Imagine a simple Akka actor system consisting of two parties: MonitoringActor and NetworkActor. Whenever someone (client) sends CheckHealth to the former one it asks the latter by sending Ping. NetworkActor is obligated to reply with Pong as soon as possible (scenario [A]). Once MonitoringActor receives such a reply it immediately replies to the client with Up status message. However MonitoringActor is obligated to send Down reply if NetworkActor failed to respond with Pong within one second (scenario [B]). Both workflows are depicted below:
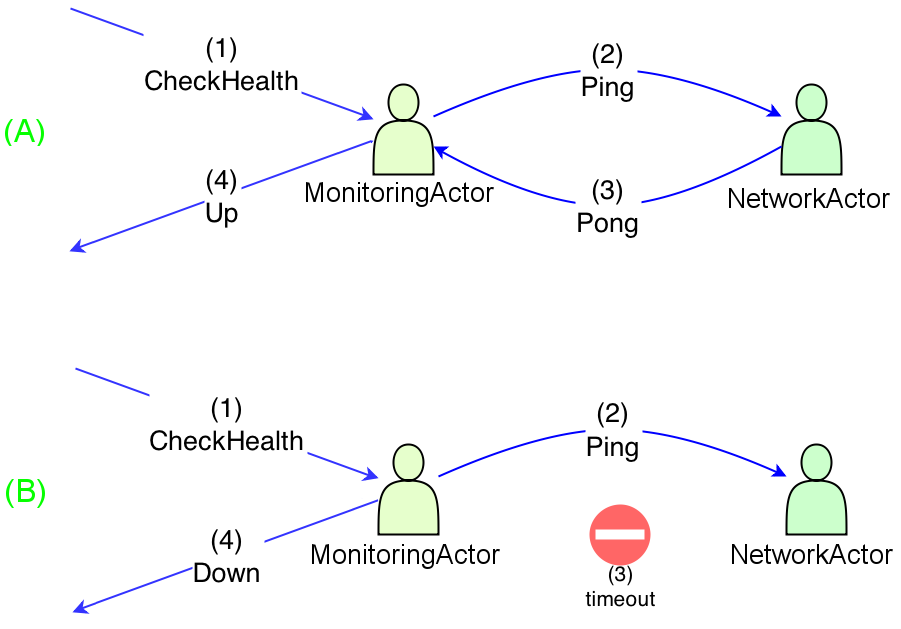
Apparently there are at least three ways to implement this simple task in Akka and we shall study their pros and cons.
Ordinary actor
In this scenario MonitoringActor listens for Pong directly without any intermediaries:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 | class MonitoringActor extends Actor with ActorLogging { private val networkActor = context.actorOf(Props[NetworkActor], "network") private var origin: Option[ActorRef] = None def receive = { case CheckHealth => networkActor ! Ping origin = Some(sender) case Pong => origin.foreach(_ ! Up) origin = None }} |
The implementation of NetworkActor is irrelevant, just assume it responds with Pong for each Ping. As you can see MonitoringActor handles two messages: CheckHealth sent by the client and Pong sent presumably by the NetworkActor. Sadly we had to store the client reference under origin field because it would have been lost otherwise once CheckHealth was handled. So we added a bit of state. The implementation is quite straightforward but has quite a few issues:
- Subsequent
CheckHealthwill overwrite previousorigin CheckHealthshould not really be allowed when waiting forPong- If
Pongnever arrives we are left in inconsistent state - …because we don’t have 1 second timeout condition yet
But before we implement timeout condition let’s refactor our code a little bit to make state more explicit and type-safe:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 | class MonitoringActor extends Actor with ActorLogging { private val networkActor = context.actorOf(Props[NetworkActor], "network") def receive = waitingForCheckHealth private def waitingForCheckHealth: Receive = { case CheckHealth => networkActor ! Ping context become waitingForPong(sender) } private def waitingForPong(origin: ActorRef): Receive = { case Pong => origin ! Up context become waitingForCheckHealth }} |
context.become() allows to change the behaviour of actor on the fly. In our case we either wait for CheckHealth or for Pong – but never both. But where did the state (origin reference) go? Well, it’s cleverly hidden. waitingForPong() method takes origin as parameter and returns a PartialFunction. This function closes over that parameter, thus actor-global variable is no longer necessary. OK, now we are ready to implement 1 second timeout when waiting for Pong:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 | def receive = waitingForCheckHealth private def waitingForCheckHealth: Receive = { case CheckHealth => networkActor ! Ping implicit val ec = context.dispatcher val timeout = context.system.scheduler. scheduleOnce(1.second, self, Down) context become waitingForPong(sender, timeout)} private def waitingForPong(origin: ActorRef, timeout: Cancellable): Receive = LoggingReceive { case Pong => timeout.cancel() origin ! Up context become receive case Down => origin ! Down context become receive} |
After sending Ping we immediately schedule sending Down message to ourselves after precisely one second. Then we go into waitingForPong. If Pong arrives we cancel scheduled Down and send Up instead. However if we first received Down it means one second elapsed. So we forward Down back to the client. Is it just me or maybe such a simple task should not require that amount of code?
Moreover please notice that our MonitoringActor is not capable of handling more than one client at a time. Once CheckHealth was received no more clients are allowed until Up or Down is sent back. Seems quite limiting.
Composing futures
Another approach to the very same problem is employing ask pattern and futures. Suddenly the code becomes much shorter and easier to read:
01 02 03 04 05 06 07 08 09 10 | def receive = { case CheckHealth => implicit val timeout: Timeout = 1.second implicit val ec = context.dispatcher val origin = sender networkActor ? Ping andThen { case Success(_) => origin ! Up case Failure(_) => origin ! Down }} |
That’s it! We ask networkActor by sending Ping and then when response arrives we reply to the client. In case it was a Success(_) (_ placeholder stands for Pong but we don’t really care) we send Up. If it was a Failure(_) (where _ most probably holds AskTimeout thrown after one second without reply) we forward Down. There is one enormous trap in this code. In both success and failure callbacks we can’t use sender directly because these pieces of code can be executed much later by another thread. sender‘s value is transient and by the time Pong arrives it might point to any other actor that happened to send us something. Thus we have to keep original sender in origin local variable and capture that one instead.
If you find this annoying you might play with pipeTo pattern:
1 2 3 4 5 6 7 8 | def receive = LoggingReceive { case CheckHealth => implicit val ec = context.dispatcher networkActor.ask(Ping)(1.second). map{_ => Up}. recover{case _ => Down}. pipeTo(sender)} |
Same as before we ask (synonym to ? method) networkActor with a timeout. If correct reply arrives we map it to Up. If instead future ends with exception we recover from it by mapping it to Down message. No matter which “branch” was exercised the result is piped to sender.
You should ask yourself a question: why code above is fine despite using sender while the previous one would have been broken? If you look closely at the declarations you’ll notice that pipeTo() takes an ActorRef by value, not by name. This means that sender is evaluated immediately when the expression is executed – not later when replies return. We are walking on a thin ice here so please be careful when making such assumptions.
Dedicated actor
Actors are lightweight so why not create one just for the sake of a single health check? This throw-away actor would be responsible for communicating with NetworkActor and pushing reply back to the client. The only responsibility of MonitoringActor would be to create an instance of this one time actor:
1 2 3 4 5 6 7 8 | class MonitoringActor extends Actor with ActorLogging { def receive = { case CheckHealth => context.actorOf(Props(classOf[PingActor], networkActor, sender)) } } |
PingActor is quite simple and similar to the very first solution:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 | class PingActor(networkActor: ActorRef, origin: ActorRef) extends Actor with ActorLogging { networkActor ! Ping context.setReceiveTimeout(1.second) def receive = { case Pong => origin ! Up self ! PoisonPill case ReceiveTimeout => origin ! Down self ! PoisonPill }} |
When the actor is created we send Ping to NetworkActor but also schedule timeout message. Now we wait either for Pong or for timeouted Down. In both cases we stop ourselves in the end because PingActor is no longer needed. Of course MonitoringActor can create multiple independent NetworkActors at the same time.
This solution combines simplicity and purity of the first one but is robust as the second one. Of course it also requires most code. It’s up to you which technique you employ in real life use cases. BTW after writing this article I came across Ask, Tell and Per-request Actors which touches the same problem and introduces similar approaches. Definitely look at it as well!

The last method is basically what Jamie Allen described in his Effective Akka as the Extra/Cameo patterns. Great examples!