Most search applications using Apache Lucene assign a unique id, or primary key, to each indexed document. While Lucene itself does not require this (it could care less!), the application usually needs it to later replace, delete or retrieve that one document by its external id. Most servers built on top of Lucene, such as Elasticsearch and Solr, require a unique id and can auto-generate one if you do not provide it.
Sometimes your id values are already pre-defined, for example if an external database or content management system assigned one, or if you must use a URI, but if you are free to assign your own ids then what works best for Lucene?
One obvious choice is Java’s UUID class, which generates version 4 universally unique identifiers, but it turns out this is the worst choice for performance: it is 4X slower than the fastest. To understand why requires some understanding of how Lucene finds terms.
BlockTree terms dictionary
The purpose of the terms dictionary is to store all unique terms seen during indexing, and map each term to its metadata (docFreq, totalTermFreq, etc.), as well as the postings (documents, offsets, postings and payloads). When a term is requested, the terms dictionary must locate it in the on-disk index and return its metadata.
The default codec uses the BlockTree terms dictionary, which stores all terms for each field in sorted binary order, and assigns the terms into blocks sharing a common prefix. Each block contains between 25 and 48 terms by default. It uses an in-memory prefix-trie index structure (an FST) to quickly map each prefix to the corresponding on-disk block, and on lookup it first checks the index based on the requested term’s prefix, and then seeks to the appropriate on-disk block and scans to find the term.
In certain cases, when the terms in a segment have a predictable pattern, the terms index can know that the requested term cannot exist on-disk. This fast-match test can be a sizable performance gain especially when the index is cold (the pages are not cached by the the OS’s IO cache) since it avoids a costly disk-seek. As Lucene is segment-based, a single id lookup must visit each segment until it finds a match, so quickly ruling out one or more segments can be a big win. It is also vital to keep your segment counts as low as possible!
Given this, fully random ids (like UUID V4) should perform worst, because they defeat the terms index fast-match test and require a disk seek for every segment. Ids with a predictable per-segment pattern, such as sequentially assigned values, or a timestamp, should perform best as they will maximize the gains from the terms index fast-match test.
Testing Performance
I created a simple performance tester to verify this; the full source code is here. The test first indexes 100 million ids into an index with 7/7/8 segment structure (7 big segments, 7 medium segments, 8 small segments), and then searches for a random subset of 2 million of the IDs, recording the best time of 5 runs. I used Java 1.7.0_55, on Ubuntu 14.04, with a 3.5 GHz Ivy Bridge Core i7 3770K.
Since Lucene’s terms are now fully binary as of 4.0, the most compact way to store any value is in binary form where all 256 values of every byte are used. A 128-bit id value then requires 16 bytes.
I tested the following identifier sources:
- Sequential IDs (0, 1, 2, …), binary encoded.
- Zero-padded sequential IDs (00000000, 00000001, …), binary encoded.
- Nanotime, binary encoded. But remember that nanotime is tricky.
- UUID V1, derived from a timestamp, nodeID and sequence counter, using this implementation.
- UUID V4, randomly generated using Java’s
UUID.randomUUID(). - Flake IDs, using this implementation.
For the UUIDs and Flake IDs I also tested binary encoding in addition to their standard (base 16 or 36) encoding. Note that I only tested lookup speed using one thread, but the results should scale linearly (on sufficiently concurrent hardware) as you add threads.
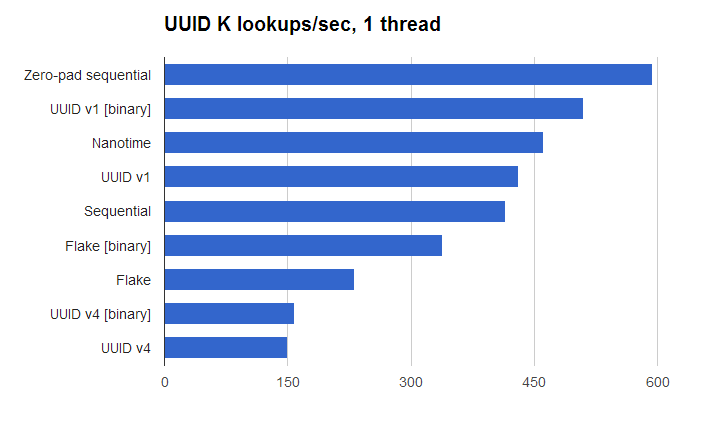
Zero-padded sequential ids, encoded in binary are fastest, quite a bit faster than non-zero-padded sequential ids. UUID V4 (using Java’s UUID.randomUUID()) is ~4X slower.
But for most applications, sequential ids are not practical. The 2nd fastest is UUID V1, encoded in binary. I was surprised this is so much faster than Flake IDs since Flake IDs use the same raw sources of information (time, node id, sequence) but shuffle the bits differently to preserve total ordering. I suspect the problem is the number of common leading digits that must be traversed in a Flake ID before you get to digits that differ across documents, since the high order bits of the 64-bit timestamp come first, whereas UUID V1 places the low order bits of the 64-bit timestamp first. Perhaps the terms index should optimize the case when all terms in one field share a common prefix.
I also separately tested varying the base from 10, 16, 36, 64, 256 and in general for the non-random ids, higher bases are faster. I was pleasantly surprised by this because I expected a base matching the BlockTree block size (25 to 48) would be best.
There are some important caveats to this test (patches welcome)! A real application would obviously be doing much more work than simply looking up ids, and the results may be different as hotspot must compile much more active code. The index is fully hot in my test (plenty of RAM to hold the entire index); for a cold index I would expect the results to be even more stark since avoiding a disk-seek becomes so much more important. In a real application, the ids using timestamps would be more spread apart in time; I could “simulate” this myself by faking the timestamps over a wider range. Perhaps this would close the gap between UUID V1 and Flake IDs? I used only one thread during indexing, but a real application with multiple indexing threads would spread out the ids across multiple segments at once.
I used Lucene’s default TieredMergePolicy, but it is possible a smarter merge policy that favored merging segments whose ids were more “similar” might give better results. The test does not do any deletes/updates, which would require more work during lookup since a given id may be in more than one segment if it had been updated (just deleted in all but one of them).
Finally, I used using Lucene’s default Codec, but we have nice postings formats optimized for primary-key lookups when you are willing to trade RAM for faster lookups, such as this Google summer-of-code project from last year and MemoryPostingsFormat. Likely these would provide sizable performance gains!
| Reference: | Choosing a fast unique identifier (UUID) for Lucene from our JCG partner Michael Mc Candless at the Changing Bits blog. |
