In the recent time we’ve seen a plethora of tools that help you make sense of your logs. Open-source projects such as Scribe and LogStash, on-premise tools like Splunk, and hosted services such as SumoLogic and PaperTrail. These all help you reduce mass amounts of log data into something more meaningful.
And there’s one thing they all share in common. They’re all dependent on the data you actually put into the log. That task of getting the quality and quantity of the data right then falls on to you. With that in mind, here are 5 things that you should be constantly mindful of when logging:
1. Hello my (Thread) name is..
The Thread name property is one of Java’s most undervalued methods, as it’s mainly descriptive. The place where it plays the biggest part is in multi-threaded logging. Most logging frameworks will automatically log the current thread’s name. However, this would mostly look something like “http-nio-8080-exec-3” – a name assigned by the thread-pool or container.
The thread name is prime real-estate in your log, and you want to make sure you use it right. This means assigning it with detailed context, such as the Servlet or task its fulfilling right now, and some dynamic context such as a user or message ID.
As such, an entry point into your code should start with something like this:
Thread.currentThread().setName(MyTask.class.getName() + “: “+ message.getID());
2. Distributed identifiers
In a SOA or message driven architecture, the execution of a task or request may span across multiple machines. When processing of one fails, connecting the dots between the machines and their state will be key to understanding what happened.
For log analyzers to group relevant log messages across machines, you’ll need to provide them with a unique ID by by which they can do that, as part of each log message. This means that every inbound operation into your system should have a unique ID which will travel with it until it is completed.
A persistent identifier such as user ID may not be a good vessel, as one user may have multiple operations happening for him, which will make isolation harder. UUIDs (albeit long) can be a good choice here, and can also loaded into the thread name or a dedicated TLS.
3. Don’t text + drive. Don’t log + loop.
Often times you’ll see a piece of code running in a tight loop and performs a log operation. The underlying assumption is that the code will run a limited number of times.
That may very well be the case when things are working well. But when the code gets unexpected input the loop may not break. In that case you’re not just dealing with an infinite loop, you’re also dealing with code that’s writing infinite amounts of data to disk or network.
Left to its own devices this can take a server or an entire cluster down.
When possible, do not log within tight loops. This is especially true when catching errors.
void readData {
while (hasNext()) {
try {
readData();
}
catch (Exception e) {
// this isn’t recommend - you can catch, but log outside the loop
logger.error("error reading " X + " from " Y, e);
}
}
}4. Uncaught handlers
Westeros has the Wall its a last line of defense (fat good that’s gonna help them). You have Thread.uncaughtExcceptionHandlers. So make sure you use them. If you don’t install one such a handler, you run the risk of throwing exceptions into the ether with very little context, and very little control of if and where they end up being logged.
Notice that even within an uncaught exception handler, which has no access to variables within the terminated thread you still get a reference to the Thread object. If you adhered to step #1, you’ll still get a meaningful thread.getName() to log to provide you with some more context.
5. Catch external calls
Whenever you make an API call which leaves the JVM, the chances of an exception increase dramatically. This includes Web service, Http, DB, file , OS or any other JNI calls. Treat each call as if it will explode (it most likely will at one point).
For the most part, the reasons for API call fail have to do with unexpected input provided to them by you. Having those values available for you in the log is a key part in fixing the issue.
try {
return s3client.generatePresignedUrl(request);
}
catch (Exception e) {
String err = String.format("Error generating request: %s bucket: %s key: %s. method: %s", request, bucket, path, method);
log.error(err, e); //you can also throw a nested exception here with err instead.
}Server debugging with Takipi
Takipi is built to make server debugging even better by making your logs smarter and more rich in information. Here are 3 features which may make your life easier next time you’re debugging a server:
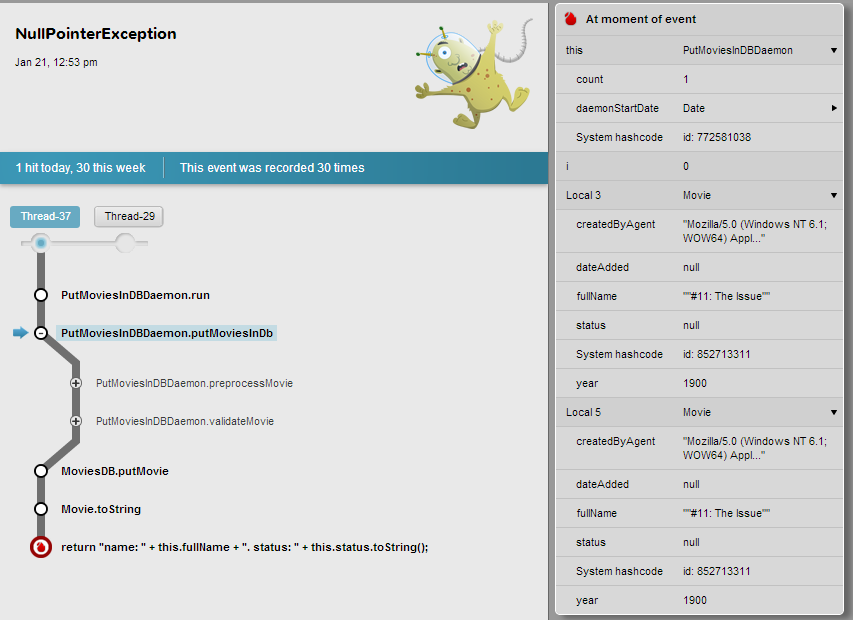
- Server debugging. When Takipi detects an exception or error within your JVM, it collects the code and variables which caused it. The end result is that for each error in your app you can jump right into the source code which executed on that machine, and see all the variable values which caused it – locals, objects, arrays and strings that were there, right at the moment of error.

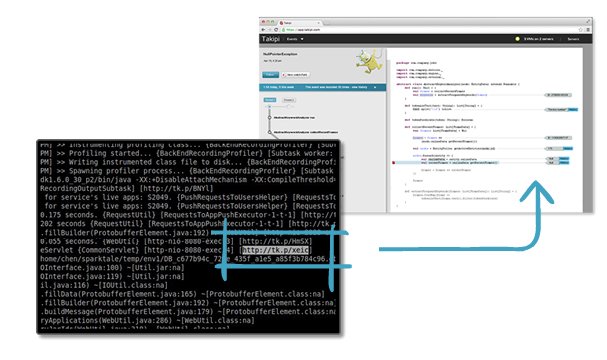
- Log integration. Takipi automatically add a tiny debug hyperlink to each log error , so you can use to jump directly into the actual source code and variable values which caused it.

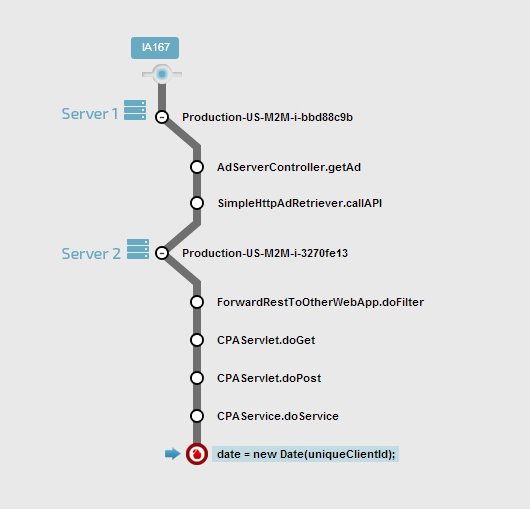
- Distributed debugging. If the call into the code which failed was made from another machine running Takipi, you’ll see the source code and variable values across the distributed call chain. So if machine A called into B which called into C which failed, you’ll see the code and variable across that entire chain between.


After reading the article I had two thought in my head:
1. The items “4. Uncaught handlers” and “5. Catch external calls” have nothing to do with logging.
2. The article was written to promote Takipi.
Hey Peter, Thanks for the comment. I wrote the post, so I’ll address points #4 and #5 and see if I can provide some value :) With regards to uncaught exception handlers, these callbacks were placed there by the designers of the language primarily for the purpose of providing developers with a centralized location where they can log uncaught exceptions. At the point, where the thread has already terminated there isn’t really anything else you can do other than logging the event. The language provides you with both the thread object and the exception which caused it to fail. It’s… Read more »
An other point: ThreadPoolExecutor by default “swallows” exceptions in the runnables / callables (uncaughtExceptionHandler won’t be called). The proper way to handle this is to subclass ThreadPoolExecutor and implement afterExecute: http://stackoverflow.com/a/2248203/1265
Thanks for the comment – good point.
Thanks for the article. I am very committed to ensuring that all our applications use logging properly and efficiently. Most logging frameworks provide a format option to indicate the thread. Personally I favor using SLF4j over Logback. SLF4j allows your application to capture all Apache and java util (even System.out/err are available) into a single logging strategy. Another common mistake is the unnecessary inclusion of isDebugEnabled(), isInfoEnabled(), etc, for single lines it is overkill as it is done in the source. Using SLF4j, you can avoid unnecessary concatenation using parameters log.debug(“here is your value {}, myvar);.
Hi Gordon, thanks for the comment – insightful stuff!
We recently did follow-up post on log analyzers – http://www.takipiblog.com/2014/04/23/the-7-log-management-tools-you-need-to-know/ I thought you’d might find it interesting as well. I’d love to hear what you think.