Introduction
Design a domain can be a real challenge. A lot of bad practices can easily bring you to a bad design, and in most of the cases those issue will be discovered only after the advanced phase of business logic development.
Fortunately there are several approaches and “philosophies” for good design, like Domain Driven Design by Eric Evans.
What I would like to point out in this post is that not always Redundancy can be avoided, and that not always it is bad. I will discuss about the reasons of that after having presented all that cases where Redundancy should really be avoided.
What is Redundancy?
Let’s start by analyzing Redundancy in Database and Domain modelling.
Concerning Database modeling we call Data Redundancy that situation where the same information is physically located in two or more columns of different database tables; changing it in one of them will make the other ones become inconsistent.
Concerning Domain Design (indeed we are not talking about tables or objects, but entities) it refers to a situation where the same information is owned by different entities. Main reason here can be the not understanding of the pure domain, or the not clear context separation of the involved entities.
A redundancy in the domain model will automatically reflect in the database model, so it is very important to check the domain before its implementation.
What are the risks?
The risks of having an unwanted redundancy in the model are several and can impact disparate aspects:
- Safety: Data that is not coherent within a boundary will probably create safety issues, concerning its usage
- Quality: Can you trust the data? Can you prove it?
- Validation: The validation of the model strongly depends on external actors, that also must be proved and validated. And what is the risk associate with their failure? Can integrity be brought back?
- Maintainability: Duplicated data is difficult to maintain, following model evolution all the impacts of a change have to be correctly analyzed and applied
Some types of Redundancy to avoid
There are several reasons that can bring you to create unwanted redundancy in your model. I think it can be interesting to group them into 3 main categories:
- Physical redundancy
- Logical redundancy
- Algorithmic redundancy
Physical Redundancy
This kind of redundancy is the easiest one to detect with a minimum of experience. It happens when the same information is repeated in the domain, spanning through several entities or several instances of the same entity. This is typically the result of a not clear understanding of the business domain.
Using good practices, as for example the identification of the boundaries between Aggregates, will help to easily avoid those kind of redundancy.
In the following example, the single Person entity has a lot of information, this entity has been clearly overcharged and as a consequence a lot of data will be duplicated since most of those properties will be the same for both the married persons (marriedWith is cloning fullName, once civilStatus, marriageDate and childs will be the same for two married persons).

By identifying boundaries and applying separation of concerns we can arrive to this model that does not present anymore data redundancy but a new entity called Union and a clear boundary between the two entities.

Logical Redundancy
Sometime an information can be easily deducted by the data model itself.
In the previous example, the civilStatus property of the Person entity is a logical duplication of data, since the same information could be deduced by the relationship between Person and Union and by the type attribute in Union entity.

A certain measure has to be used in this case to avoid too complex cases; if not used with balance this approach risks to create obscure data.
Algorithmic Redundancy
Another type of redundancy to avoid is when the model contains two or more set of data of which at least one is the result of the application of an algorithm that uses as input the remaining ones.
The following diagram shows a real simple example of this type of redundancy, for sure it can exist more complex scenarios.

The new attribute age in Person entity is clearly redundant since it can be calculated anytime using the birthDate attribute.
When Redundancy cannot be avoid
When you cannot avoid something you do not want to happen, you should just try to control it!
And the same is for redundancy. Several scenarios can happen; in the following chapters I will list some of the most important ones I have been dealing with in my career,describing for each the reason and a solution for keep it under your control. Those are:
- Non functional Requirements
- Quality
- Safety
- Separate Contexts
Non Functional Requirements
Certain non functional requirements can bring redundancy in the model. If for example we want to apply the Modularity principle to our model and software architecture, we could find us in a situation where an entity spans through different modules.
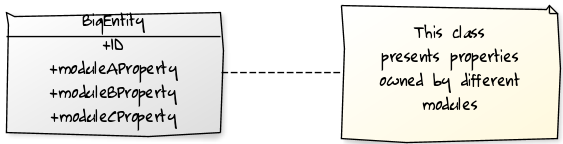
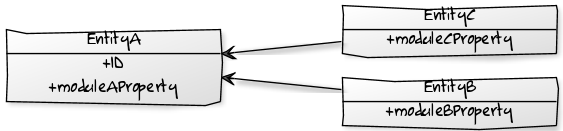
In that case, for keeping the modularity and respect the modules dependencies and workflow you will finish by splitting this entity into small module governed entities; this way boundaries and responsibilities will be clearly separated.
But now I want to show you one case where this approach will bring you to introduce redundancy. Consider a simple project management application where you need to define tasks in a planning. A first model would look like this:
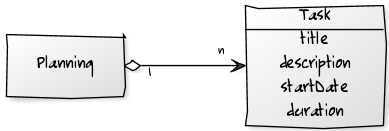
Now it comes a new requirement that is: several roles must work on the planning:
- Role A is in charge of defining a draft version of the planning, containing a list of tasks and their order of execution
- Role B is in charge of defining starting date and duration of each task
Those two roles must work in two different steps (A and B) of the process workflow and step A has to be officially validated before to start step B.
In that case applying the modularity principle will transform the model in something like this:

This model, clearly presents an Algorithmic Redundancy between the newly introduced sequence property in the Task entity, and the startDate property in the TaskExecution entity, since the sequence could be deduced by the start date of the task. This means a circular dependency in the workflow has been introduced with a lot of obvious drawbacks.
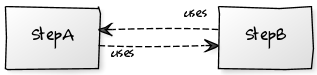
Implementing a clear separation of concerns, checking the dependency in the flow and defining a data flow model can help to reduce the risks associated to this kind of redundancy. In particular, to solve this issue, it has to be clarified the flow between the two modules and define StepA as master, and StepB as slave of the information. The final flow diagram would look like this:

Once the dependency diagram:
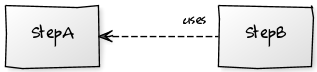
To resume, changing StepA can impact StepB, but changing StepB will never impact StepA. In other terms StepB model consistency is validated through the validated StepA model.
Quality Requirements
Very often quality requirements ask for data redundancy. I am thinking at features like Auditing, Revision Control, History Log.
The best approach here is to create a specific part of the domain with a clear redundant scope, that can store information at a certain date, or log… The duplicated entities can be simplified ones, for example a different model of the same entity could be done to manage historical data. Things as, relations, constraints can also be simplified in this part of the designed domain. See following example.
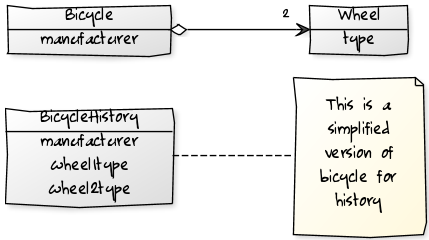
Please note that history tables are not intended in any way to be used by business logic.
Safety Requirements
Safety requirements will often bring redundancy in the model. To create a safer, easy to validate, and robust model a certain amount of data has to be introduced, and in most of the cases this will be redundant with the rest of the model.
As for building architecture, applying Structural Redundancy will increase the robustness of the model, since any introduced error will be easily identified and the associated risk will be mitigated.
To make another example I will talk about the integrity validation of a model. Let’s consider the model associated with an automation process. It is made of two parts:
- Input Data
- Automation Process Result
Since model 2 contains entities that are generated by the application of a series of algorithms on model 1 entities, it represents an Algorithic Redundancy.
How to grant that the impact of any change on model 1 will be easily identified and mitigated in model 2?
Two solutions can be possible here:
- Implement a revision control system in the database, and a traceability matrix between the generated entities (mapping revision number of the entities generated over the entities used as input)
- Implement a redundant input sub layer into module 2 that contains all the data from module 1 that has been used as an input to generate data in module 2. This layer can be used to verify at any moment that module 2 is still in sync with module 1.
Both the solutions need to apply Redundancy in the model, but again, the reason we are doing it is more important than any abstract beauty principle of domain design.

Separate Contexts
In some cases two separately modeled domains have to interact, but they have been developed and they are maintained by different development teams, so it is not possible to create an interface layer.
In that case, when data from domain A is needed by the other one let’ say domain B, it is possible that the easier solution would be to create a duplicated domain in B that contains all the necessary information from A.
The sync between the two domains can be done by an export-import process that can be executed on daily base.

Conclusion
Redundancy is just one of the many concerns that can arise during domain modeling. I am sure I did not cover all the possible cases but I hope you will find useful this content.
