This post covers to use Apache Hive to query the search clicks data stored under Hadoop. We will take examples to generate customer top search query and statistics on total product views.
In continuation to the previous posts on
- Customer product search clicks analytic using big data,
- Flume: Gathering customer product search clicks data using Apache Flume,
we already have customer search clicks data gathered using Flume in Hadoop HDFS.
Here will analyze further to use Hive to query the stored data under Hadoop.
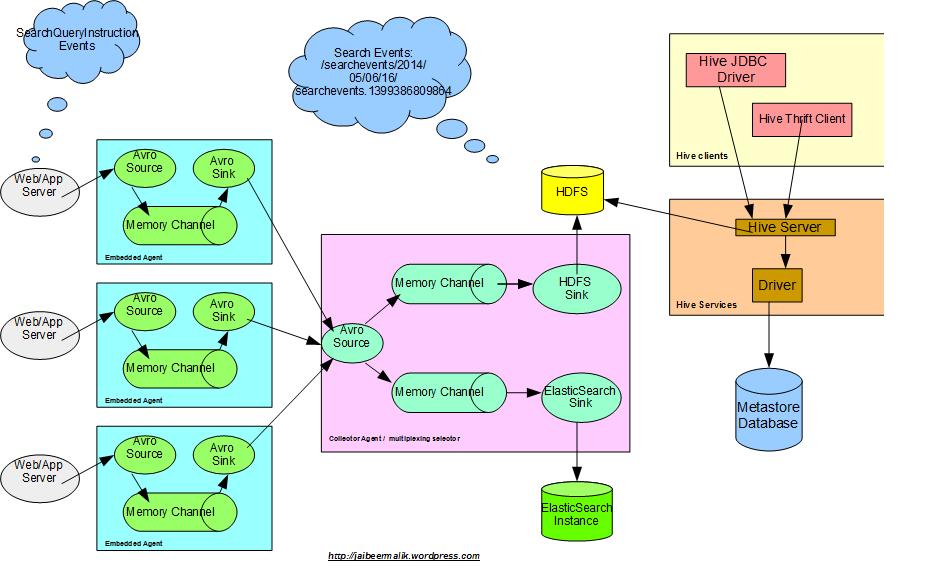
Hive
Hive allow us to query big data using SQL-like language HiveQL.
Hadoop Data
As shared in last post, we have search clicks data stored under hadoop with the following format “/searchevents/2014/05/15/16/”. The data is stored in separate directory created per hour.
The files are created as:
1 | hdfs://localhost.localdomain:54321/searchevents/2014/05/06/16/searchevents.1399386809864 |
The data is stored as DataSteam:
1 2 | {"eventid":"e8470a00-c869-4a90-89f2-f550522f8f52-1399386809212-72","hostedmachinename":"192.168.182.1334","pageurl":"http://jaibigdata.com/0","customerid":72,"sessionid":"7871a55c-a950-4394-bf5f-d2179a553575","querystring":null,"sortorder":"desc","pagenumber":0,"totalhits":8,"hitsshown":44,"createdtimestampinmillis":1399386809212,"clickeddocid":"23","favourite":null,"eventidsuffix":"e8470a00-c869-4a90-89f2-f550522f8f52","filters":[{"code":"searchfacettype_brand_level_2","value":"Apple"},{"code":"searchfacettype_color_level_2","value":"Blue"}]}{"eventid":"2a4c1e1b-d2c9-4fe2-b38d-9b7d32feb4e0-1399386809743-61","hostedmachinename":"192.168.182.1330","pageurl":"http://jaibigdata.com/0","customerid":61,"sessionid":"78286f6d-cc1e-489c-85ce-a7de8419d628","querystring":"queryString59","sortorder":"asc","pagenumber":3,"totalhits":32,"hitsshown":9,"createdtimestampinmillis":1399386809743,"clickeddocid":null,"favourite":null,"eventidsuffix":"2a4c1e1b-d2c9-4fe2-b38d-9b7d32feb4e0","filters":[{"code":"searchfacettype_age_level_2","value":"0-12 years"}]} |
Spring Data
We will use Spring for Apache Hadoop to run the hive jobs using Spring. To set up hive environment with in your application, use the following configurations:
01 02 03 04 05 06 07 08 09 10 11 | <hdp:configuration id="hadoopConfiguration" resources="core-site.xml"> fs.default.name=hdfs://localhost.localdomain:54321 mapred.job.tracker=localhost.localdomain:54310</hdp:configuration><hdp:hive-server auto-startup="true" port="10234" min-threads="3" id="hiveServer" configuration-ref="hadoopConfiguration"></hdp:hive-server><hdp:hive-client-factory id="hiveClientFactory" host="localhost" port="10234"></hdp:hive-client-factory><hdp:hive-runner id="hiveRunner" run-at-startup="false" hive-client-factory-ref="hiveClientFactory"></hdp:hive-runner> |
Check the spring context file applicationContext-elasticsearch.xml for further details. We will use hiveRunner to run the hive scripts.
All the hive scripts in the application are located under resources hive folder.
The service to run all hive scripts can be found at HiveSearchClicksServiceImpl.java
Set up Database
Let’s setup database to query the data first.
1 2 | DROP DATABASE IF EXISTS search CASCADE;CREATE DATABASE search; |
Query Search Events using External Table
We will create an External table search_clicks to read the search events data stored under hadoop.
1 2 | USE search;CREATE EXTERNAL TABLE IF NOT EXISTS search_clicks (eventid String, customerid BIGINT, hostedmachinename STRING, pageurl STRING, totalhits INT, querystring STRING, sessionid STRING, sortorder STRING, pagenumber INT, hitsshown INT, clickeddocid STRING, filters ARRAY<STRUCT<code:STRING, value:STRING>>, createdtimestampinmillis BIGINT) PARTITIONED BY (year STRING, month STRING, day STRING, hour STRING) ROW FORMAT SERDE 'org.jai.hive.serde.JSONSerDe' LOCATION 'hdfs:///searchevents/'; |
JSONSerDe
Custom SerDe “org.jai.hive.serde.JSONSerDe” is used to map the json data. Check further details on the same JSONSerDe.java
If you are running the queries from Eclipse itself, the dependencies will automatically be resolved. If your are running from hive console, make sure to create a jar file for the class add relevant dependency to hive console before running the hive queries.
1 2 3 4 5 6 7 8 9 | #create hive json serde jarjar cf jaihivejsonserde-1.0.jar org/jai/hive/serde/JSONSerDe.class# run on hive console to add jaradd jar /opt/hive/lib/jaihivejsonserde-1.0.jar;# Or add jar path to hive-site.xml file permanently<property> <name>hive.aux.jars.path</name> <value>/opt/hive/lib/jaihivejsonserde-1.0.jar</value></property> |
Create hive partition
We will use hive partitions strategy to read data stored in hadoop under hierarhical locations. Based on above location “/searchevents/2014/05/06/16/”, we will pass following param values (DBNAME=search, TBNAME=search_clicks, YEAR=2014, MONTH=05, DAY=06, HOUR=16).
1 2 | USE ${hiveconf:DBNAME};ALTER TABLE ${hiveconf:TBNAME} ADD IF NOT EXISTS PARTITION(year='${hiveconf:YEAR}', month='${hiveconf:MONTH}', day='${hiveconf:DAY}', hour='${hiveconf:HOUR}') LOCATION "hdfs:///searchevents/${hiveconf:YEAR}/${hiveconf:MONTH}/${hiveconf:DAY}/${hiveconf:HOUR}/"; |
To run the script,
01 02 03 04 05 06 07 08 09 10 11 12 | Collection<HiveScript> scripts = new ArrayList<>(); Map<String, String> args = new HashMap<>(); args.put("DBNAME", dbName); args.put("TBNAME", tbName); args.put("YEAR", year); args.put("MONTH", month); args.put("DAY", day); args.put("HOUR", hour); HiveScript script = new HiveScript(new ClassPathResource("hive/add_partition_searchevents.q"), args); scripts.add(script); hiveRunner.setScripts(scripts); hiveRunner.call(); |
In later post, we will cover how to use Oozie coordinator job to automatically create hive parititions for hourly data.
Get all Search Click Events
Get the search events stored in external table search_clicks. Pass folllowing param values (DBNAME=search, TBNAME=search_clicks, YEAR=2014, MONTH=05, DAY=06, HOUR=16).
1 2 | USE ${hiveconf:DBNAME};select eventid, customerid, querystring, filters from ${hiveconf:TBNAME} where year='${hiveconf:YEAR}' and month='${hiveconf:MONTH}' and day='${hiveconf:DAY}' and hour='${hiveconf:HOUR}'; |
This will return you all data under the specified location and will also help you test your custom SerDe.
Find product views in last 30 days
How many time a product has been viewed/clicked in the last n number of days.
1 2 3 4 5 | Use search;DROP TABLE IF EXISTS search_productviews;CREATE TABLE search_productviews(id STRING, productid BIGINT, viewcount INT);-- product views count in the last 30 days.INSERT INTO TABLE search_productviews select clickeddocid as id, clickeddocid as productid, count(*) as viewcount from search_clicks where clickeddocid is not null and createdTimeStampInMillis > ((unix_timestamp() * 1000) - 2592000000) group by clickeddocid order by productid; |
To run the script,
1 2 3 4 5 | Collection<HiveScript> scripts = new ArrayList<>(); HiveScript script = new HiveScript(new ClassPathResource("hive/load-search_productviews-table.q")); scripts.add(script); hiveRunner.setScripts(scripts); hiveRunner.call(); |
Sample data, select data from “search_productviews” table.
1 2 3 4 5 | # id, productid, viewcount61, 61, 1548, 48, 816, 16, 4085, 85, 7 |
Find Cutomer top queries in last 30 days
1 2 3 4 5 | Use search;DROP TABLE IF EXISTS search_customerquery;CREATE TABLE search_customerquery(id String, customerid BIGINT, querystring String, querycount INT);-- customer top query string in the last 30 daysINSERT INTO TABLE search_customerquery select concat(customerid,"_",queryString), customerid, querystring, count(*) as querycount from search_clicks where querystring is not null and customerid is not null and createdTimeStampInMillis > ((unix_timestamp() * 1000) - 2592000000) group by customerid, querystring order by customerid; |
Sample data, select data from “search_customerquery” table.
1 2 3 4 5 | # id, querystring, count, customerid61_queryString59, queryString59, 5, 61298_queryString48, queryString48, 3, 298440_queryString16, queryString16, 1, 44047_queryString85, queryString85, 1, 47 |
Analyzing Facets/Filters for Guided Navigation
You can further extend the Hive queries to generate statistics on how the end customers behaving over period of time while using facet/filters to search for the relevant product.
1 2 3 4 5 6 7 | USE search;-- How many times a particular filter has been clicked.select count(*) from search_clicks where array_contains(filters, struct("searchfacettype_color_level_2", "Blue"));-- how many distinct customer clicked the filterselect DISTINCT customerid from search_clicks where array_contains(filters, struct("searchfacettype_color_level_2", "Blue"));-- top query filters by a customerselect customerid, filters.code, filters.value, count(*) as filtercount from search_clicks group by customerid, filters.code, filters.value order by filtercount DESC limit 100; |
The data extraction Hive queries can be scheduled on nightly basis/hourly basis based on the requirements and can be executed using job scheduler like Oozie. The data can further be used to BI analytic or improved customer experience.
In later posts we will cover to analyze the generated data further,
- Using ElasticSearch Hadoop to index customer top queries and product views data
- Using Oozie to schedule coordinated jobs for hive partition and bundle job to index data to ElasticSearch.
- Using Pig to count total number of unique customers etc.
| Reference: | Hive: Query customer top search query and product views count using Apache Hive from our JCG partner Jaibeer Malik at the Jai’s Weblog blog. |
