Quartz Scheduler is one of the most popular scheduling library in Java world. I had worked with Quartz mostly in Spring applications in the past. Recently, I have been investigating scheduling in JEE 6 application running on JBoss 7.1.1 that is going to be deployed in the cloud. As one of the options I consider is Quartz Scheduler as it offers clustering with database. In this article I will show how easy is to configure Quartz in JEE application and run it either on JBoss 7.1.1 or WildFly 8.0.0, use MySQL as job store and utilize CDI to use dependency injection in jobs. All will be done in IntelliJ. Let’s get started.
Create Maven project
I used org.codehaus.mojo.archetypes:webapp-javaee6 archetype to bootstrap the application and then I slightly modified the pom.xml. I also added slf4J dependency, so the resulting pom.xml looks as following:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 | <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <modelVersion>4.0.0</modelVersion> <groupId>pl.codeleak</groupId> <artifactId>quartz-jee-demo</artifactId> <version>1.0</version> <packaging>war</packaging> <name>quartz-jee-demo</name> <properties> <endorsed.dir>${project.build.directory}/endorsed</endorsed.dir> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <dependency> <groupId>javax</groupId> <artifactId>javaee-api</artifactId> <version>6.0</version> <scope>provided</scope> </dependency> <!-- Logging --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.7</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-jdk14</artifactId> <version>1.7.7</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>2.3.2</version> <configuration> <source>1.7</source> <target>1.7</target> <compilerArguments> <endorseddirs>${endorsed.dir}</endorseddirs> </compilerArguments> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-war-plugin</artifactId> <version>2.1.1</version> <configuration> <failOnMissingWebXml>false</failOnMissingWebXml> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-dependency-plugin</artifactId> <version>2.1</version> <executions> <execution> <phase>validate</phase> <goals> <goal>copy</goal> </goals> <configuration> <outputDirectory>${endorsed.dir}</outputDirectory> <silent>true</silent> <artifactItems> <artifactItem> <groupId>javax</groupId> <artifactId>javaee-endorsed-api</artifactId> <version>6.0</version> <type>jar</type> </artifactItem> </artifactItems> </configuration> </execution> </executions> </plugin> </plugins> </build></project> |
The next thing was to import the project to IDE. In my case this is IntelliJ and create a run configuration with JBoss 7.1.1.
One note, in the VM Options in run configuration I added two variables:
1 2 | -Djboss.server.default.config=standalone-custom.xml-Djboss.socket.binding.port-offset=100 |
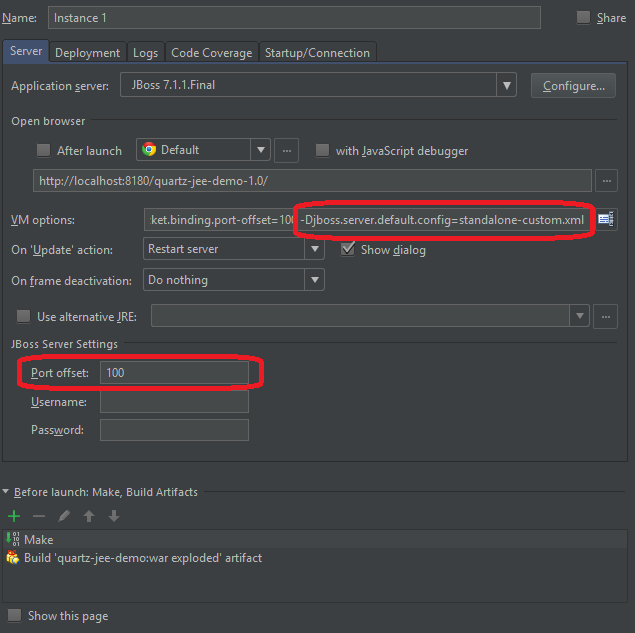
standalone-custom.xml is a copy of the standard standalone.xml, as the configuration will need to be modified (see below).
Configure JBoss server
In my demo application I wanted to use MySQL database with Quartz, so I needed to add MySQL data source to my configuration. This can be quickly done with two steps.
Add Driver Module
I created a folder JBOSS_HOME/modules/com/mysql/main. In this folder I added two files: module.xml and mysql-connector-java-5.1.23.jar. The module file looks as follows:
1 2 3 4 5 6 7 8 9 | <?xml version="1.0" encoding="UTF-8"?> <module xmlns="urn:jboss:module:1.0" name="com.mysql"> <resources> <resource-root path="mysql-connector-java-5.1.23.jar"/> </resources> <dependencies> <module name="javax.api"/> </dependencies> </module> |
Configure Data Source
In the standalone-custom.xml file in the datasources subsystem I added a new data source:
1 2 3 4 5 6 7 8 | <datasource jta="false" jndi-name="java:jboss/datasources/MySqlDS" pool-name="MySqlDS" enabled="true" use-java-context="true"> <connection-url>jdbc:mysql://localhost:3306/javaee</connection-url> <driver>com.mysql</driver> <security> <user-name>jeeuser</user-name> <password>pass</password> </security></datasource> |
And the driver:
1 2 3 | <drivers> <driver name="com.mysql" module="com.mysql"/></drivers> |
Note: For the purpose of this demo, the data source is not JTA managed to simplify the configuration.
Configure Quartz with Clustering
I used official tutorial to configure Quarts with Clustering: http://quartz-scheduler.org/documentation/quartz-2.2.x/configuration/ConfigJDBCJobStoreClustering
Add Quartz dependencies to pom.xml
01 02 03 04 05 06 07 08 09 10 | <dependency> <groupId>org.quartz-scheduler</groupId> <artifactId>quartz</artifactId> <version>2.2.1</version></dependency><dependency> <groupId>org.quartz-scheduler</groupId> <artifactId>quartz-jobs</artifactId> <version>2.2.1</version></dependency> |
Add quartz.properties to src/main/resources
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | #============================================================================# Configure Main Scheduler Properties #============================================================================org.quartz.scheduler.instanceName = MySchedulerorg.quartz.scheduler.instanceId = AUTO#============================================================================# Configure ThreadPool #============================================================================org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPoolorg.quartz.threadPool.threadCount = 1#============================================================================# Configure JobStore #============================================================================org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTXorg.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegateorg.quartz.jobStore.useProperties = falseorg.quartz.jobStore.dataSource=MySqlDSorg.quartz.jobStore.isClustered = trueorg.quartz.jobStore.clusterCheckinInterval = 5000org.quartz.dataSource.MySqlDS.jndiURL=java:jboss/datasources/MySqlDS |
Create MySQL tables to be used by Quartz
The schema file can be found in the Quartz distribution: quartz-2.2.1\docs\dbTables.
Demo code
Having the configuration in place, I wanted to check if Quartz works, so I created a scheduler, with no jobs and triggers.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 | package pl.codeleak.quartzdemo;import org.quartz.JobKey;import org.quartz.Scheduler;import org.quartz.SchedulerException;import org.quartz.TriggerKey;import org.quartz.impl.StdSchedulerFactory;import org.quartz.impl.matchers.GroupMatcher;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import javax.annotation.PostConstruct;import javax.annotation.PreDestroy;import javax.ejb.Singleton;import javax.ejb.Startup;@Startup@Singletonpublic class SchedulerBean { private Logger LOG = LoggerFactory.getLogger(SchedulerBean.class); private Scheduler scheduler; @PostConstruct public void scheduleJobs() { try { scheduler = new StdSchedulerFactory().getScheduler(); scheduler.start(); printJobsAndTriggers(scheduler); } catch (SchedulerException e) { LOG.error("Error while creating scheduler", e); } } private void printJobsAndTriggers(Scheduler scheduler) throws SchedulerException { LOG.info("Quartz Scheduler: {}", scheduler.getSchedulerName()); for(String group: scheduler.getJobGroupNames()) { for(JobKey jobKey : scheduler.getJobKeys(GroupMatcher.<JobKey>groupEquals(group))) { LOG.info("Found job identified by {}", jobKey); } } for(String group: scheduler.getTriggerGroupNames()) { for(TriggerKey triggerKey : scheduler.getTriggerKeys(GroupMatcher.<TriggerKey>groupEquals(group))) { LOG.info("Found trigger identified by {}", triggerKey); } } } @PreDestroy public void stopJobs() { if (scheduler != null) { try { scheduler.shutdown(false); } catch (SchedulerException e) { LOG.error("Error while closing scheduler", e); } } }} |
When you run the application you should be able to see some debugging information from Quartz:
1 2 3 4 5 6 | Scheduler class: 'org.quartz.core.QuartzScheduler' - running locally. NOT STARTED. Currently in standby mode. Number of jobs executed: 0 Using thread pool 'org.quartz.simpl.SimpleThreadPool' - with 1 threads. Using job-store 'org.quartz.impl.jdbcjobstore.JobStoreTX' - which supports persistence. and is clustered. |
Let Quartz utilize CDI
In Quartz, jobs must implement org.quartz.Job interface.
01 02 03 04 05 06 07 08 09 10 11 12 13 | package pl.codeleak.quartzdemo;import org.quartz.Job;import org.quartz.JobExecutionContext;import org.quartz.JobExecutionException;public class SimpleJob implements Job { @Override public void execute(JobExecutionContext context) throws JobExecutionException { // do something }} |
Then to create a Job we use JobBuilder:
1 2 3 4 5 | JobKey job1Key = JobKey.jobKey("job1", "my-jobs");JobDetail job1 = JobBuilder .newJob(SimpleJob.class) .withIdentity(job1Key) .build(); |
In my example, I needed to inject EJBs to my jobs in order to re-use existing application logic. So in fact, I needed to inject a EJB reference. How this can be done with Quartz? Easy. Quartz Scheduler has a method to provide JobFactory to that will be responsible for creating Job instances.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | package pl.codeleak.quartzdemo;import org.quartz.Job;import org.quartz.JobDetail;import org.quartz.Scheduler;import org.quartz.SchedulerException;import org.quartz.spi.JobFactory;import org.quartz.spi.TriggerFiredBundle;import javax.enterprise.inject.Any;import javax.enterprise.inject.Instance;import javax.inject.Inject;import javax.inject.Named;public class CdiJobFactory implements JobFactory { @Inject @Any private Instance<Job> jobs; @Override public Job newJob(TriggerFiredBundle triggerFiredBundle, Scheduler scheduler) throws SchedulerException { final JobDetail jobDetail = triggerFiredBundle.getJobDetail(); final Class<? extends Job> jobClass = jobDetail.getJobClass(); for (Job job : jobs) { if (job.getClass().isAssignableFrom(jobClass)) { return job; } } throw new RuntimeException("Cannot create a Job of type " + jobClass); }} |
As of now, all jobs can use dependency injection and inject other dependencies, including EJBs.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | package pl.codeleak.quartzdemo.ejb;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import javax.ejb.Stateless;@Statelesspublic class SimpleEjb { private static final Logger LOG = LoggerFactory.getLogger(SimpleEjb.class); public void doSomething() { LOG.info("Inside an EJB"); }}package pl.codeleak.quartzdemo;import org.quartz.Job;import org.quartz.JobExecutionContext;import org.quartz.JobExecutionException;import pl.codeleak.quartzdemo.ejb.SimpleEjb;import javax.ejb.EJB;import javax.inject.Named;public class SimpleJob implements Job { @EJB // @Inject will work too private SimpleEjb simpleEjb; @Override public void execute(JobExecutionContext context) throws JobExecutionException { simpleEjb.doSomething(); }} |
The last step is to modify SchedulerBean:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | package pl.codeleak.quartzdemo;import org.quartz.*;import org.quartz.impl.StdSchedulerFactory;import org.quartz.impl.matchers.GroupMatcher;import org.quartz.spi.JobFactory;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import javax.annotation.PostConstruct;import javax.annotation.PreDestroy;import javax.ejb.Singleton;import javax.ejb.Startup;import javax.inject.Inject;@Startup@Singletonpublic class SchedulerBean { private Logger LOG = LoggerFactory.getLogger(SchedulerBean.class); private Scheduler scheduler; @Inject private JobFactory cdiJobFactory; @PostConstruct public void scheduleJobs() { try { scheduler = new StdSchedulerFactory().getScheduler(); scheduler.setJobFactory(cdiJobFactory); JobKey job1Key = JobKey.jobKey("job1", "my-jobs"); JobDetail job1 = JobBuilder .newJob(SimpleJob.class) .withIdentity(job1Key) .build(); TriggerKey tk1 = TriggerKey.triggerKey("trigger1", "my-jobs"); Trigger trigger1 = TriggerBuilder .newTrigger() .withIdentity(tk1) .startNow() .withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(10)) .build(); scheduler.scheduleJob(job1, trigger1); scheduler.start(); printJobsAndTriggers(scheduler); } catch (SchedulerException e) { LOG.error("Error while creating scheduler", e); } } private void printJobsAndTriggers(Scheduler scheduler) throws SchedulerException { // not changed } @PreDestroy public void stopJobs() { // not changed }} |
Note: Before running the application add beans.xml file to WEB-INF directory.
1 2 3 4 5 6 7 8 9 | <?xml version="1.0" encoding="UTF-8"?><beans xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee bean-discovery-mode="all"></beans> |
You can now start the server and observe the results. Firstly, job and trigger was created:
1 2 3 | 12:08:19,592 INFO (MSC service thread 1-3) Quartz Scheduler: MyScheduler12:08:19,612 INFO (MSC service thread 1-3) Found job identified by my-jobs.job112:08:19,616 INFO (MSC service thread 1-3) Found trigger identified by m |
Our job is running (at about every 10 seconds):
1 2 | 12:08:29,148 INFO (MyScheduler_Worker-1) Inside an EJB12:08:39,165 INFO (MyScheduler_Worker-1) Inside an EJB |
Look also inside the Quartz tables, and you will see it is filled in with the data.
Test the application
The last thing I wanted to check was how the jobs are triggered in multiple instances. For my test, I just cloned the server configuration twice in IntelliJ and assigned different port offset to each new copy.
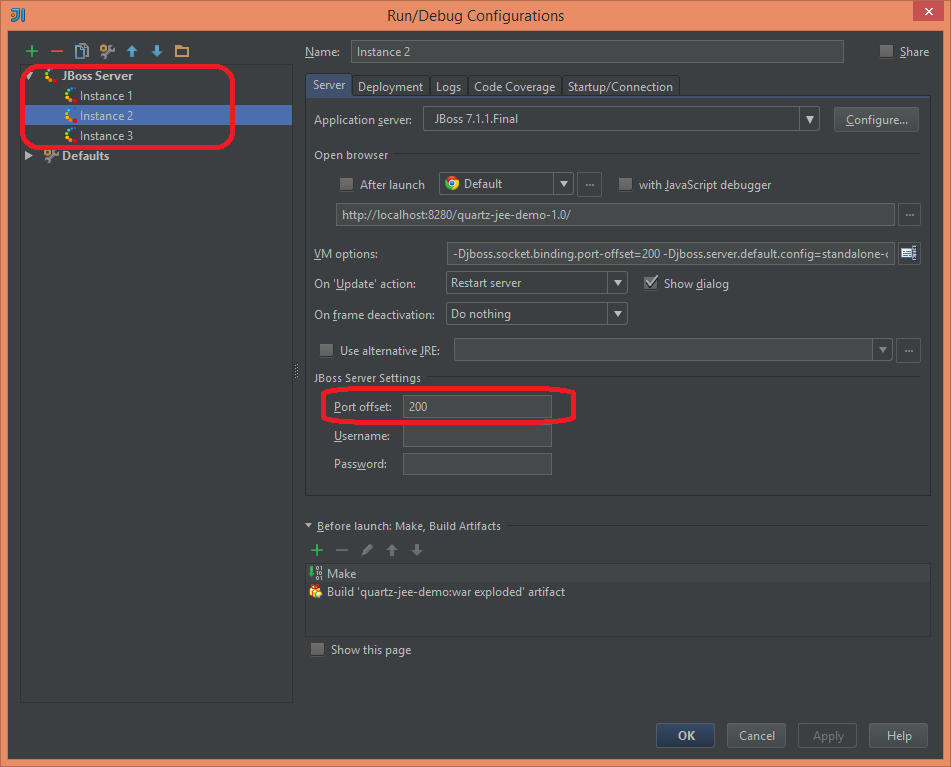
Additional change I needed to do is to modify the creation of jobs and triggers. Since all Quartz objects are stored in the database, creating the same job and trigger (with the same keys) will cause an exception to be raised:
1 | Error while creating scheduler: org.quartz.ObjectAlreadyExistsException: Unable to store Job : 'my-jobs.job1', because one already exists with this identification. |
I needed to change the code, to make sure that if the job/trigger exists I update it. The final code of the scheduleJobs method for this test registers three triggers for the same job.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | @PostConstructpublic void scheduleJobs() { try { scheduler = new StdSchedulerFactory().getScheduler(); scheduler.setJobFactory(cdiJobFactory); JobKey job1Key = JobKey.jobKey("job1", "my-jobs"); JobDetail job1 = JobBuilder .newJob(SimpleJob.class) .withIdentity(job1Key) .build(); TriggerKey tk1 = TriggerKey.triggerKey("trigger1", "my-jobs"); Trigger trigger1 = TriggerBuilder .newTrigger() .withIdentity(tk1) .startNow() .withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(10)) .build(); TriggerKey tk2 = TriggerKey.triggerKey("trigger2", "my-jobs"); Trigger trigger2 = TriggerBuilder .newTrigger() .withIdentity(tk2) .startNow() .withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(10)) .build(); TriggerKey tk3 = TriggerKey.triggerKey("trigger3", "my-jobs"); Trigger trigger3 = TriggerBuilder .newTrigger() .withIdentity(tk3) .startNow() .withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(10)) .build(); scheduler.scheduleJob(job1, newHashSet(trigger1, trigger2, trigger3), true); scheduler.start(); printJobsAndTriggers(scheduler); } catch (SchedulerException e) { LOG.error("Error while creating scheduler", e); }} |
In addition to the above, I added logging the JobExecutionContext in SimpleJob, so I could better analyze the outcome.
01 02 03 04 05 06 07 08 09 10 | @Overridepublic void execute(JobExecutionContext context) throws JobExecutionException { try { LOG.info("Instance: {}, Trigger: {}, Fired at: {}", context.getScheduler().getSchedulerInstanceId(), context.getTrigger().getKey(), sdf.format(context.getFireTime())); } catch (SchedulerException e) {} simpleEjb.doSomething();} |
After running all three server instances I observed the results.
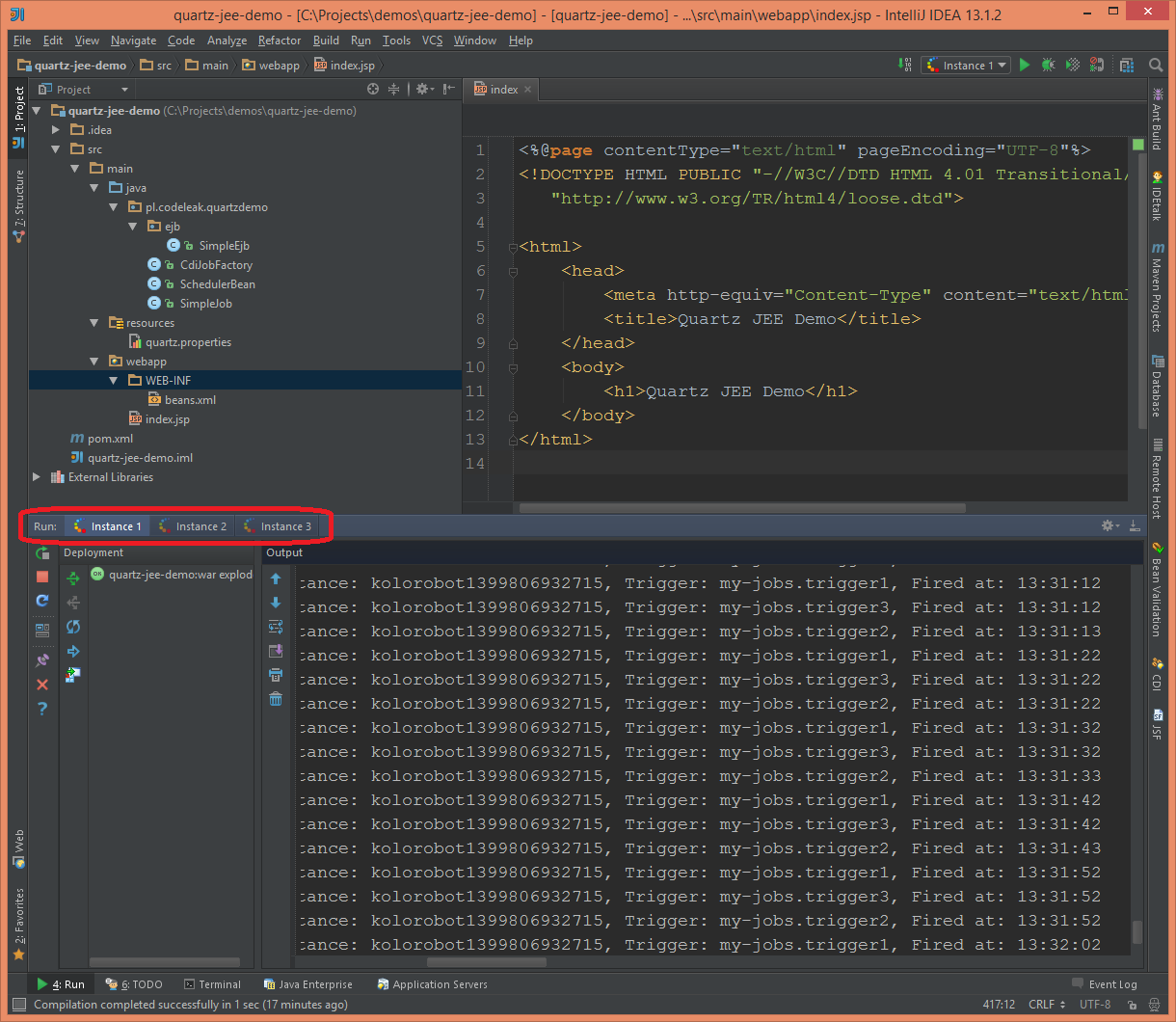
Job execution
I observed trigger2 execution on all three nodes, and it was executed on three of them like this:
1 2 3 4 5 | Instance: kolorobot1399805959393 (instance1), Trigger: my-jobs.trigger2, Fired at: 13:00:09Instance: kolorobot1399805989333 (instance3), Trigger: my-jobs.trigger2, Fired at: 13:00:19Instance: kolorobot1399805963359 (instance2), Trigger: my-jobs.trigger2, Fired at: 13:00:29Instance: kolorobot1399805959393 (instance1), Trigger: my-jobs.trigger2, Fired at: 13:00:39Instance: kolorobot1399805959393 (instance1), Trigger: my-jobs.trigger2, Fired at: 13:00:59 |
Similarly for other triggers.
Recovery
After I disconnected kolorobot1399805989333 (instance3), after some time I saw the following in the logs:
1 2 | ClusterManager: detected 1 failed or restarted instances.ClusterManager: Scanning for instance "kolorobot1399805989333"'s failed in-progress jobs. |
Then I disconnected kolorobot1399805963359 (instance2) and again this is what I saw in the logs:
1 2 3 | ClusterManager: detected 1 failed or restarted instances.ClusterManager: Scanning for instance "kolorobot1399805963359"'s failed in-progress jobs.ClusterManager: ......Freed 1 acquired trigger(s). |
As of now all triggers where executed by kolorobot1399805959393 (instance1)
Running on Wildfly 8
Without any change I could deploy the same application on WildFly 8.0.0. Similarly to JBoss 7.1.1 I added MySQL module (the location of modules folder is different on WildFly 8 – modules/system/layers/base/com/mysql/main. The datasource and the driver was defined exactly the same as shown above. I created a run configuration for WildFly 8:
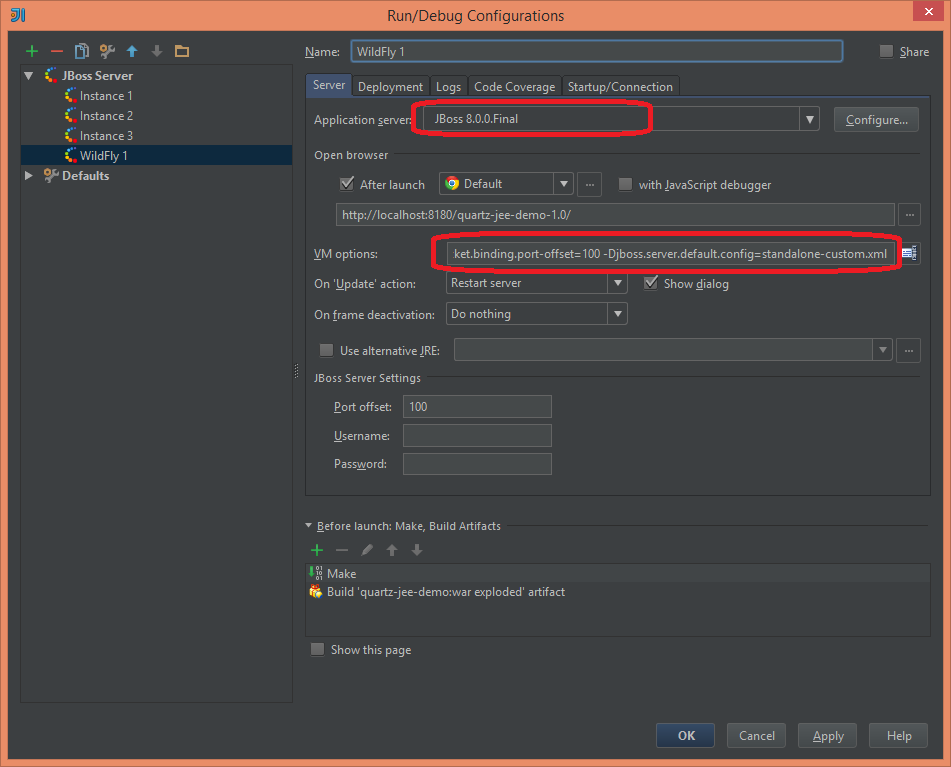
And I ran the application getting the same results as with JBoss 7.
I found out the WildFly seem to offer a database based store for persistent EJB timers, but I did not investigate it yet. Maybe something for another blog post.
Source code
- Please find the source code for this blog post on GitHub: https://github.com/kolorobot/quartz-jee-demo
| Reference: | HOW-TO: Quartz Scheduler with Clustering in JEE application with MySQL from our JCG partner Rafal Borowiec at the Codeleak.pl blog. |

Hi,
please don’t use modules/system/… for admin provided modules in wildlfy. using the old paths work quite fine and you can distinguish between wildfly provided and manually installed modules quite easy that way.