This is the third post in a series where we analyze the results of a survey conducted in October 2014. If you have not already done so, I recommend to start with the first two posts in the series: problem severity analysis and monitoring domain analysis. This post focuses on troubleshooting / root cause detection.
The background to this survey section: once you are aware of a performance issue and have understood that its impact on end users is high enough to warrant action, you go through the following process:
- Reproducing the issue. You rarely start with enough information, so the first step often involves reproducing the issue in order to start gathering more evidence.
- Gathering evidence. To understand what is actually happening under the hood, you harvest more information (for example via logging, thread/heap dumps, etc) to make sense of the situation.
- Interpreting evidence. After having collecting the evidence, it might still be tricky to make any sense of it. Looking at your very first heap dump and trying to figure out the actual cause of a memory leak is a good example where the interpretation part might take quite a bit of time.
- Linking the evidence to the actual root cause. After having finally made sense of the evidence, you can start discovering links to the actual code or configuration item causing the issue at hand.
The above process is often completely informal, but in most cases it is anyhow present. To understand the landscape, we analyzed the current situation by asking respondents the following questions:
- Were you able to reproduce the issue?
- How did you gather evidence to find the root cause?
- What tools did you use to gather evidence?
- What was the actual underlying root cause?
Reproducing the issue.
So, as we see, in order to get evidence you first need to reproduce the issue (at will preferably). When we asked this question, the respondents said the following:

We can see that 9% of respondents did not even need to reproduce the issue, potentially because of having enough evidence already. However, 27% of the audience was unable to reproduce the issue, which sets up a rather nasty roadblock onto the path towards solution – without the possibility to reproduce the problem, most troubleshooting tools leave you empty-handed. In this situation the whole process often becomes a painful trial-and-error nightmare.
Tooling and techniques used to gather evidence
When you are able to reproduce the issue, the goal of the next step is to gather more evidence. For this there exist a large variety of tools and techniques. In our survey we asked the respondents to list their arsenal. The 284 respondents listed the following 1,101 options:
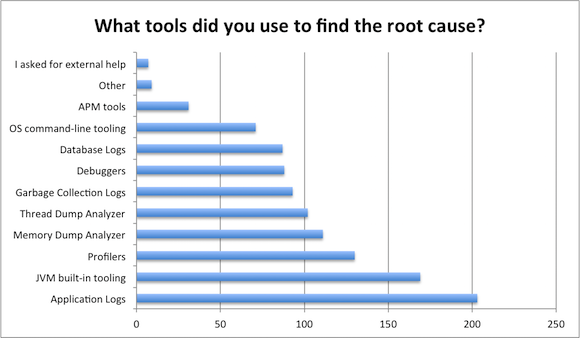
The most common source for evidence was clearly application log – 71% of the respondents confirmed that this was one of the sources used. This should not catch anyone by surprise, especially when you recall that the majority of respondents had engineering background. After all, the application log is written by developers themselves, so this a rather familiar territory to start hunting down any issues.
The second most-commonly-used technique for evidence gathering was to use JVM built-in tooling (such as jconsole, jmc, jstat, jmap, etc). 60% of the respondents were using these tools to progress towards finding the actual root cause. If we recall again that most of the respondents were engineers, then again it starts to make sense – JVM-embedded tools are well-known to engineers and are thus lot more frequently used than the OS built-in tools operations are likely to prefer.
Third place in the podium was claimed by profilers – tools such as Yourkit and JProfiler were listed in 46% of the answers. Indeed, if you can stand the overhead they pose, profilers are decent tools for the job in many cases, so the position should be well justified.
Next, it was time to analyze both heap dumps and thread dumps. 39% and 36% of the responses correspondingly listed dump analyzing as one of the techniques used. Considering the rather low-level tooling in this area it is somewhat surprising how often these tools end up being used.
The next group of tools and techniques involved in finding the root cause contains GC logs, debuggers, database logs and OS-level tooling. These tools were mentioned in between 25% and 32% of the cases. Especially OS tooling was surprisingly unpopular – considering the information you can get via sar, top, iostat and alikes it must be somehow correlated to the low number of operations people responding to the survey.
At the other end of the spectrum we have seven respondents honestly saying that they turned to external help. And 31, or 11% of the respondents who managed to find the root cause using APM tools. This matches our experience – current APM tooling is good at measuring the impact of performance incidents, especially if measured in terms of user experience. Most APM providers are also good at localizing the faulty node in your infrastructure. However, at this level the insight given by APMs usually stops and various other tools take over.
The sheer number of tools used in this phase definitely exceeded our expectations. An average user applied no less than four different tools before managing to gather enough evidence.
Actual root cause
Finding out what was the actual root cause triggering the performance incident was among the last questions we asked. The 778 responses we got were divided as follows:

In this section we have to admit that launching a survey by a company most known by its memory leak detection capabilities has definitely skewed the results. According to our results, memory leaks are by far the most common performance bottleneck, which we actually refuse to believe ourselves.
The next two root causes in line – either creating too many database queries or inefficient database queries are actually in line with what many would expect. 36% of the respondents listed one of these problems as the root cause for the performance issue at hand.
Amazingly common were synchronization issues – 24% of the respondents listed poor synchronization as a root cause for the performance bottleneck. As we have just recently released solutions in this area, it served as a nice confirmation to our own measurements. Other than this – considering that most Java EE developers should be rather well isolated from the concurrent algorithms it was still a moderately surprising outcome.
Poor caching and inefficient GC were listed next with 22% and 21% of respondents referring to these issues as a root cause. These two can indeed be looked together as often the first triggers the second – poorly built caches tend to trash a lot triggering vicious loops for GC to fight.
Interpreting the rest of the root causes would extend the length of the post beyond the reasonable length. One more thing worth noting is the noticeable amount (10%) of respondents honestly saying that they do not have a clue what caused the performance error. This again confirms the fact that root cause detection is a complex domain, desperately in need for improved tooling.
| Reference: | Java performance tuning survey results (part III) from our JCG partner Ivo Mägi at the Plumbr Blog blog. |
