Around 3 months ago, I have posted one article explaining our approach and consideration to build Cloud Application. From this article, I will gradually share our practical design to solve this challenge.
As mentioned before, our final goal is to build a Saas big data analysis application, which will deployed in AWS servers. In order to fulfill this goal, we need to build distributed crawling, indexing and distributed training systems. 
The focus of this article is how to build the distributed crawling system. The fancy name for this system will be Black Widow.
Requirements
As usual, let start with the business requirement for the system. Our goal is to build a scalable crawling system that can be deployed on the cloud. The system should be able to function in an unreliable, high-latency network and can recover automatically from a partial hardware or network failure.
For the first release, the system can crawl from 3 kind of sources, Datasift, Twitter API and Rss feeds. The data crawled back are called
Comment. The Rss crawlers suppose to read public sources like website or blog. It is free of charge. DataSift and Twitter both provide proprietary APIs to access their streaming service. Datasift charges its users by comment count and the complexity of CSLD (Curated Stream Definition Language, their own query language). Twitter, in the other hand, offers free Twitter Sampler streaming.
In order to do cost control, we need to implement mechanism to limit the amount of comments crawled from commercial source like Datasift. As Datasift provided Twitter comment, it is possible to have single comment coming from different sources. At the moment, we did not try to eliminate and accept it as data duplication. However, this problem can be eliminated manually by user configuration (avoid choosing both Twitter and Datasift Twitter together).
For future extension, the system should be able to link up related comments to from a conversation.
Food for Thought
Centralized Architecture
Our first thought when getting requirement is to build the crawling on the nodes, which we called Spawn and let the hub, which we called Black Widow to manage the collaboration of effort among nodes. This idea was quickly accepted by team members as it allows the system to scale well with the hub doing limited work.
As any other centralized system, Black Widow suffers from single point of failure problem. To help easing this problem, we allow the node to function independently for a short period after losing connection to Black Widow. This will give the support team a breathing room to bring up backup server.
Another bottle neck in the system is data storage. For the volume of data being crawled (easily reach few thousands records per seconds), NoSQL is clearly the choice for storing the crawled comments. We have experiences working with Lucene and MongoDB. However, after research and some minor experiments, we choose Cassandra as the NoSQL database.
With that few thoughts, we visualize the distributed crawling system to be build following this prototype:
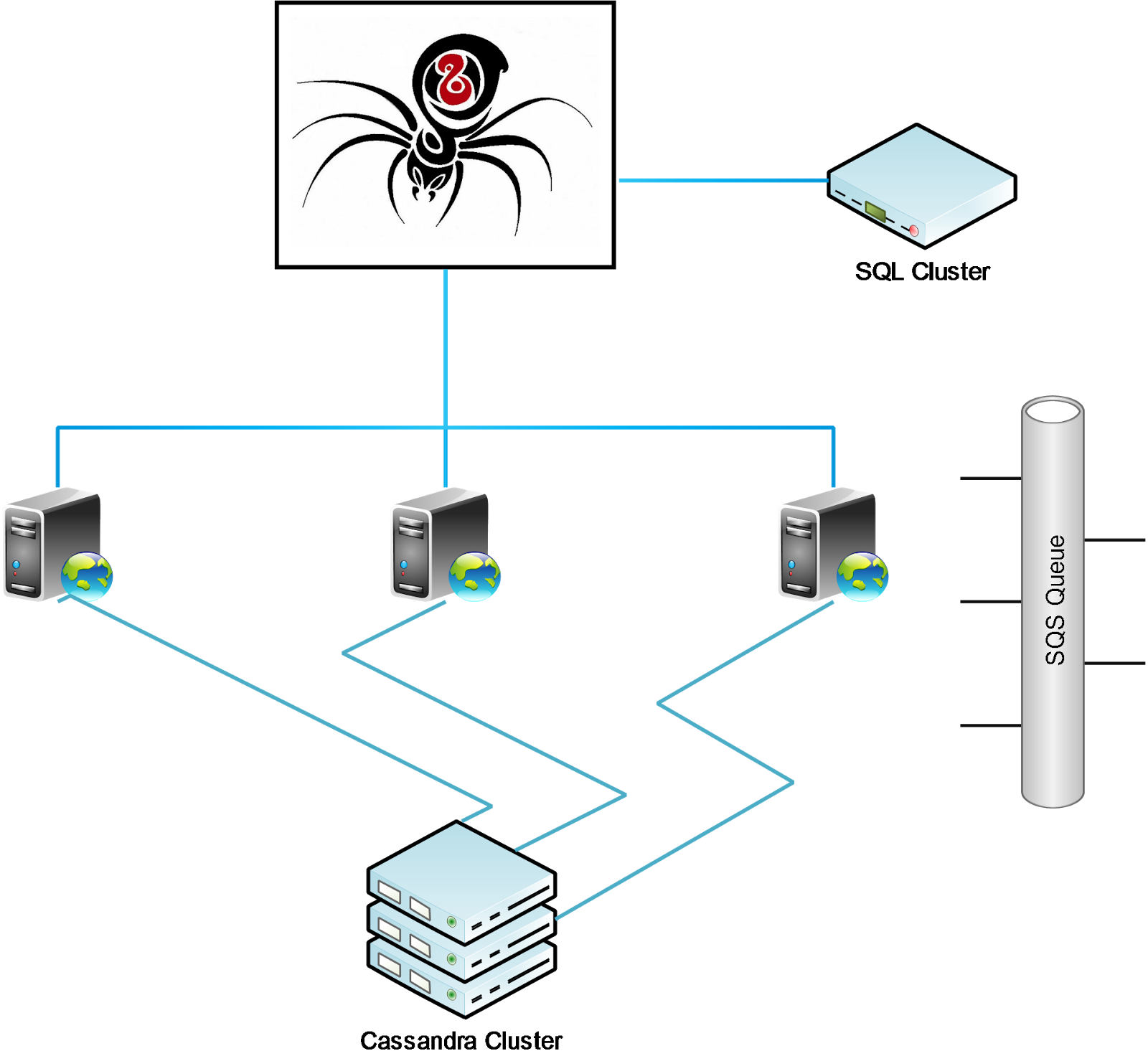
In the diagram above, Black Widow, or the hub is the only server that has access to the SQL database system. This is where we store the configuration for crawling. Therefore, all the Spawns, or crawling nodes are fully stateless. It simply wakes up, registers itself to Black Widow and does the assigned jobs. After getting the comments, the Spawn stores it to Cassandra cluster and also push it to some queues for further processing.
Brainstorming of possible issues
To explain the design to non-technical people, we like to relate the business requirement to a similar problem in real life so that it can be easier to understand. The similar problem we choose would be collaborating of efforts among volunteers.
Imagine if we need to do a lot of preparation work for the upcoming Olympic and decide to recruit volunteers all around the world to help. We do not know volunteers but the volunteers know our email, so they can contact us to register. Only then, we know their emails and may send tasks to them through email. We would not want to send one task to two volunteers or left some tasks unattended. We want to distribute the tasks evenly so that no volunteers are suffering too much.
Due to cost issue, we would not contact them through mobile phone. However, because email is less reliable, when sending out tasks to volunteers, we would request a confirmation. The task is consider assigned only when the volunteer replied with confirmation.
With above example, the volunteers represent Spawn nodes while email communication represent unreliable and high latency network. Here are some problems that we need to solve:
1/ Node failure
For this problems, the best way is to check regularly. If a volunteer stop responding to the regular progress check email, the task should be re-assign to someone else.
2/ Optimization of tasks assigning
Some tasks are related. Therefore assigning related tasks to the same person can help to reduce total effort. This happen with our crawling as well because some crawling configurations have similar search terms, grouping them together to share the streaming channel will help to reduce final bill.
Another concern is the fairness or ability to distribute the amount of works evenly among volunteers. The simplest strategy we can think of is Round Robin but with a minor tweak by remembering earlier assignments. Therefore, if a task is pretty similar to the tasks we assigned before, the task can be skipped from Round Robin selection and directly assign to the same volunteer.
3/ The hub is not working
If due to some reasons, our email server is down and we cannot contact volunteer any more, it is better to let the volunteers stop working on the assigning tasks. The main concern here is over-running of cost or wasted efforts. However, stopping working immediately is too hasty as temporary infrastructure issue may cause the communication problem.
Hence, we need to find a reasonable amount of time for the node to continue functioning after being detached from the hub.
4/ Cost control
Due to business requirement, there are two kinds of cost control that we need to implement. First is the total of comments being crawled per crawler and second is the total of comments crawled by all crawlers belong to the same user.
This is where we have a debate about the best approach to implement cost control. It is very straight forward to implement the limit for each crawler. We can simply pass this limit to the Spawn node and it will automatically stop the crawler when the limit is reached.
However, for the limit per user, it is not so straight forward and we have two possible approaches. For the simpler choice, we can send all the crawlers of one user to the same node. Then, similar to the earlier problem, the Spawn node knows the amount of comments collected and stops all crawlers when limit reached. This approach is simple but it limits the ability to distribute jobs evenly among nodes. The alternative approach is to let all the nodes retrieve and update a global counter. This approach creates huge network traffic internally and add considerable delay to comment processing time.
At this point, we temporarily choose the global counter approach. This can be considered again if the performance become a huge concern.
5/ Deploy on the cloud
As any other Cloud application, we can not put too much trust in the network or infrastructure. Here is how we make our application conform to the check-list mentioned in last article:
- Stateless: Our spawn node is stateless but the hub is not. Therefore, in our design, the nodes do actual work and the hub only collaborates efforts.
- Idempotence: We implement hashCode and equal methods for every crawler configuration. We store the crawler configurations in the Map or Set. Therefore, the crawler configuration can be sent multiple times without any other side effect. Moreover, our node selection approach ensure that the job will be sent to the same node.
- Data Access Object: We apply the JsonIgnore filter on every model objects to make sure no confidential data flying around in the network.
- Play Safe: We implement health-check API for each node and the hub itself. The first level of support will get notified immediately when anything wrong happened.
6/ Recovery
We try our best to make the system heal itself from partial failure. There are some type of failure that we can recover from:
- Hub failure: Node register itself to the hub when it start up. From then, it is the one way communication when only the hub send jobs to node and also poll for status update. The node is consider detached if it failed to get any contact from Hub for a pre-defined period. If a node is detached, it will clear all the job configurations and start registering itself to the hub again. If the incident is caused by hub failure, a new hub will fetch crawling configurations from database and start distributing jobs again. All the existing jobs on Spawn nodes will be cleared when the Spawn node go to detached mode.
- Node failure: When hub fail to poll a node, it will do a hard reset by removing all working jobs and re-distribute from beginning again to the working nodes. This re-distribution process help to ensure optimized distribution.
- Job failure: There are two kind of failures happened when the hub do sending and polling jobs. If a job is failed in the polling process but the Spawn node is still working well, Black Widow can re-assign the job to the same node again. The same thing can be done if the job sending failed.
Implementation
Data Source and Subscriber
In the initial thought, each crawler can open it own channel to retrieve data but this does not make sense any more when inspecting further. For Rss, we can scan all URLs once and find out the keywords that may belong to multiple crawlers. For Twitter, it supports up to 200 search terms for one single query. Therefore, it is possible for us to open single channel that serve multiple crawlers. For Datasift, it is quite rare, but due to human mistake or luck, it is possible to have crawlers with identical search terms.
This situation lead us to split out crawler to two entities: subscriber and data source. Subscriber is in charge of consuming the comments while data source is in charge of crawling the comments. With this design, if there are two crawlers with similar keywords, a single data source will be created to serve two subscribers, each processing the comments their own ways.
Data source will be created when and only when no similar data source exist. It starts working when having the first subscriber subscribe to it and retire when the last subscriber unsubscribe from it. With the help of Black Widow to send similar subscribers to the same node, we can minimize the amount of data sources created and indirectly, minimize the crawling cost.
Data Structure
The biggest concern of data structure is Thread Safe issue. In the Spawn node, we must store all running subscribers and data sources in memory. There are a few scenarios that we need to modify or access these data:
- When a subscriber hit the limit, it automatically unsubscribe from data source, which may lead to deactivation of data source.
- When Black Widow send a new subscriber to Spawn nodes.
- When Black Widow send a request to unsubscribe an existing subscriber.
- Health check API expose all running subscribers and data sources.
- Black Widow regularly polls the status of each assigned subscriber.
- The Spawn node regularly checks and disables orphan subscribers (subscriber which is not polled by Black Widow).
Another concern of data structure is idempotence of operations. Any of operation above can be missing or being duplicated. To handle this problem, here is our approach
- Implement hashCode and equals method for every subscriber and data source.
- We choose the Set or Map to store collection of subscribers and data sources. For records with identical hash code, Map will replace the record when there is new insertion but Set will skip the new record. Therefore, if we use Set, we need to ensure new records can replace old record.
- We use synchronized in data access code.
- If Spawn node receive a new subscriber that similar to existing subscriber, it will compare and prefer to update existing subscriber instead of replacing. This avoid the process of unsubscribing and subscribing identical subscribers, which may interrupt data source streaming.
Routing
As mentioned before, we need to find a routing mechanism that serve two purposes:
- Distribute the jobs evenly among Spawn nodes.
- Route similar jobs to the same nodes.
We solved this problem by generating an unique representation of each query named uuid. After that, we can use a simple modular function to find out the note to route:
int size = activeBwsNodes.size(); int hashCode = uuid.hashCode(); int index = hashCode % size; assignedNode = activeBwsNodes.get(index);
With this implementation, subscribers with similar uuid will always be sent to the same node and each node has equals chance of being selected to serve a subscriber.
This whole practice can be screwed up when there is change to the collection of active Spawn nodes. Therefore, Black Widow must clear up all running jobs and reassign from beginning whenever there is a node change. However, node change should be quite rare in production environment.
Handshake
Below is the sequence diagram of Black Widow and Node collaboration:
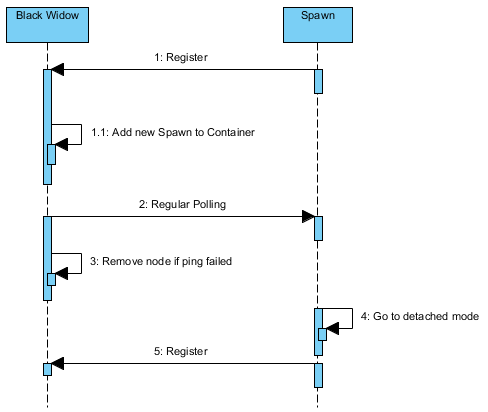
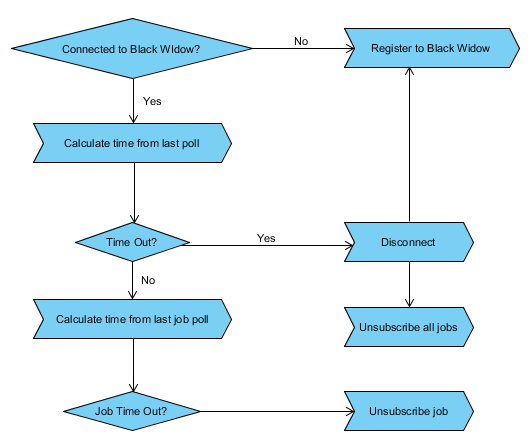
Black Widow does not know Spawn node. It wait for the Spawn node to register itself to the Black Widow. From there, Black Widow has the responsibility to poll the node to maintain connectivity. If Black Widow fail to poll a node, it will remove the node from the its container. The orphan node will eventually go to detached mode because it is not being polled any more. In this mode, Spawn node will clear existing jobs and try to register itself again.
The next diagram is the subscriber life-cycle:
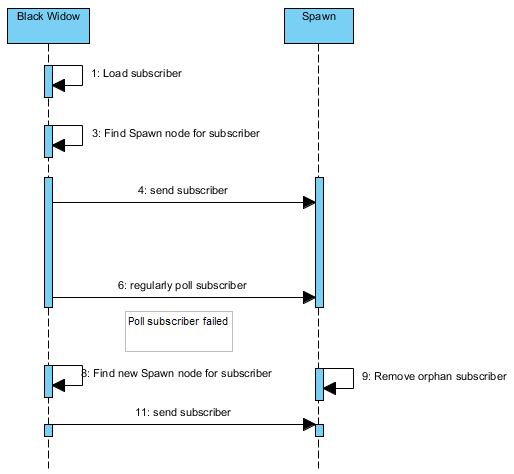
Similar to above, Black Widow has the responsibility of polling the subscribers it send to Spawn node. If a subscriber is not being polled by Black Widow anymore, Spawn node will treat the subscriber as orphan and remove it. This practice help to eliminate the threat of Spawn node running obsoleted subscriber.
On Black Widow, when a subscriber polling fails, it will try to get a new node to assign the job. If the Spawn node of the subscriber still available, it is likely that the same job will go to the same node again due to our routing mechanism we used.
Monitoring
In a happy scenario, all the subscribers are running, Black Widow is polling and nothing else happen. However, this is not likely to happen in real life. There will be changes in Black Widow and Spawn nodes from time to time, triggered by various events.
For Black Widow, there will be changes under following circumstances:
- Subscriber hit limit
- Found new subscriber
- Existing subscriber disabled by user
- Polling of subscriber fails
- Polling of Spawn node fails
To handle changes, Black Widow monitoring tool offers two services: hard reload and soft reload. Hard Reload happen on node change while Soft Reload happen on subscriber change. Hard Reload process takes back all running jobs, redistribute from beginning over available nodes. Soft Reload process removes obsoleted jobs, assigns new jobs and re-assigns failed jobs.
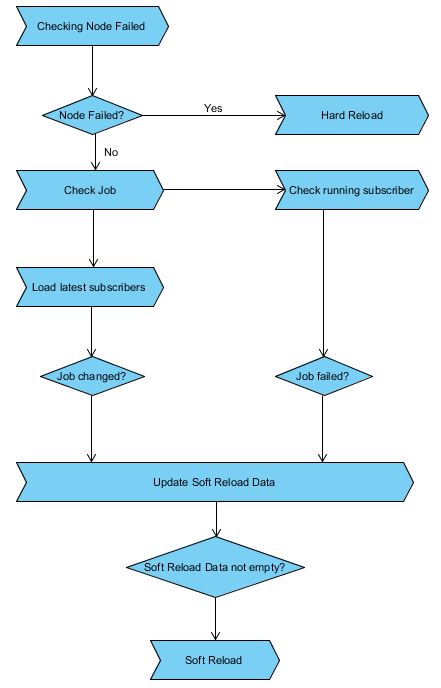
Compare to Black Widow, the monitoring of Spawn node is simpler. The two main concerns are maintaining connectivity to Black Widow and removing orphan subscribers.
Deployment Strategy
The deployment strategy is straight forward. We need to bring up Black Widow and at least one Spawn node. The Spawn node should know the URL of Black Widow. From then, the Health Check API will give use the amount of subscribers per node. We can integrate Health Check with AWS API to automatically bring up new Spawn node if existing nodes are overloaded. The Spawn node image will need to have Spawn application running as service. Similarly, when the nodes are not utilized, we can bring down redundant Spawn nodes.
Black Widow need special treatment due to its importance. If Black Widow fails, we can restart the application. This will cause all existing jobs on Spawn nodes to become orphan and all the Spawn nodes go to detached mode. Slowly, all the nodes will clean up itself and try to register again. Under default configuration, the whole restarting process will happen within 15 minutes.
Threats and possible improvement
When choosing centralized architecture, we know that Black Widow is the biggest risk to the system. While Spawn node failure only causes a minor interruption in the affected subscribers, Black Widow failure finally lead to Spawn nodes restart, which will take much longer time to recover.
Moreover, even the system can recover from partial, there still be interruption of service in recovery process. Therefore, if the polling requests failed too often due to unstable infrastructure, the operation will be greatly hampered.
Scalability is another concern for centralized architecture. We have not had a concrete amount of maximum Spawn nodes that the Black Widow can handle. Theoretically, this should be very high because Black Widow only do minor processing, most of its effort are on sending out HTTP requests. It is possible that network is the main limit factor for this architecture. Because of this, we let the Black Widow polling the nodes rather than the nodes polling Black Widow (other people do this, like Hadoop). With this approach, Black Widow may work at its own pace, not under pressure of Spawn nodes.
One of the first question we got is whether it is a Map Reduce problem and the answer is No. Each subscriber in our Distributed Crawling System processes its own comments and does not reporting result back to Black Widow. That why we do not use any Map Reduce product like Hadoop. Our monitor is business logic aware rather than purely infrastructure monitoring, that why we choose to build ourselves over using monitoring tools like Zoo Keeper or AKKA.
For future improvement, it is better to walk away from Centralized Architecture by having multiple hubs collaborating with each other. This should not be too difficult provided that the only time Black Widow accessing database is loading subscriber. Therefore, we can slice the data and let each Black Widow load a portion of it.
Another point that make me feel pretty unsatisfied is the checking of global counter for user limit. As the check happened on every comment crawled, this greatly increases internal network traffic and limit the scalability of system. The better strategy should be divide of quota based on processing speed. Black Widow can regulate and redistribute quota for each subscriber (on different nodes).
| Reference: | Distributed Crawling from our JCG partner Tony Nguyen at the Developers Corner blog. |
