DSLs are cool things, but it wasn’t clear to me what they were good for.
Then I realized they are good for:
- get rid of complex UIs
which means
- faster way to do things
That’s it. I’ve came to this conclusion when I read this blog.
If your user is techie and are not afraid of a SQL-like syntax way of doing things, DSLs are great specially if
- you have syntax highlight
- you have code completion
Otherwise, DSLs kinda sucks.
So, I had to present some proof of concept to a client. He has fuzzy requirements and it’s not easy to extract exactly what his team needs (they need a lot of things and he’s very busy), so a DSL can help a lot in this process because people are forced to think exactly what they need when they face a grammar (even a small one).
So I went with these technologies:
- JSF library Primefaces extensions for code mirror
- ANTLR4 (big improvement over ANTLR3, and the book is great)
Unfortunately, I could not reuse the grammar in both tools. Actually, I could not find any solution that could do that. At least for a web-based JSF solution. And there was no time to learn. So I had to hack a little.
First, we need the grammar. ANTLR4 is way better than ANTLR3 because now the wiring code is done via visitors and listeners. No more java code inside the grammar. That’s great and much easier to work with.
So you can have a grammar like this
grammar Grammar;
options
{
language = Java;
}
@lexer::header {
package parsers;
}
@parser::header {
package parsers;
}
eval : expr EOF;
expr : 'JOB' (jobName)? type 'TARGET' targetList ('START' startExpr)?
startExpr
: 'AT' cronTerm
| 'AFTER' timeAmount timeUnits;
timeAmount: INT;
jobName: STRING;
targetList: STRING (',' STRING)*;
type : deleteUser
| createUser;
deleteUser: opDelete userName;
createUser: opCreate userName;
opDelete: 'DELETE';
opCreate: 'CREATE';
userName: STRING;
cronTerm: '!'? (INT | '-' | '/' | '*' | '>' | '<')+;
timeUnits
: 'MINUTES'
| 'HOURS'
| 'DAYS'
| 'WEEKS'
| 'MONTHS';
WS : [ \t\r\n]+ -> skip;
STRING
: '"' ( ESC_SEQ | ~('\\'|'"') )* '"'
;
fragment
HEX_DIGIT : ('0'..'9'|'a'..'f'|'A'..'F') ;
fragment
ESC_SEQ
: '\\' ('b'|'t'|'n'|'f'|'r'|'\"'|'\''|'\\')
| UNICODE_ESC
| OCTAL_ESC
;
fragment
OCTAL_ESC
: '\\' ('0'..'3') ('0'..'7') ('0'..'7')
| '\\' ('0'..'7') ('0'..'7')
| '\\' ('0'..'7')
;
fragment
UNICODE_ESC
: '\\' 'u' HEX_DIGIT HEX_DIGIT HEX_DIGIT HEX_DIGIT
;
ID : ('a'..'z'|'A'..'Z'|'_') ('a'..'z'|'A'..'Z'|'0'..'9'|'_')*
;
INT : '0'..'9'+
;
To compile your grammar, try
public static void main(String[] args) {
String[] arg0 = {"-visitor","/pathto/Grammar.g4"};
org.antlr.v4.Tool.main(arg0);
}Then ANTLR will generate the classes for you.
In our case, we want to visit the parse tree and retrieve the values we want. We do this extending the generated abstract class.
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.StringTokenizer;
import org.antlr.v4.runtime.tree.ErrorNode;
import bsh.EvalError;
import bsh.Interpreter;
public class MyLoader2 extends GrammarBaseVisitor<Void> {
private String jobName,cronTerm,timeUnits,userName,jobType;
private List<String> targetList;
private boolean now,errorFound;
private int timeAmount;
private Interpreter bsh = new Interpreter();
private String eval(String s) throws EvaluationException{
try {
if (!s.startsWith("\"")){
return s;
}
bsh.eval("String s="+s);
return (String)bsh.eval("s");
} catch (EvalError e) {
throw new EvaluationException(s);
}
}
@Override
public Void visitTimeAmount(TimeAmountContext ctx) {
try{
this.timeAmount = Integer.parseInt(ctx.getText());
}catch(java.lang.NumberFormatException nfe){
throw new InvalidTimeAmountException(ctx.getText());
}
return super.visitTimeAmount(ctx);
}
@Override
public Void visitUserName(UserNameContext ctx) {
this.userName = eval(ctx.getText());
return super.visitUserName(ctx);
}
@Override
public Void visitCronTerm(CronTermContext ctx) {
this.cronTerm = eval(ctx.getText());
return super.visitCronTerm(ctx);
}
@Override
public Void visitTimeUnits(TimeUnitsContext ctx) {
this.timeUnits = ctx.getText();
return super.visitTimeUnits(ctx);
}
@Override
public Void visitTargetList(TargetListContext ctx) {
this.targetList = toStringList(ctx.getText());
return super.visitTargetList(ctx);
}
@Override
public Void visitJobName(JobNameContext ctx) {
this.jobName = eval(ctx.getText());
return super.visitJobName(ctx);
}
@Override
public Void visitOpCreate(OpCreateContext ctx) {
this.jobType = ctx.getText();
return super.visitOpCreate(ctx);
}
@Override
public Void visitOpDelete(OpDeleteContext ctx) {
this.jobType = ctx.getText();
return super.visitOpDelete(ctx);
}
private List<String> toStringList(String text) {
List<String> l = new ArrayList<String>();
StringTokenizer st = new StringTokenizer(text," ,");
while(st.hasMoreElements()){
l.add(eval(st.nextToken()));
}
return l;
}
private Map<String, String> toMapList(String text) throws InvalidItemsException, InvalidKeyvalException {
Map<String, String> m = new HashMap<String, String>();
if (text == null || text.trim().length() == 0){
return m;
}
String[] items = text.split(",");
if (items.length == 0){
throw new InvalidItemsException();
}
for(String item:items){
String[] keyval = item.split("=");
if (keyval.length == 2){
m.put(keyval[0], keyval[1]);
}else{
throw new InvalidKeyvalException(keyval.length);
}
}
return m;
}
public String getJobName() {
return jobName;
}
public String getCronTerm() {
return cronTerm;
}
public String getTimeUnits() {
return timeUnits;
}
public String getUserName() {
return userName;
}
public String getJobType() {
return jobType;
}
public List<String> getTargetList() {
return targetList;
}
public boolean isNow() {
return now;
}
public int getTimeAmount() {
return timeAmount;
}
@Override
public Void visitOpNow(OpNowContext ctx) {
this.now = ctx.getText().equals("NOW");
return super.visitOpNow(ctx);
}
public boolean isErrorFound() {
return errorFound;
}
@Override
public Void visitErrorNode(ErrorNode node) {
this.errorFound = true;
return super.visitErrorNode(node);
}
}Notice the beanshell interpreter being used to evaluate a string like “xyz” to be xyz. This is specially useful for strings that contains escaped quotes and characteres inside.
So, you have your grammar and your visitor / loader bean, then we can test it:
private static MyLoader getLoader(String str){
ANTLRInputStream input = new ANTLRInputStream(str);
GrammarLexer lexer = new GrammarLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
GrammarParser parser = new GrammarParser(tokens);
ParseTree tree = parser.eval();
MyLoader loader = new MyLoader();
loader.visit(tree);
return loader;
}
public static void main(String[] args){
MyLoader loader = getLoader("JOB \"jobName\" CREATE \"myuser\" TARGET \"site1\",\"site2\" START AFTER 1 DAY");
System.out.println(loader.getJobName());
System.out.println(loader.getJobType());
}Great. Now it’s the hack. Code Mirror has support for custom grammars, but it’s not present in the JSF Primefaces extension. So I’ve opened the resources-codemirror-1.2.0.jar, opened the /META-INF/resources/primefaces-extensions/codemirror/mode/modes.js file, formatted it (so I could read it) and I’ve just chosen the simplest language to be my new custom sintax highlighter!
I renamed this one
(...)
}, "xml"), CodeMirror.defineMIME("text/x-markdown", "markdown"), CodeMirror.defineMode("mylanguage", function (e) {
(...)
var t = e.indentUnit,
n, i = r(["site", "type", "targetList"]),
s = r(["AT","AFTER","CREATE","MINUTES","HOURS","TARGET","MONTHS","JOB","DAYS","DELETE","START","WEEKS" ]),
(...)
}), CodeMirror.defineMIME("text/x-mylanguage", "mylanguage"), CodeMirror.defineMode("ntriples", function () {(...) those guys in uppercase in the “s = r” are tokens that will be highlighted, while those one in the “i = r” are tokens that won’t be highlighted. Why do we want both? Because the second type is the “placeholder”, I mean, we’ll use them for the autocomplete stuff.
well, then your JSF xhtml page will look like this
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:f="http://java.sun.com/jsf/core"
xmlns:h="http://java.sun.com/jsf/html"
xmlns:ui="http://java.sun.com/jsf/facelets"
xmlns:p="http://primefaces.org/ui"
xmlns:pe="http://primefaces.org/ui/extensions">
<h:body>
<h:form id="form">
<pe:codeMirror
id="codeMirror"
style="width:600px;"
mode="myLanguage"
widgetVar="myCodeMirror"
theme="eclipse"
value="#{myMB.script}"
lineNumbers="true"
completeMethod="#{myMB.complete}"
extraKeys="{ 'Ctrl-Space': function(cm) { PF('myCodeMirror').complete(); }}"/>
<p:commandButton value="Verify" action="#{myMB.verify}" />
(...)now, we need the autocomplete stuff. It’s the boring part. You have to do most of the completion stuff manually, because there’s no context information (remember, I don’t have time to learn…), so the quick and dirty way to do it is like this
in myMB
public List<String> complete(final CompleteEvent event) {
try {
return this.myEJB.complete(event.getToken());
} catch (Exception e) {
jsfUtilEJB.addErrorMessage(e,"Could not complete");
return null;
}
}
in myEJB
private static final String SITE = "site_";
public List<String> complete(String token) throws Exception {
if (token == null || token.trim().length() == 0){
return null;
}else{
List<String> suggestions = new ArrayList<String>();
switch(token){
//first search variables
case "targetlist":
for(String v:TARGETS){
suggestions.add(v);
}
break;
case "site":
List<Site> allSites = this.baseService.getSiteDAO().getAll();
for(Site s:allSites){
suggestions.add("\""+SITE+s.getName()+"\"");
}
break;
case "type":
suggestions.add("DELETE \"userName\"");
suggestions.add("CREATE \"userName\"");
break;
case "AT":
suggestions.add("AT \"cronExpression\"");
suggestions.add("AT \"0 * * * * * * *\"");
break;
case "AFTER":
for(int a:AMOUNTS){
for(String u:UNITS){
if (a == 1){
suggestions.add("AFTER"+" "+a+" "+u);
}else{
suggestions.add("AFTER"+" "+a+" "+u+"S");
}
}
}
break;
case "TARGET":
for(String v:TARGETS){
suggestions.add("TARGET "+v+"");
}
break;
case "JOB":
suggestions.add("JOB \"jobName\" \ntype \nTARGET targetlist \nSTART");
break;
case "START":
suggestions.add("START AT \"cronExpression\"");
suggestions.add("START AT \"0 * * * * * * *\"");
for(int a:AMOUNTS){
for(String u:UNITS){
if (a == 1){
suggestions.add("START AFTER"+" "+a+" "+u);
}else{
suggestions.add("START AFTER"+" "+a+" "+u+"S");
}
}
}
suggestions.add("START NOW");
break;
case "DELETE":
suggestions.add("DELETE \"userName\"");
break;
case "CREATE":
suggestions.add("CREATE \"userName\"");
break;
default:
if (token.startsWith(SITE)){
List<Site> matchedSites = this.baseService.getSiteDAO().getByPattern(token.substring(SITE.length())+"*");
for(Site s:matchedSites){
suggestions.add("\""+SITE+s.getName()+"\"");
}
}else{
//then search substrings
for(String kw:KEYWORDS){
if (kw.toLowerCase().startsWith(token.toLowerCase())){
suggestions.add(kw);
}
}
}
}//end switch
//remove dups and sort
Set<String> ts = new TreeSet<String>(suggestions);
return new ArrayList<String>(ts);
}
}
private static final int[] AMOUNTS = {1,5,10};
private static final String[] UNITS = {"MINUTE","HOUR","DAY","WEEK","MONTH"};
private static final String[] TARGETS = {"site"};
/*
* KEYWORDS are basic suggestions
*/
private static final String[] KEYWORDS = {"AT","AFTER","CREATE","MINUTES","HOURS","TARGET","MONTHS","JOB","DAYS","DELETE","START","WEEKS"};
so the autocomplete stuff for keywords will just show you fields and more keywords, while the “placeholders” (remember those lowercase keywords in the codemirror javascript from the jar?) are completed with dynamic values retrieved from the DB, for actual values. Also, you can use partial strings to retrieve those ones that start with a substring, like this:
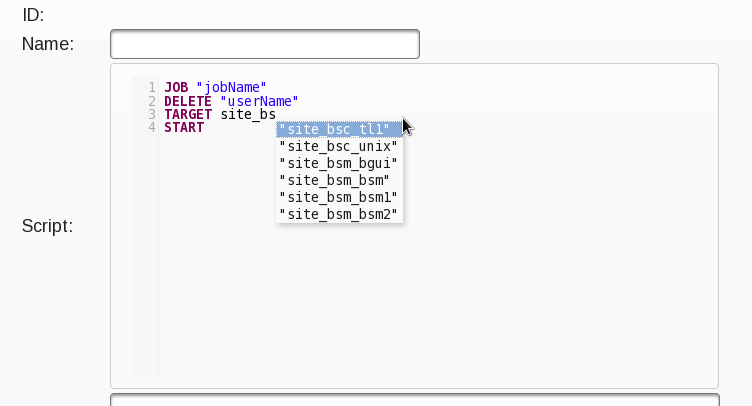
of course, pattern-like searches in JPA can be performed like this:
public abstract class GenericDAO<E> {
protected EntityManager entityManager;
private Class<E> clazz;
private EntityType<E> pClass;
@SuppressWarnings("unchecked")
public GenericDAO(EntityManager entityManager) {
this.entityManager = entityManager;
ParameterizedType genericSuperclass = (ParameterizedType) getClass().getGenericSuperclass();
this.clazz = (Class<E>) genericSuperclass.getActualTypeArguments()[0];
EntityManagerFactory emf = this.entityManager.getEntityManagerFactory();
Metamodel metamodel = emf.getMetamodel();
this.pClass = metamodel.entity(clazz);
}
public List<E> getByPattern(String pattern) {
pattern = pattern.replace("?", "_").replace("*", "%");
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<E> q = cb.createQuery(clazz);
Root<E> entity = q.from(clazz);
SingularAttribute<E, String> singularAttribute = (SingularAttribute<E, String>) pClass.getDeclaredSingularAttribute(getNameableField(clazz));
Path<String> path = entity.get(singularAttribute);
q.where(cb.like(path, pattern));
q.select(entity);
TypedQuery<E> tq = entityManager.createQuery(q);
List<E> all = tq.getResultList();
return all;
}
private String getNameableField(Class<E> clazz) {
for(Field f : clazz.getDeclaredFields()) {
for(Annotation a : f.getAnnotations()) {
if(a.annotationType() == Nameable.class) {
return f.getName();
}
}
}
return null;
}
(...)where Nameable is an annotation for your entity classes:
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.FIELD})
public @interface Nameable {
}
Use it to annotate a single column from your entity class, a String one. Like this:
@Entity
@Table(uniqueConstraints=@UniqueConstraint(columnNames={"name"}))
public class Site implements Serializable {
/**
*
*/
private static final long serialVersionUID = 8008732613898597654L;
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Nameable
@Column(nullable=false)
private String name;
(...)And the “verify” button, of course, just get your script and pushes into the loader.
