Working as a consultant I still meet quite often programmers, who have at most a vague understanding of JUnit and its proper usage. This gave me the idea to write a multi-part tutorial to explain the essentials from my point of view.
Despite the existence of some good books and articles about testing with the tool, maybe the hands-on approach of this mini-series might be appropriate to get one or two additional developers interested in unit testing – which would make the effort worthwhile.
Note that the focus of this chapter is on fundamental unit testing techniques rather than on JUnit features or API. More of the latter will be covered in the following posts. The nomenclature used to describe the techniques is based on the definitions presented in Meszaros’ xUnit Test Patterns [MES].
Previously on JUnit in a Nutshell
The tutorial started with a Hello World chapter, introducing the very basics of a test: how it is written, executed and evaluated. It continued with the post Test Structure, explaning the four phases (setup, exercise, verify and teardown) commonly used to structure unit tests.
The lessons were accompanied by a consistent example to make the abstract concepts easier to understand. It was demonstrated how a test case grows little by little – starting with happy path up to corner case tests, including expected exeptions.
Overall it was emphasized that a test is more than a simple verification machine and can serve also as kind of low level specification. Hence it should be developed with the highest possible coding standards one could think of.
Dependencies
It takes two to tango
Proverb
The example used throughout this tutorial is about writing a simple number range counter, which delivers a certain amount of consecutive integers, starting from a given value. A test case specifying the unit’s behavior might look in excerpts somewhat like this:
public class NumberRangeCounterTest {
private static final int LOWER_BOUND = 1000;
private static final int RANGE = 1000;
private static final int ZERO_RANGE = 0;
private NumberRangeCounter counter
= new NumberRangeCounter( LOWER_BOUND, RANGE );
@Test
public void subsequentNumber() {
int first = counter.next();
int second = counter.next();
assertEquals( first + 1, second );
}
@Test
public void lowerBound() {
int actual = counter.next();
assertEquals( LOWER_BOUND, actual );
}
@Test( expected = IllegalStateException.class )
public void exeedsRange() {
new NumberRangeCounter( LOWER_BOUND, ZERO_RANGE ).next();
}
[...]
}Note that I go with a quite compact test case here to save space, using implicit fixture setup and exception verification for example. For an in detail discussion about test structuring patterns see the previous chapter.
Note also that I stick with the JUnit build-in functionality for verification. I will cover the pro and cons of particular matcher libraries (Hamcrest, AssertJ) in a separate post.
While the NumberRangeCounter‘s initial description was sufficient to get this tutorial started, the attentive reader may have noticed that the approach was admittedly a bit naive. Consider for example that a program’s process might get terminated. To be able to reinitialize the counter properly on system restart, it should have preserved at least its latest state.
However persisting the counter’s state involves access to resources (database, filesystem or the like) via software components (database driver, file system API etc.) that are not part of the unit, aka system under test (SUT). This means the unit depends on such components, which Meszaros describes with the term depended-on component (DOC).
Unfortunaly this brings along testing related trouble in many respects:
- Depending on components we cannot control might impede the decent verification of a test specification. Just think of a real world web service that could be unavailable at times. This could be the cause of a test failure, although the SUT itself is working properly.
- DOCs might also slow down test execution. To enable unit tests to act as safety net the complete test-suite of a system under development has to be executed very often. This is only feasible if each test runs incredible fast. Again think of the web service example.
- Last but not least a DOC’s behavior may change unexpectedly due to the usage of a newer version of a third party library for example. This shows how depending directly on components we cannot control makes a test fragile.
So what can we do to circumvent this problems?
Isolation – A Unit Tester’s SEP Field
An SEP is something we can’t see, or don’t see, or our brain doesn’t let us see, because we think that it’s Somebody Else’s Problem….
Ford Prefect
As we do not want our unit tests to be dependent on the behavior of a DOC, nor want them to be slow or fragile, we strive to shield our unit as much as possible from all other parts of the software. Flippantly spoken we make these particular problems the concern of other test types – thus the joking SEP Field quote.
In general this principle is known as Isolation of the SUT and expresses the aspiration to test concerns seperately and keep tests independent of each other. Practically this implies that a unit should be designed in a way that each DOC can be replaced by a so called Test Double, which is a lightweight stand-in component for the DOC [MES1].
Related to our example we might decide not to access a database, file-system or the like directly from within the unit itself. Instead we may choose to separate this concern into a shielding interface type, without being interested in how a concrete implementation would look like.
While this choice is certainly also reasonable from a low-level design point of view, it does not explain how the test double is created, installed and used throughout a test. But before elaborating on how to use doubles, there is one more topic that needs to be discussed.
Indirect Inputs and Outputs
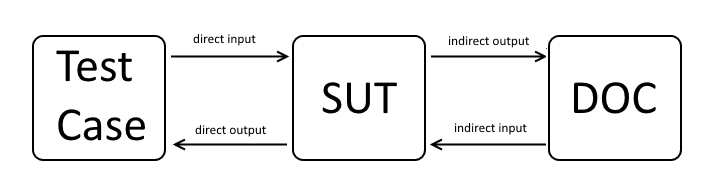
So far our testing efforts confronted us with direct inputs and outputs of the SUT only. I.e. each instance of NumberRangeCounter is equipped with a lower bound and a range value (direct input). And after each call to next() the SUT returns a value or throws an exception (direct output) used to verified the SUT’s expected behavior.
But now the situation gets a bit more complicated. Considering that the DOC provides the latest counter value for SUT initialization, the result of next() depends on this value. If a DOC provides the SUT input in this manner, we talk about indirect inputs.
Conversely assuming that each call of next() should persist the counter’s current state, we have no chance to verify this via direct outputs of the SUT. But we could check that the counter’s state has been delegated to the DOC. This kind of delegation is denoted as indirect output.
With this new knowledge we should be prepared to proceed with the NumberRangeCounter example.
Controlling Indirect Inputs with Stubs
From what we have learned it would probably be a good idea to separate the counter’s state-preserving into a type of its own. This type would isolate the SUT from the actual storage implementation, since from the SUT’s point of view we are not interested in how the problem of preservation is actually solved. For that reason we introduce the interface CounterStorage.
Although there is no real storage implementation so far, we can go ahead using a test double instead. It is trivial to create a test double type at this point as the interface has no methods yet.
public class CounterStorageDouble implements CounterStorage {
}To provide the storage for a NumberRangeCounter in a loosely coupled way we can use dependency injection. Enhancing the implicit fixture setup with a storage test double and injecting it into the SUT may look like this:
private CounterStorage storage;
@Before
public void setUp() {
storage = new CounterStorageDouble();
counter = new NumberRangeCounter( storage, LOWER_BOUND, RANGE );
}After fixing the compile errors and running all tests the bar should remain green, as we have not changed any behavior yet. But now we want the first call of NumberRangeCounter#next() to respect the storage’s state. If the storage provides a value n within the counter’s defined range, the first call of next() should also return n, which is expressed by the following test:
private static final int IN_RANGE_NUMBER = LOWER_BOUND + RANGE / 2;
[...]
@Test
public void initialNumberFromStorage() {
storage.setNumber( IN_RANGE_NUMBER );
int actual = counter.next();
assertEquals( IN_RANGE_NUMBER, actual );
}Our test double must provide a deterministic indirect input, in our case the IN_RANGE_NUMBER. Because of this it is equipped with the value using setNumber(int). But as the storage is not used yet the test fails. To change this it is about time to declare the CounterStorage‘s first method:
public interface CounterStorage {
int getNumber();
}Which allows us to implement the test double like this:
public class CounterStorageDouble implements CounterStorage {
private int number;
public void setNumber( int number ) {
this.number = number;
}
@Override
public int getNumber() {
return number;
}
}As you can see the double implements getNumber() by returning a configuration value fed by setNumber(int). A test double that provides indirect inputs in this way is called a stub. Now we would be able to implement the expected behaviour of NumberRangeCounter and pass the test.
If you think that get/setNumber make poor names to describe a storage’s behaviour, I agree. But it eases the post’s evolution. Please feel invited to make well conceived refactoring proposals…
Indirect Output Verification with Spies
To be able to restore a NumberRangeCounter instance after system restart, we expect that each state change of a counter gets persisted. This could be achieved by dispatching the current state to the storage each time a call to next() occurs. Because of this we add a method setNumber(int) to our DOC type:
public interface CounterStorage {
int getNumber();
void setNumber( int number );
}What an odd coincidence that the new method has the same signature as the one used to configure our stub! After amending that method with @Override it is easy to reuse our fixture setup also for the following test:
@Test
public void storageOfStateChange() {
counter.next();
assertEquals( LOWER_BOUND + 1, storage.getNumber() );
}Compared to the initial state we expect the counter’s new state to be increased by one after a call to next(). More important we expect this new state to be passed on to the storage DOC as an indirect output. Unfortunately we do not witness the actual invocation, so we record the result of the invocation in our double’s local variable.
The verification phase deduces that the correct indirect output has been passed to the DOC, if the recorded value matches the expected one. Recording state and/or behavior for later verification, described above in its simplest manner, is also denoted as spying. A test double using this technique is therefore called a spy.
What About Mocks?
There is another possibility to verify the indirect output of next() by using a mock. The most important characteristic of this type of double is, that the indirect output verification is performed inside the delegation method. Furthermore it allows to ensure that the expected method has actually been called:
public class CounterStorageMock implements CounterStorage {
private int expectedNumber;
private boolean done;
public CounterStorageMock( int expectedNumber ) {
this.expectedNumber = expectedNumber;
}
@Override
public void setNumber( int actualNumber ) {
assertEquals( expectedNumber, actualNumber );
done = true;
}
public void verify() {
assertTrue( done );
}
@Override
public int getNumber() {
return 0;
}
}A CounterStorageMock instance is configured with the expected value by a constructor parameter. If setNumber(int) is called, it is immediately checked whether the given value matches the expected one. A flag stores the information that the method has been called. This allows to check the actual invocation using the verify() method.
And this is how the storageOfStateChange test might look like using a mock:
@Test
public void storageOfStateChange() {
CounterStorageMock storage
= new CounterStorageMock( LOWER_BOUND + 1 );
NumberRangeCounter counter
= new NumberRangeCounter( storage, LOWER_BOUND, RANGE );
counter.next();
storage.verify();
}As you can see there is no specification verification left in the test. And it seems strange that the usual test structure has been twisted a bit. This is because the verification condition gets specified prior to the exercise phase in the middle of the fixture setup. Only the mock invocation check is left in the verify phase.
But in return a mock provides a precise stacktrace in case behavior verification fails, which can ease problem analysis. If you take a look at the spy solution again, you will recognize that a failure trace would point to the verify section of the test, only. There would be no information about the line of production-code that has actually caused the test to fail.
This is completely different with a mock. The trace would let us identify exactly the position where setNumber(int) was called. Having this information we could easily set a break point and debug the problematic matter.
Due to the scope of this post I confined test double introduction on stubs, spies and mocks. For a short explanation on the other types you might have a look at Martin Fowler‘s post TestDouble, but the in-depth explanation of all types and their variations can be found in Meszaros’ xUnit Test Patterns book [MES].
A good comparison of mock vs. spy based on test double frameworks (see next section) can be found in Tomek Kaczanowski‘s book Practical Unit Testing with JUnit and Mockito [KAC].
After reading this section you may have the impression that writing all those test doubles is tedious work. Not very surprisingly, libraries have been written to simplify double handling considerably.
Test Double Frameworks – The Promised Land?
If all you have is a hammer, everything looks like a nail
Proverb
There are a couple of frameworks, developed to ease the task of using test doubles. Unfortunately these libraries do not always a good job with respect to a precise Test Double Terminology. While e.g. JMock and EasyMock focus on mocks, Mockito is despite its name spy centric. Maybe that is why most people talk about mocking, regardless of what kind of double they are actually using.
Nevertheless there are indications that Mockito is the preferred test double tool at the time being. I guess this is because it provides a good to read fluent interface API and compensates the drawback of spies mentionend above a bit, by providing detailed verification failure messages.
Without going into detail I provide a version of the storageOfStateChange() test, that uses Mockito for spy creation and test verification. Note that mock and verify are static methods of the type Mockito. It is common practice to use static import with Mockito expressions to improve readability:
@Test
public void storageOfStateChange() {
CounterStorage storage = mock( CounterStorage.class );
NumberRangeCounter counter
= new NumberRangeCounter( storage, LOWER_BOUND, RANGE );
counter.next();
verify( storage ).setNumber( LOWER_BOUND + 1 );
}There has been written a lot about whether to use such tools or not. Robert C. Martin for example prefers hand written doubles and Michael Boldischar even considers mocking frameworks harmful. The latter is describing just plain misuse in my opinion and for once I disagree with Martin saying ‘Writing those mocks is trivial.’
I have been using hand-written doubles by myself for years before I discovered Mockito. Instantly I was sold to the fluent syntax of stubbing, the intuitive way of verification and I considered it an improvment to get rid of those crabbed double types. But this surely is in the eye of the beholder.
However I experienced that test double tools tempt developers to overdo things. For instance it is very easy to replace third-party components, which otherwise might be expensive to create, with doubles. But this is considered a bad practice and Steve Freeman and Nat Pryce explain in detail why you should only mock types that you own [FRE_PRY].
Third-party code calls for integration tests and an abstracting adapter layer. The latter is actually what we have indicated in our example by introducing the CounterStorage. And as we own the adapter, we can replace it safely with a double.
The second trap one easily walks into is writing tests, where a test double returns another test double. If you come to this point you should reconsider the design of the code you are working with. It probably breaks the law of demeter, which means that there might be something wrong with the way your objects are coupled together.
Last but not least if you think about to go with a test double framework you should keep in mind that this is usually a long term decision affecting a whole team. It is probably not the best idea to mix different frameworks due to a coherent coding style and even if you use only one, each (new) member has to learn the tool specific API.
Before you start using test doubles extensively you might consider to read Martin Fowler’s Mocks Aren’t Stubs that compares classical vs. mockist testing, or Robert C. Martin’s When to Mock that introduces some heuristics to find the golden ratio between no doubles and too many doubles. Or as Tomek Kaczanowski puts it:
‘Excited that you can mock everything, huh? Slow down and make sure that you really need to verify interactions. Chances are you don’t.’ [KAC1]
Conclusion
This chapter of JUnit in a Nutshell discussed the implications of unit dependencies for testing. It illustrated the principle of isolation and showed how it can be put into practice by replacing DOCs with test doubles. In this context the concept of indirect in- and outputs was presented and its relevance for testing was described.
The example deepened the knowledge with hands-on examples and introduced several test double types and their purpose of use. Finally a short explanation of test double frameworks and their pros and cons brought this chapter to an end. It was hopefully well-balanced enough to provide a comprehensible overview of the topic without being trivial. Suggestions for improvements are of course highly appreciated.
The tutorial’s next post will cover JUnit features like Runners and Rules and show how to use them by means of the ongoing example.
References
[MES] xUnit Test Patterns, Gerard Meszaros, 2007
[MES1] xUnit Test Patterns, Chapter 5, Principle: Isolate the SUT, Gerard Meszaros, 2007
[KAC] Practical Unit Testing with JUnit and Mockito, Appendix C. Test Spy vs. Mock, Tomek Kaczanowski, 2013
[KAC1] Bad Tests, Good Tests, Chapter 4, Maintainability,Tomek Kaczanowski, 2013
[FRE_PRY] Growing Object-Oriented Software, Guided by Tests, Chapter 8, Steve Freeman, Nat Pryce, 2010
| Reference: | JUnit in a Nutshell: Test Isolation from our JCG partner Frank Appel at the Code Affine blog. |
