A colleague recently told me about several benefits of Cassandra and I decided to try it out. Apache Cassandra is described in A Quick Introduction to Apache Cassandra as “one of today’s most popular NoSQL-databases.” The main page for Apache Cassandra states that the “Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance.” Cassandra is being used by companies such as eBay, Netflix, Adobe, Reddit, Instagram, and Twitter. This post is a summary of steps for getting started with Cassandra.
Apache Cassandra can be downloaded from the main Apache Cassandra web page. The Download page states that “the latest stable release of Apache Cassandra is 2.0.7 (released on 2014-04-18)” and this is the version I will discuss and use in this post.
For this post, I downloaded and installed the DataStax Community Edition from Planet Cassandra Downloads. The DataStax Community 2.0.7 edition includes “The Most Stable and Recommended Version of Apache Cassandra for Production (2.0.7).” There are DataStax Community Edition downloads available for Mac OS X, Microsoft Windows, and several flavors of Linux.
The next screen snapshot shows the directory listing for the “bin” directory of the Apache Cassandra included with the DataStax Community Edition installation.
From that “bin” directory, the Cassandra server can be started simply by running the appropriate executable. In the case of this single Windows machine, that command is cassandra.bat and this step is illustrated in the next screen snapshot.
The interactive command-line tool cqlsh is also located in the Apache Cassandra “bin” subdirectory. This tool is similar to SQL*Plus for Oracle databases, mysql for MySQL databases, and psql for PostgreSQL. It allows one to enter various CQL (Cassandra Query Language) statements such as inserting new data and querying data. Starting cqshl from the command line on a Windows machine is shown in the next screen snapshot.
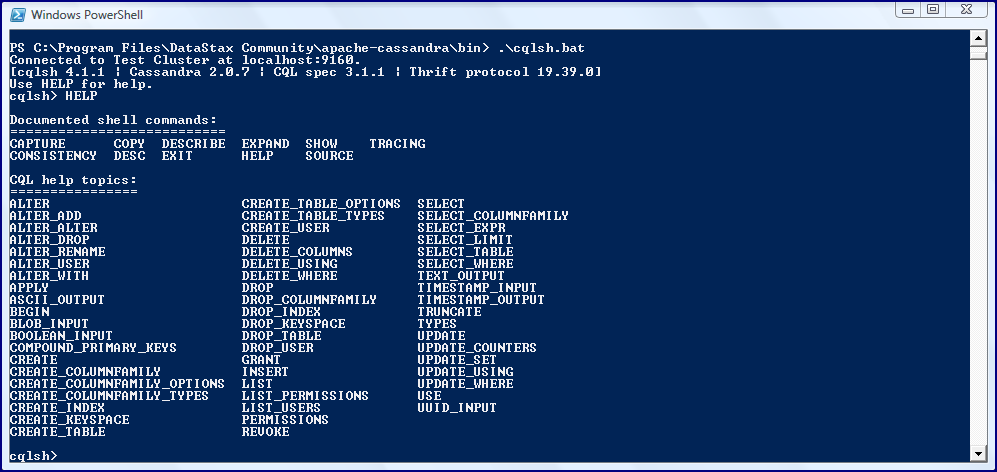
There are several useful observations that can be made from the previous image. As the output of from starting cqlsh shows, this version of Apache Cassandra is 2.0.7, this version of cqlsh is 4.1.1, and the relevant CQL specification is 3.1.1. The immediately previous screen snapshot also demonstrates help provided by running the “HELP” command. We can see that there are several “documented shell commands” as well as even more “CQL help topics.”
The previous screen snapshot demonstrated that the “help” command in cqlsh lists individual topics on which the help command can be specifically run. For example, the next screen snapshot demonstrates the output from running “help types” in cqlsh.
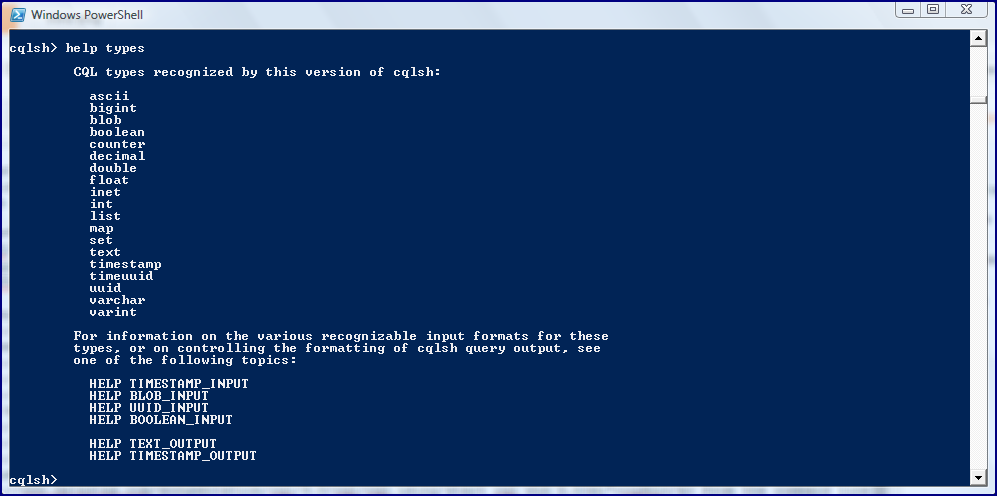
In this screen snapshot, we see CQL data types that are supported in cqlsh such as ascii, text/varchar, decimal, int, double, timestamp, list, set, and map.
Keyspaces in Cassandra
Keyspaces are significant in Cassandra. Although this post covers Cassandra 2.0, the Cassandra 1.0 documentation nicely explains keyspaces in Cassandra: “In Cassandra, the keyspace is the container for your application data, similar to a schema in a relational database. Keyspaces are used to group column families together. Typically, a cluster has one keyspace per application.” This documentation goes on to explain that keyspaces are typically used to group column families by replication strategy. The next screenshot demonstrates creation of a keyspace in cqlsh and listing the available keyspaces.
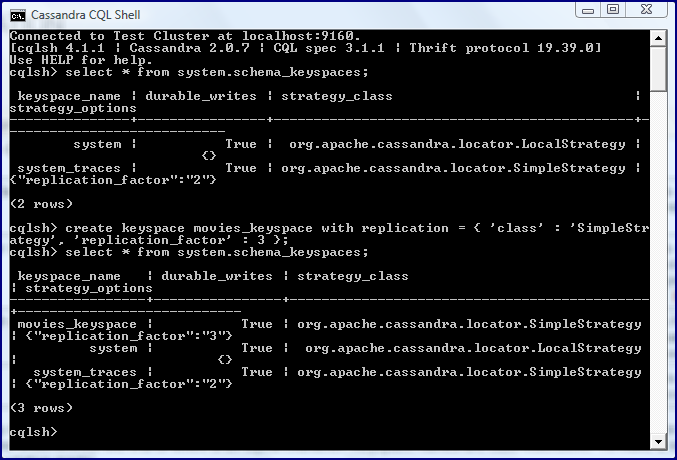
The last screen snapshot included an example of using the command SELECT * FROM system.schema_keyspaces; to see the available keyspaces. When one just wants a list of the names of the available keyspaces without all of the other details, it is easy to use desc keyspaces as shown in the next screens snapshot.
![]()
Creating a Column Family (“Table”)
With a keyspace created, a column family (or table) can be created. The next screen snapshot demonstrates using the newly created movies_keyspace with the use movies_keyspace; statement and then shows using the cqlsh command SOURCE (similar to using @ in SQL*Plus) to run an external file to create a table (column family). The screen snapshot demonstrates listing available tables with the desc tables command and listing specific details of a given table (MOVIES in this case) with the desc table movies command.
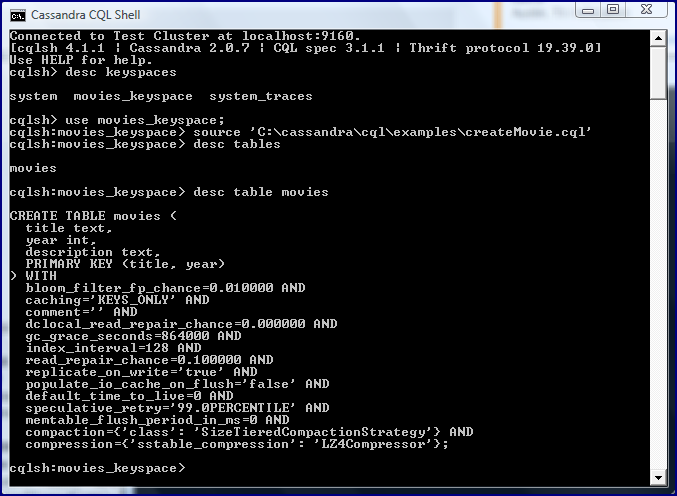
The above screen snapshot demonstrated running an external file called createMovie.cql using the SOURCE command. The code listing for the createMovie.cql file is shown next.
1 2 3 4 5 6 7 | CREATE TABLE movies( title varchar, year int, description varchar, PRIMARY KEY (title, year)); |
Inserting Data into and Querying from the Column Family
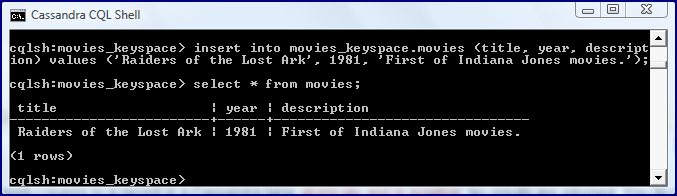
The next screen snapshot demonstrates how to insert data into the newly created column family/table [insert into movies_keyspace.movies (title, year, description) values ('Raiders of the Lost Ark', 1981, 'First of Indiana Jones movies.');]. The image also shows how to query the column family/table to see its contents [select * from movies].
Cassandra is NOT a Relational Database
Looking at the Cassandra Query Language (CQL) statements just shown might lead someone to believe that Cassandra is a relational database. However, CQL is a relational-like feature added to Cassandra 2.0 intended to help people with SQL expertise more readily adopt Cassandra. Similarly, triggers are being added in 2.0/2.1. Despite the presence of these Cassandra features intended to make it easier for relational database users to adopt Cassandra, there are significant differences between Cassandra and a relational database.
The Cassandra Data Model is a page in the Apache Cassandra 1.0 Documentation that describes some key differences between Cassandra and relational databases. These include:
- “Cassandra does not enforce relationships between column families the way that relational databases do between tables”
- There are no foreign keys in Cassandra and there is no “joining” in Cassandra.
- Denormalization is not a shameful thing in Cassandra and is actually welcomed to a certain degree.
- Cassandra “table” (column family) modeling should be done based on expected queries to be used.
Conclusion
I’ve just begun to get my feet wet with Cassandra but look forward to learning more about it. This post has focused on some basics of acquiring and starting to use Cassandra. There is much to learn about Cassandra and some “deeper” topics that really need to be understood to truly appreciate Cassandra include Cassandra architecture (and here), Cassandra Data Modeling (and here), and Cassandra’s strengths and weaknesses.
| Reference: | Hello Cassandra from our JCG partner Dustin Marx at the Inspired by Actual Events blog. |

Thanks for sharing such beautiful information with us. The download is must be clear the process with code. I hope you’ll some more info about Cassandra tutorial.
Cassandra Tutorial