Every 6 months at Canonical, the company behind Ubuntu, I work on something technical to test our tools first hand and to show others new ideas. This time around I created an Instant Big Data solution, more concretely “Instant Storm”.
Storm is now part of the Apache Foundation but previously Storm was build by Nathan Marz during his time at Twitter. Storm is a stream processing engine for real-time and distributed computation. You can use Storm to aggregate real-time flows of events, to do machine learning, for analytics, for distributed ETL, etc.
Storm is build out of several services and requires Zookeeper. It is a complex solution and non-trivial to deploy, integrate and scale. The first technical project I did at Canonical was to create a Storm Juju charm. Although I was able to automate the deployment of Storm, there were still problems because users still had to read about how to actually use Storm.
Instant Storm is the first effort to resolve this problem. I created a StormDeployer charm that can read a yaml file in which a developer can specify multiple topologies. For each you specify the name of the topology, the jar file, the location in Github, how to package the jar file, etc. Afterwards by uploading the yaml file to Github or any public web server and giving it the extension .storm anybody in the world is able to reuse the topologies instantly in two steps:
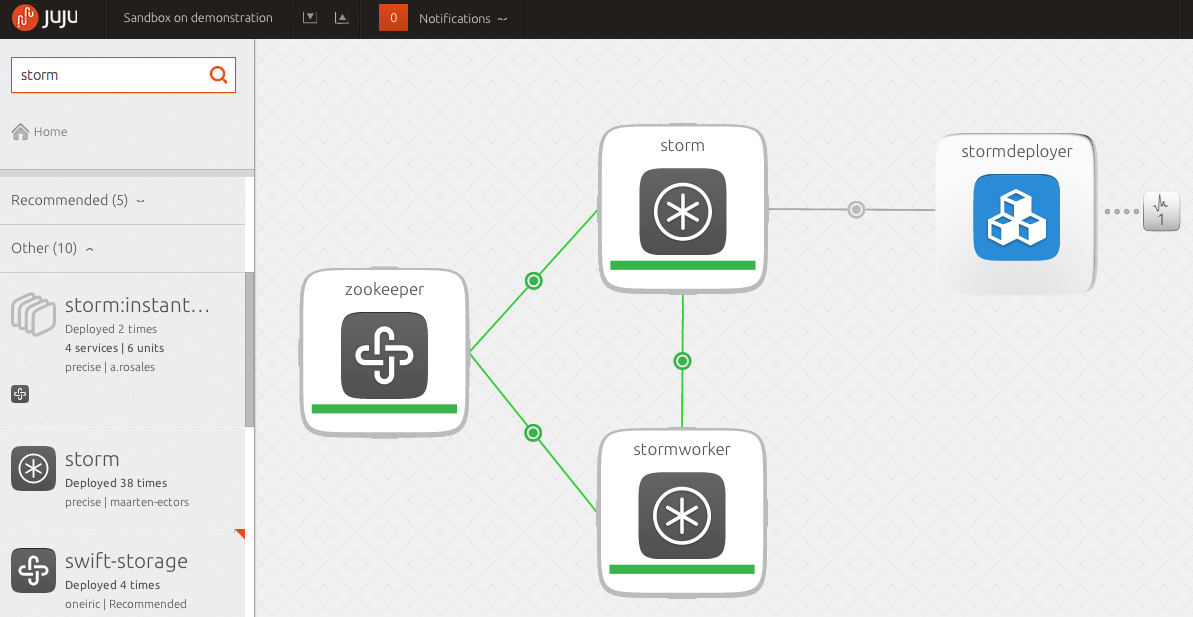
1. Deploy the Storm bundle that comes with Storm + Zookeeper + StormDeployer via a simple drag and drop in Juju:
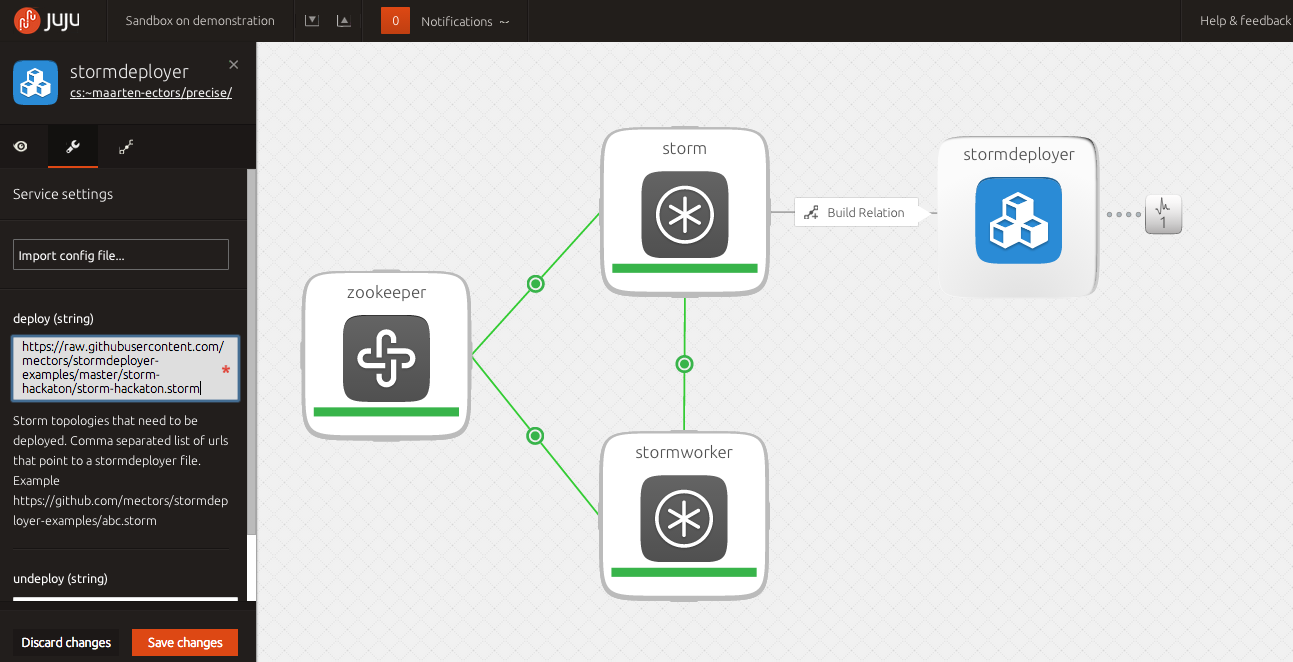
 2. Get a URL to a storm file and put it into the deploy field of the service settings of the StormDeployer :
2. Get a URL to a storm file and put it into the deploy field of the service settings of the StormDeployer :
Alternatively you can use the Juju command line:
1 | juju set stormdeployer "deploy=http://somedomain/somefile.storm" |
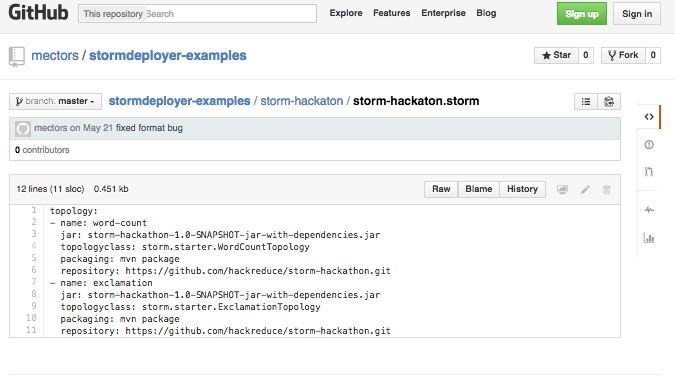
There are several examples already available on Github but here is one that for sure works:
https://raw.githubusercontent.com/mectors/stormdeployer-examples/master/storm-hackaton/storm-hackaton.storm
 The StormDeployer will download the project from Github, package the jar with Maven and upload the jar to Storm. You can check progress in the logs (/opt/storm/latest/log/deploy.log).
The StormDeployer will download the project from Github, package the jar with Maven and upload the jar to Storm. You can check progress in the logs (/opt/storm/latest/log/deploy.log).
This is the easiest way to deploy Storm on any public cloud, private cloud or if Ubuntu’s Metal-as-a-Service / MaaS is used on any bare metal server (X86, ARM64, Power 8). See here for Juju installation instructions.
This is a first version with some limitations. One of the really nice things to add would be to use Juju to make integrations between a topology and other charms dynamic. You can for instance create a spout or bolt that connects to the Kafka or Cassandra charms. Juju can automatically tell the topology the connection information and make updates to the running topologies should anything change. This would make it a lot more robust to run long running Storm topologies.
I am happy to donate my work to the Apache Foundation and guide anybody who wants to take ownership…
| Reference: | Instant Big Data Stream Processing = Instant Storm from our JCG partner Maarten Ectors at the Telruptive blog. |
