracted in place and the Groovy script to do the extracting ready, it is time to extract the contents of the Guava.7z file I demonstrated generating earlier in this post. The following command will run the script and places the appropriate 7-Zip-JBinding JAR files on the classpath.
groovy -classpath "C:/sevenzipjbinding/lib/sevenzipjbinding.jar;C:/sevenzipjbinding/lib/sevenzipjbinding-Windows-x86.jar" unzip7z.groovy C:\Users\Dustin\Downloads\Guava\Guava.7z
Before showing the output of running the above script against the indicated Guava.7z file, it is important to note the error message that will occur if the native operating system specific 7-Zip-JBinding JAR (sevenzipjbinding-Windows-x86.jar in my laptop’s case) is not included on the classpath of the script.
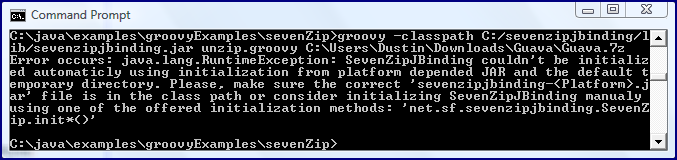
As the last screen snapshot indicates, neglecting to include the native JAR on the classpath leads to the error message: “Error occurs: java.lang.RuntimeException: SevenZipJBinding couldn’t be initialized automaticly using initialization from platform depended JAR and the default temporary directory. Please, make sure the correct ‘sevenzipjbinding-
.jar’ file is in the class path or consider initializing SevenZipJBinding manualy using one of the offered initialization methods: ‘net.sf.sevenzipjbinding.SevenZip.init*()'”
Although I simply added C:/sevenzipjbinding/lib/sevenzipjbinding-Windows-x86.jar to my script’s classpath to make it work on this laptop, a more robust script might detect the operating system and apply the appropriate JAR to the classpath for that operating system. The 7-Zip-JBinding Download page features multiple platform-specific downloads (including platform-specific JARs) such as sevenzipjbinding-4.65-1.06-rc-extr-only-Windows-amd64.zip, sevenzipjbinding-4.65-1.06-rc-extr-only-Mac-x86_64.zip, sevenzipjbinding-4.65-1.06-rc-extr-only-Mac-i386.zip, and sevenzipjbinding-4.65-1.06-rc-extr-only-Linux-i386.zip.
Once the native 7-Zip-JBinding JAR is included on the classpath along with the core sevenzipjbinding.jar JAR, the script runs beautifully as shown in the next screen snapshot.
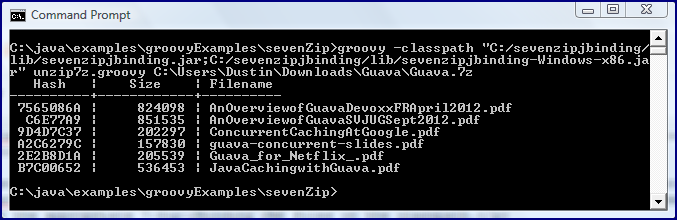
The script extracts the contents of the 7z file into the same working directory as the Groovy script. A further enhancement would be to modify the script to accept a directory to which to write the extracted files or might write them to the same directory as the 7z archive file by default instead. Use of Groovy’s built-in CLIBuilder support could also improve the script.
Groovy is my preferred language of choice when scripting something that makes use of the JVM and/or of Java libraries and frameworks. Writing the script that is the subject of this post has been another reminder of that.
