Message queues are useful in a number of situations; for example when we want to execute a task asynchronously, we enqueue it and some executor eventually completes it. Depending on the use case, the queues can give various guarantees of message persistence and delivery. For some use-cases, it is enough to have an in-memory message queue. For others, we want to be sure that once the message send completes, it is persistently enqueued and will be eventually delivered, despite node or system crashes.
To be really sure that messages are not lost, we will be looking at queues which:
- persist messages to disk
- replicate messages across the network
Ideally, we want to have 3 identical, replicated nodes containing the message queue.
There is a number of open-source messaging projects available, but only a handful supports both persistence and replication. We’ll evaluate the performance and characteristics of 4 message queues:

While SQS isn’t an open-source messaging system, it matches the requirements and I’ve recently benchmarked it, so it will be interesting to compare self-hosted solutions with an as-a-service one.
MongoDB isn’t a queue of course, but a document-based NoSQL database, however using some of its mechanisms it is very easy to implement a message queue on top of it.
By no way this aims to be a comprehensive overview, just an evaluation of some of the projects. If you know of any other messaging systems, which provide durable, replicated queues, let me know!
Update: As many readers pointed out (thx @tlockney, @Evanfchan, @conikeec and others), Kafka is missing! While it works a bit differently (consumers are stateful – clustered – they keep their offset), Kafka supports point-to-point messaging where each message is consumed by one consumer, so stay tuned for an updated version of the blog, this time with Kafka!
Testing methodology
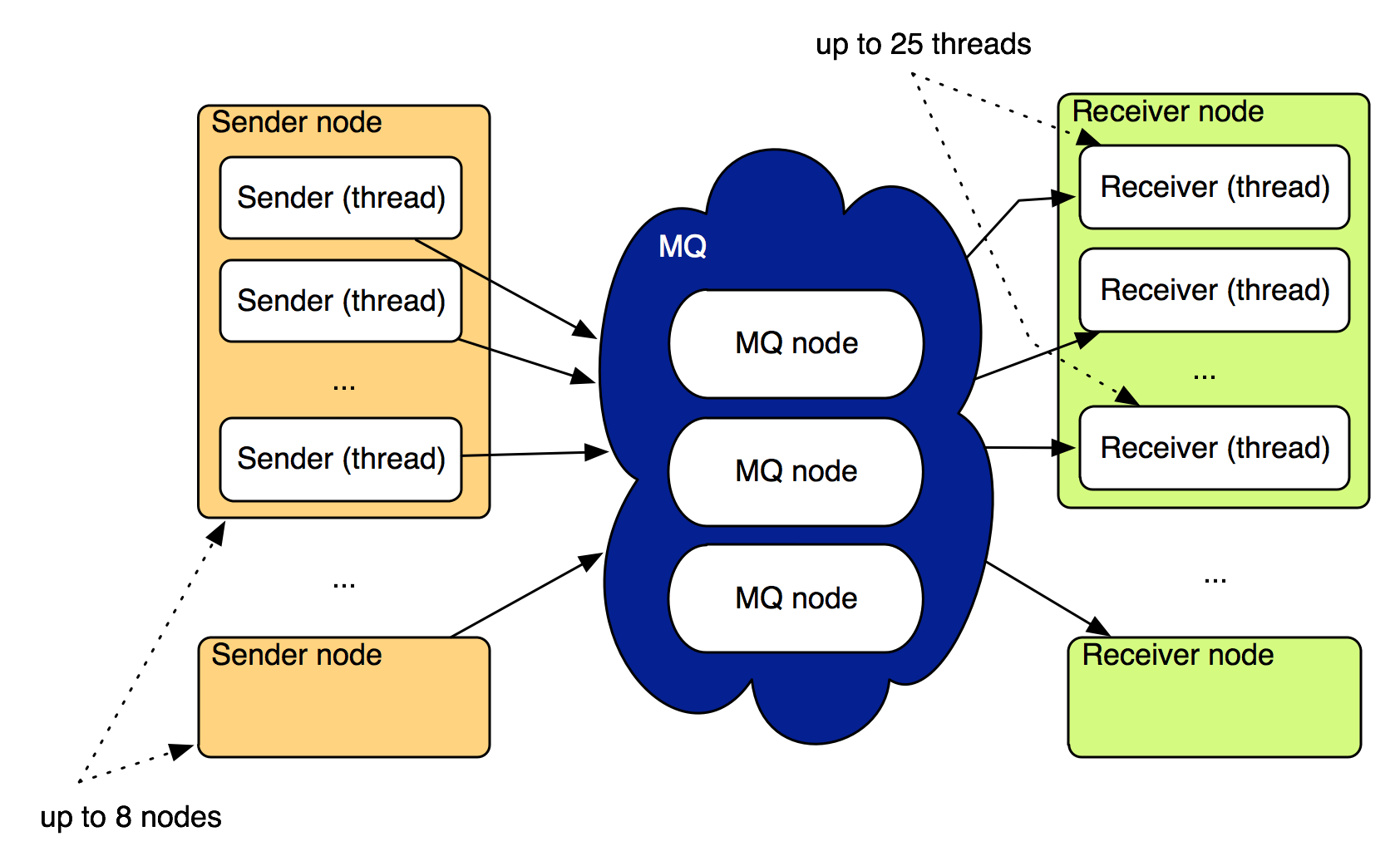
All sources for the tests are available on GitHub. The tests run a variable number of nodes (1-8); each node either sends or receives messages, using a variable number of threads (1-25), depending on the concrete test setup.
Each Sender thread tries to send the given number of messages as fast as possible, in batches of random size between 1 and 10 messages. For some queues, we’ll also evaluate larger batches, up to 100 or 1000 messages. After sending all messages, the sender reports the number of messages sent per second.
The Receiver tries to receive messages (also in batches), and after receiving them, acknowledges their delivery (which should cause the message to be removed from the queue). When no messages are received for a minute, the receiver thread reports the number of messages received per second.
The queues have to implement the Mq interface. The methods should have the following characteristics:
sendshould be synchronous, that is when it completes, we want to be sure (what sure means exactly may vary) that the messages are sentreceiveshould receive messages from the queue and block them; if the node crashes, the messages should be returned to the queue and re-deliveredackshould acknowledge delivery and processing of the messages. Acknowledgments can be asynchronous, that is we don’t have to be sure that the messages really got deleted.
The model above describes an at-least-once message delivery model. Some queues offer also other delivery models, but we’ll focus on that one to compare possibly similar things.
We’ll be looking at how fast (in terms of throughput) we can send and receive messages using a single 2 or 3 node message queue cluster.
Mongo
Mongo has two main features which make it possible to easily implement a durable, replicated message queue on top of it: very simple replication setup (we’ll be using a 3-node replica set), and various document-level atomic operations, like find-and-modify. The implementation is just a handful of lines of code; take a look at MongoMq.
We are also able to control the guarantees which send gives us by using an appropriate write concern when writing new messages:
WriteConcern.ACKNOWLEDGED(previouslySAFE) ensures that once a send completes, the messages have been written to disk (though it’s not a 100% durability guarantee, as the disk may have its own write caches)WriteConcern.REPLICA_ACKNOWLEDGEDensures that a message is written to the majority of the nodes in the cluster
The main downside of the Mongo-based queue is that:
- messages can’t be received in bulk – the
find-and-modifyoperation only works on a single document at a time - when there’s a lot of connections trying to receive messages, the collection will encounter a lot of contention, and all operations are serialised.
And this shows in the results: sends are faster then receives. But overall the performance is quite good!
A single-thread, single-node setup achieves 7 900 msgs/s sent and 1 900 msgs/s received. The maximum send throughput with multiple thread/nodes that I was able to achieve is about 10 500 msgs/s, while the maximum receive rate is 3 200 msgs/s, when using the “safe” write concern.
| Threads | Nodes | Send msgs/s | Receive msgs/s |
|---|---|---|---|
| 1 | 1 | 7 968,60 | 1 914,05 |
| 5 | 1 | 9 903,47 | 3 149,00 |
| 25 | 1 | 10 903,00 | 3 266,83 |
| 1 | 2 | 9 569,99 | 2 779,87 |
| 5 | 2 | 10 078,65 | 3 112,55 |
| 25 | 2 | 7 930,50 | 3 014,00 |
If we wait for the replica to acknowledge the writes (instead of just one node), the send throughput falls to 6 500 msgs/s, and the receive to about 2 900 msgs/s.
| Threads | Nodes | Send msgs/s | Receive msgs/s |
|---|---|---|---|
| 1 | 1 | 1 489,21 | 1 483,69 |
| 1 | 2 | 2 431,27 | 2 421,01 |
| 5 | 2 | 6 333,10 | 2 913,90 |
| 25 | 2 | 6 550,00 | 2 841,00 |
In my opinion, not bad for a very straightforward queue implementation on top of Mongo.
SQS
SQS is pretty well covered in my previous blog, so here’s just a short recap.
SQS guarantees that if a send completes, the message is replicated to multiple nodes. It also provides at-least-once delivery guarantees.
We don’t really know how SQS is implemented, but it most probably spreads the load across many servers, so including it here is a bit of an unfair competition: the other systems use a single replicated cluster, while SQS can employ multiple replicated clusters and route/balance the messages between them. But since we have the results, let’s see how it compares.
A single thread on single node achieves 430 msgs/s sent and the same number of msgs received.
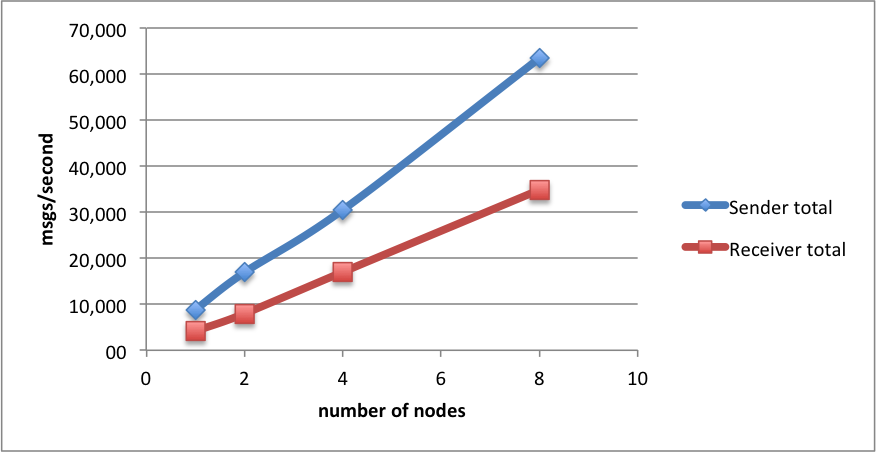
These results are not impressive, but SQS scales nicely both when increasing the number of threads, and the number of nodes. On a single node, with 50 threads, we can send up to 14 500 msgs/s, and receive up to 4 200 msgs/s.
On an 8-node cluster, these numbers go up to 63 500 msgs/s sent, and 34 800 msgs/s received.
RabbitMQ
RabbitMQ is one of the leading open-source messaging systems. It is written in Erlang, implements AMQP and is a very popular choice when messaging is involved. It supports both message persistence and replication, with well documented behaviour in case of e.g. partitions.
We’ll be testing a 3-node Rabbit cluster. To be sure that sends complete successfully, we’ll be using publisher confirms, a Rabbit extension to AMQP. The confirmations are cluster-wide, so this gives us pretty strong guarantees: that messages will be both written to disk, and replicated to the cluster (see the docs).
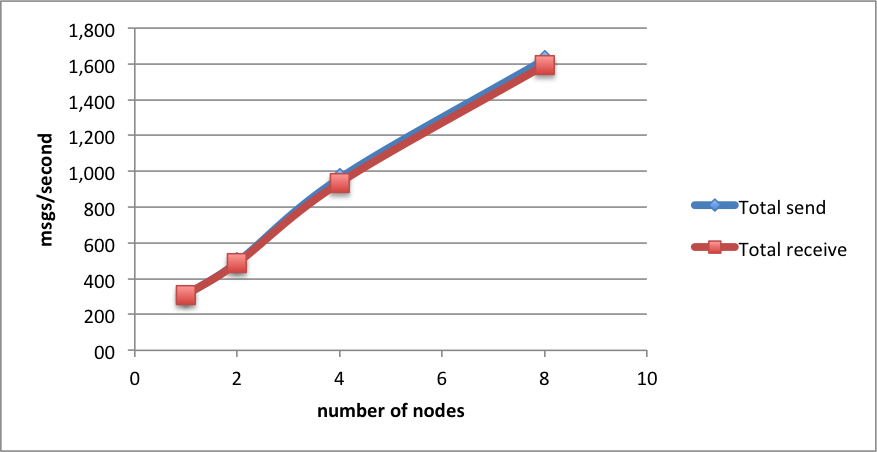
Such strong guarantees probably explain the poor performance. A single-thread, single-node gives us 310 msgs/s sent&received. This scales nicely as we add nodes, up to 1 600 msgs/s:
The RabbitMq implementation of the Mq interface is again pretty straightforward. We are using the mentioned publisher confirms, and setting the quality-of-service when receiving so that at most 10 messages are delivered unconfirmed.
Interestingly, increasing the number of threads on a node doesn’t impact the results. It may be because I’m incorrectly using the Rabbit API, or maybe it’s just the way Rabbit works. With 5 sending threads on a single node, the throughput increases just to 410 msgs/s.
Things improve if we send messages in batches up to 100 or 1000, instead of 10. In both cases, we can get to 3 300 msgs/s sent&received, which seems to be the maximum that Rabbit can achieve. Results for batches up to 100:
| Threads | Nodes | Send msgs/s | Receive msgs/s |
|---|---|---|---|
| 1 | 1 | 1 829,63 | 1 811,14 |
| 1 | 2 | 2 626,16 | 2 625,85 |
| 1 | 4 | 3 158,46 | 3 124,92 |
| 1 | 8 | 3 261,36 | 3 226,40 |
And for batches up to 1000:
| Threads | Nodes | Send msgs/s | Receive msgs/s |
|---|---|---|---|
| 1 | 1 | 3 181,08 | 2 549,45 |
| 1 | 2 | 3 307,10 | 3 278,29 |
| 1 | 4 | 3 566,72 | 3 533,92 |
| 1 | 8 | 3 406,72 | 3 377,68 |
HornetQ
HornetQ, written by JBoss and part of the JBossAS (implements JMS) is a strong contender. Since some time it supports over-the-network replication using live-backup pairs. I tried setting up a 3-node cluster, but it seems that data is replicated only to one node. Hence here we will be using a two-node cluster.
This raises a question on how partitions are handled; by default the backup server won’t automatically fail-over, the operator must do that (turn the backup server into a live one). That’s certainly a valid way of handling partitions, but usually not the preferred one. It is possible to add configuration to automatically detect that the primary died, but then we can easily end up with two live servers, and that rises the question what happens with the data on both primaries when the connection is re-established. Overall, the replication support and documentation is worse than for Mongo and Rabbit.
Also, as far as I understand the documentation (but I think it isn’t stated clearly anywhere), replication is asynchronous, meaning that even though we send messages in a transaction, once the transaction commits, we can be sure that messages are written only on the primary node’s journal. That is a weaker guarantee than in Rabbit, and corresponds to Mongo’s safe write concern.
The HornetMq implementation uses the core Hornet API. For sends, we are using transactions, for receives we rely on the internal receive buffers and turn off blocking confirmations (making them asynchronous). Interestingly, we can only receive one message at a time before acknowledging it, otherwise we get exceptions on the server. But this doesn’t seem to impact performance.
Speaking of performance, it is very good! A single-node, single-thread setup achieves 1 100 msgs/s. With 25 threads, we are up to 12 800 msgs/s! And finally, with 25 threads and 4 nodes, we can achieve 17 000 msgs/s.
| Threads | Nodes | Send msgs/s | Receive msgs/s |
|---|---|---|---|
| 1 | 1 | 1 108,38 | 1 106,68 |
| 5 | 1 | 4 333,13 | 4 318,25 |
| 25 | 1 | 12 791,83 | 12 802,42 |
| 1 | 2 | 2 095,15 | 2 029,99 |
| 5 | 2 | 7 855,75 | 7 759,40 |
| 25 | 2 | 14 200,25 | 13 761,75 |
| 1 | 4 | 3 768,28 | 3 627,02 |
| 5 | 4 | 11 572,10 | 10 708,70 |
| 25 | 4 | 17 402,50 | 16 160,50 |
One final note: when trying to send messages using 25 threads in bulks of up to 1000, I once got into a situation where the backup considered the primary dead even though it was working, and another time when the sending failed because the “address was blocked” (in other words, queue was full and couldn’t fit in memory), even though the receivers worked all the time. Maybe that’s due to GC? Or just the very high load?
In summary
As always, which message queue you choose depends on specific project requirements. All of the above solutions have some good sides:
- SQS is a service, so especially if you are using the AWS cloud, it’s an easy choice: good performance and no setup required
- if you are using Mongo, it is easy to build a replicated message queue on top of it, without the need to create and maintain a separate messaging cluster
- if you want to have high persistence guarantees, RabbitMQ ensures replication across the cluster and on disk on message send.
- finally, HornetQ has the best performance
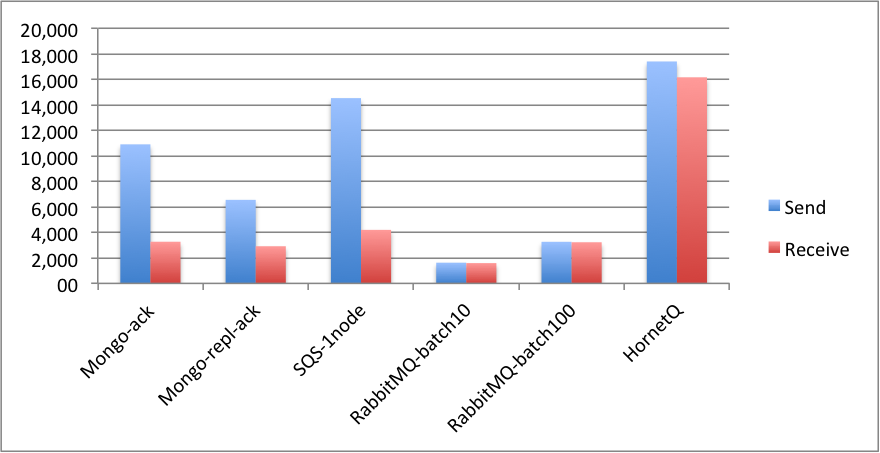
When looking only at the throughput, HornetQ is a clear winner (unless we include SQS with multiple nodes, but as mentioned, that would be unfair):
There are of course many other aspects besides performance, which should be taken into account when choosing a message queue, such as administration overhead, partition tolerance, feature set regarding routing, etc.
Do you have any experiences with persistent, replicated queues? Or maybe you are using some other messaging solutions?
| Reference: | Evaluating persistent, replicated message queues from our JCG partner Adam Warski at the Blog of Adam Warski blog. |

How about Akka?
Akka isn’t a replicated message queue – you can build one on top of it, but I’m not aware of one.