Introduction
This is the third part of our MongoDB time series tutorial, and this post will emphasize the importance of data modelling. You might want to check the first part of this series, to get familiar with our virtual project requirements and the second part talking about common optimization techniques.
When you first start using MongoDB, you’ll immediately notice it’s schema-less data model. But schema-less doesn’t mean skipping proper data modelling (satisfying your application business and performance requirements). As opposed to a SQL database, a NoSQL document model is more focused towards querying than to data normalization. That’s why your design won’t be finished unless it addresses your data querying patterns.
The new data model
Our previous time event was modeled like this:
{
"_id" : ObjectId("52cb898bed4bd6c24ae06a9e"),
"created_on" : ISODate("2012-11-02T01:23:54.010Z")
"value" : 0.19186609564349055
}We concluded that the ObjectId is working against us, since its index size is about 1.4GB and our data aggregation logic doesn’t use it at all. The only true benefit, for having it, comes from the possibility of using bulk inserts.
The previous solution was using a Date field for storing the event creation timestamp. This affected the aggregation grouping logic, which ended up with the following structure:
"_id" : {
"year" : {
"$year" : [
"$created_on"
]
},
"dayOfYear" : {
"$dayOfYear" : [
"$created_on"
]
},
"hour" : {
"$hour" : [
"$created_on"
]
},
"minute" : {
"$minute" : [
"$created_on"
]
},
"second" : {
"$second" : [
"$created_on"
]
}
}This group _id requires some application logic for obtaining a proper JSON Date. We can also change the created_on Date field to a numeric value, representing the number of milliseconds since Unix epoch. This can become our new document _id (which is indexed by default anyway).
This is how our new document structure will look like:
{
"_id" : 1346895603146,
"values" : [ 0.3992688732687384 ]
}
{
"_id" : 1348436178673,
"values" : [
0.7518879524432123,
0.0017396819312125444
]
}Now, we can easily extract a timestamp reference (pointing to the current second, minute, hour or day) from a Unix timestamp.
So, if the current timestamp is 1346895603146 (Thu, 06 Sep 2012 01:40:03 146ms GMT), we can extract:
- the current second time point [Thu, 06 Sep 2012 01:40:03 GMT]: 1346895603000 = (1346895603146 – (1346895603146 % 1000)) - the current minute time point [Thu, 06 Sep 2012 01:40:00 GMT] : 1346895600000 = (1346895603146 – (1346895603146 % (60 * 1000))) - the current hour time point [Thu, 06 Sep 2012 01:00:00 GMT] : 1346893200000 = (1346895603146 – (1346895603146 % (60 * 60 * 1000))) - the current day time point [Thu, 06 Sep 2012 00:00:00 GMT] : 1346889600000= (1346895603146 – (1346895603146 % (24 * 60 * 60 * 1000)))
The algorithm is quite straightforward and we can employ it when calculating the aggregation group identifier.
This new data model allows us to have one document per timestamp. Each time-event appends a new value to the “values” array, so two events, happening at the very same instant, will share the same MongoDB document.
Inserting test data
All these changes require altering the import script we’ve used previously. This time we can’t use a batch insert, and we will take a more real-life approach. This time, we’ll use a non-batched upsert like in the following script:
var minDate = new Date(2012, 0, 1, 0, 0, 0, 0);
var maxDate = new Date(2013, 0, 1, 0, 0, 0, 0);
var delta = maxDate.getTime() - minDate.getTime();
var job_id = arg2;
var documentNumber = arg1;
var batchNumber = 5 * 1000;
var job_name = 'Job#' + job_id
var start = new Date();
var index = 0;
while(index < documentNumber) {
var date = new Date(minDate.getTime() + Math.random() * delta);
var value = Math.random();
db.randomData.update( { _id: date.getTime() }, { $push: { values: value } }, true );
index++;
if(index % 100000 == 0) {
print(job_name + ' inserted ' + index + ' documents.');
}
}
print(job_name + ' inserted ' + documentNumber + ' in ' + (new Date() - start)/1000.0 + 's');Now it’s time to insert the 50M documents.
Job#1 inserted 49900000 documents. Job#1 inserted 50000000 documents. Job#1 inserted 50000000 in 4265.45s
Inserting 50M entries is slower than the previous version, but we can still get 10k inserts per second without any write optimization. For the purpose of this test, we will assume that 10 events per millisecond is enough, considering that at such rate we will eventually have 315 billion documents a year.
Compacting data
Now, let’s check the new collection stats:
db.randomData.stats();
{
"ns" : "random.randomData",
"count" : 49709803,
"size" : 2190722612,
"avgObjSize" : 44.070233229449734,
"storageSize" : 3582234624,
"numExtents" : 24,
"nindexes" : 1,
"lastExtentSize" : 931495936,
"paddingFactor" : 1.0000000000429572,
"systemFlags" : 1,
"userFlags" : 0,
"totalIndexSize" : 1853270272,
"indexSizes" : {
"_id_" : 1853270272
},
"ok" : 1
}The document size has reduced from 64 to 44 bytes, and this time we only have one index. We can reduce the collection size even further if using the compact command.
db.randomData.runCommand("compact");
{
"ns" : "random.randomData",
"count" : 49709803,
"size" : 2190709456,
"avgObjSize" : 44.06996857340191,
"storageSize" : 3267653632,
"numExtents" : 23,
"nindexes" : 1,
"lastExtentSize" : 851263488,
"paddingFactor" : 1.0000000000429572,
"systemFlags" : 1,
"userFlags" : 0,
"totalIndexSize" : 1250568256,
"indexSizes" : {
"_id_" : 1250568256
},
"ok" : 1
}The base aggregation script
Now it’s time to build the base aggregation script:
function printResult(dataSet) {
dataSet.result.forEach(function(document) {
printjson(document);
});
}
function aggregateData(fromDate, toDate, groupDeltaMillis, enablePrintResult) {
print("Aggregating from " + fromDate + " to " + toDate);
var start = new Date();
var pipeline = [
{
$match:{
"_id":{
$gte: fromDate.getTime(),
$lt : toDate.getTime()
}
}
},
{
$unwind:"$values"
},
{
$project:{
timestamp:{
$subtract:[
"$_id", {
$mod:[
"$_id", groupDeltaMillis
]
}
]
},
value : "$values"
}
},
{
$group: {
"_id": {
"timestamp" : "$timestamp"
},
"count": {
$sum: 1
},
"avg": {
$avg: "$value"
},
"min": {
$min: "$value"
},
"max": {
$max: "$value"
}
}
},
{
$sort: {
"_id.timestamp" : 1
}
}
];
var dataSet = db.randomData.aggregate(pipeline);
var aggregationDuration = (new Date().getTime() - start.getTime())/1000;
print("Aggregation took:" + aggregationDuration + "s");
if(dataSet.result != null && dataSet.result.length > 0) {
print("Fetched :" + dataSet.result.length + " documents.");
if(enablePrintResult) {
printResult(dataSet);
}
}
var aggregationAndFetchDuration = (new Date().getTime() - start.getTime())/1000;
if(enablePrintResult) {
print("Aggregation and fetch took:" + aggregationAndFetchDuration + "s");
}
return {
aggregationDuration : aggregationDuration,
aggregationAndFetchDuration : aggregationAndFetchDuration
};
}Testing the new data model
We’ll simply reuse the test framework we’ve built previously and we are interested in checking two use-cases:
- preloading data and indexes
- preloading the working set
Pre-loading data and indexes
D:\wrk\vladmihalcea\vladmihalcea.wordpress.com\mongodb-facts\aggregator\timeseries>mongo random touch_index_data.js
MongoDB shell version: 2.4.6
connecting to: random
Touch {data: true, index: true} took 17.351s| Type | seconds in a minute | minutes in an hour | hours in a day |
|---|---|---|---|
| T1 | 0.012s | 0.044s | 0.99s |
| T2 | 0.002s | 0.044s | 0.964s |
| T3 | 0.001s | 0.043s | 0.947s |
| T4 | 0.001s | 0.043s | 0.936s |
| T4 | 0.001s | 0.043s | 0.907s |
| Average | 0.0034s | 0.0433s | 0.9488s |
Compared to our previous version, we got better results and that was possible because we could now preload both data and indexes, instead of just data. The whole data and indexes fit our 8GB RAM:
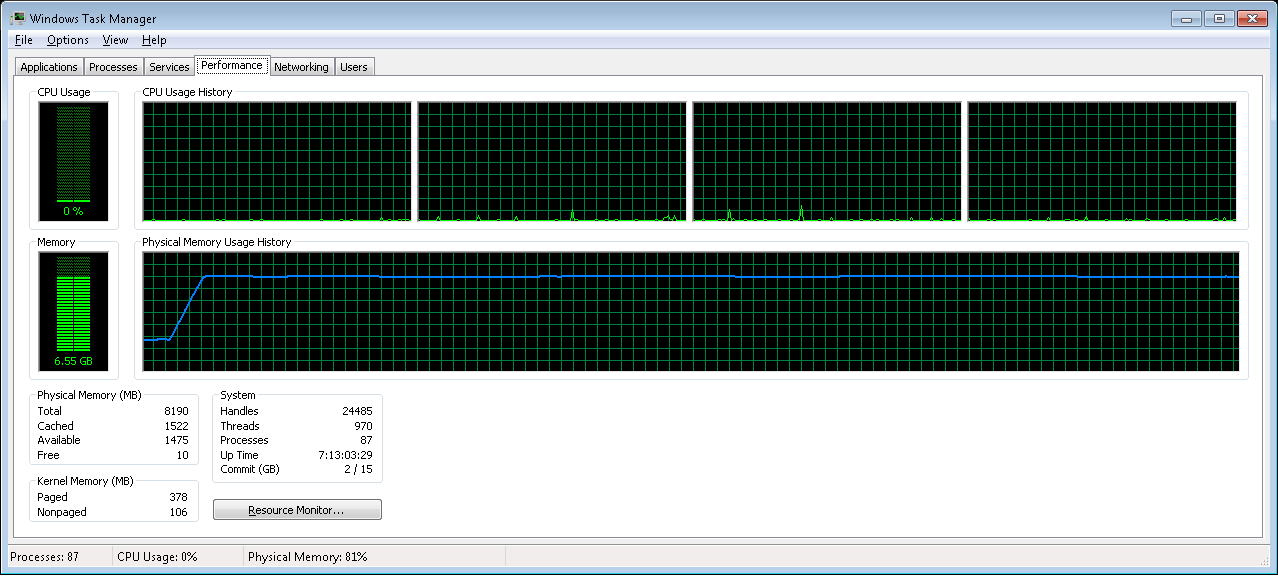
Pre-loading the working set
D:\wrk\vladmihalcea\vladmihalcea.wordpress.com\mongodb-facts\aggregator\timeseries>mongo random compacted_aggregate_year_report.js MongoDB shell version: 2.4.6 connecting to: random Aggregating from Sun Jan 01 2012 02:00:00 GMT+0200 (GTB Standard Time) to Tue Jan 01 2013 02:00:00 GMT+0200 (GTB Standard Time) Aggregation took:307.84s Fetched :366 documents.
| Type | seconds in a minute | minutes in an hour | hours in a day |
|---|---|---|---|
| T1 | 0.003s | 0.037s | 0.855s |
| T2 | 0.002s | 0.037s | 0.834s |
| T3 | 0.001s | 0.037s | 0.835s |
| T4 | 0.001s | 0.036s | 0.84s |
| T4 | 0.002s | 0.036s | 0.851s |
| Average | 0.0018s | 0.0366s | 0.843s |
This is the best result we’ve got and we can settle with this new data model, since it’s already satisfying our virtual project performance requirements.
Conclusion
Is this fast or is it slow?
This is a question you’ll have to answer yourself. Performance is a context bounded function. What’s fast for a given business case may be extremely slow for another.
There is one thing for sure. It’s almost six times faster than my out-of-the-box version.
These numbers are not meant to be compared against any other NoSQL or SQL alternative. They are only useful when comparing a prototype version to an optimized data model alternative, so we can learn how data modelling affects the overall application performance.
- Code available on GitHub.
