While preparing for my talk at QCon SF 2014, I wanted to investigate a theory around how micro-benchmarks are not a useful reflection of how software may behave when run as part of a larger application. Specifically due contention in the last-level cache (L3* in current Intel CPUs).
An Example
Last year while working on a system to store market data, I needed a time series data store. I’d used LevelDB to solve a similar problem in the past and looked at using it again. The system I was building had a reasonably high throughput requirement (160K ops/sec). I built a micro-benchmark around the data I was trying to store in order to verify that that LevelDB would be sufficiently fast. It managed to clock in at around 400K ops/sec, which suggested that it would be a workable solution. However, when I merged the code into our main application an ran it within our end to end performance testing environment and it was unable to keep up the aforementioned throughput rate.
My suspicion is when running the code within the micro-benchmark it had the whole L3 cache to itself. When running as part of a larger application, with a number of other busy threads running concurrently, the shared L3 cache becomes a point of contention significantly impacting the throughput of the data store. The problem with a contended L3 is that each thread will be constantly replacing the values in that cache pushing out the cache lines of the other thread, meaning there is a much greater probability of the memory access missing cache and needing to access the data from main memory.
CPU Architecture Refresher
If you have a general interest in computing performance and haven’t been hiding under a rock for the past 10 years, then you are probably aware that modern CPUs have a multi-layer memory hierarchy; consisting of a series of progressively larger and slower** caches between the processor and main memory. The diagram below shows the layout of a Intel Nehalem CPU.
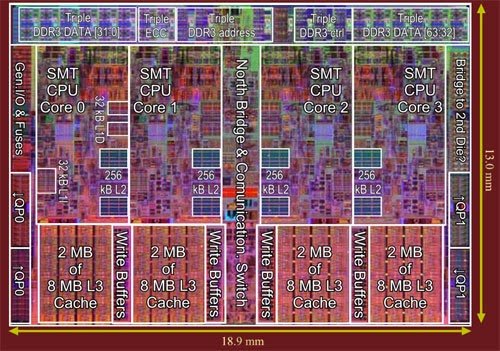
As you can see each of the individual cores has a dedicated L1 and L2 cache, but the L3 cache is a shared resource. If 2 threads are running on 2 separate cores and their working set fits cleanly within L1 or L2 and the memory used by each is independent, then the 2 threads can run in parallel without impeding each other. So the question remains that if the working set is larger and requires L3 how will that impact the performance of individual threads.
A Performance Test
To see if I could understand the impact I wrote a small performance test. The test works by holding two integer arrays. The first holds a set of random values, the second holds indexes into the first array. The code iterates over the array of indexes, reading values from the first array. The index array is shuffled resulting in a data access pattern that mixes sequential and random access. The test measures the how quickly all of the values from the data array are loaded via the index array.
The test runs with a varying number of threads (one to five) with a range of working set sizes, ranging from 16 bytes to 128 MB. The chart below shows the throughput for varying thread counts against the working set size.
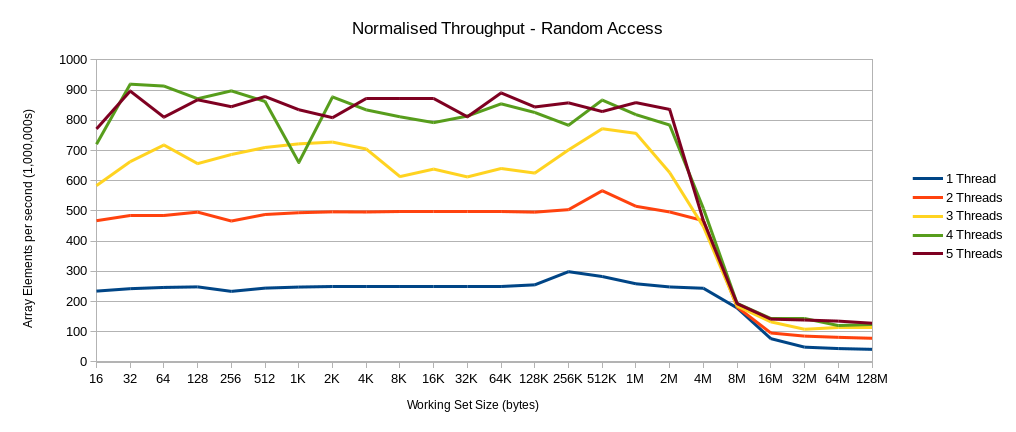
The throughput of each scenario proceeds in a relatively linear fashion until the size of the working set reaches the size of the L3, which happens to be 8MB on my test machine. After this point the performance degrades as most of the access stop hitting L3 and have to fetch data from main memory. What is interesting is the point around 8MB where the throughput of all the cases converge to roughly the same value. If instead of plotting the throughput we calculated the “speed up” that each of the scenarios had over the baseline single-threaded case, we would see the scalability*** of the code, by working set size.
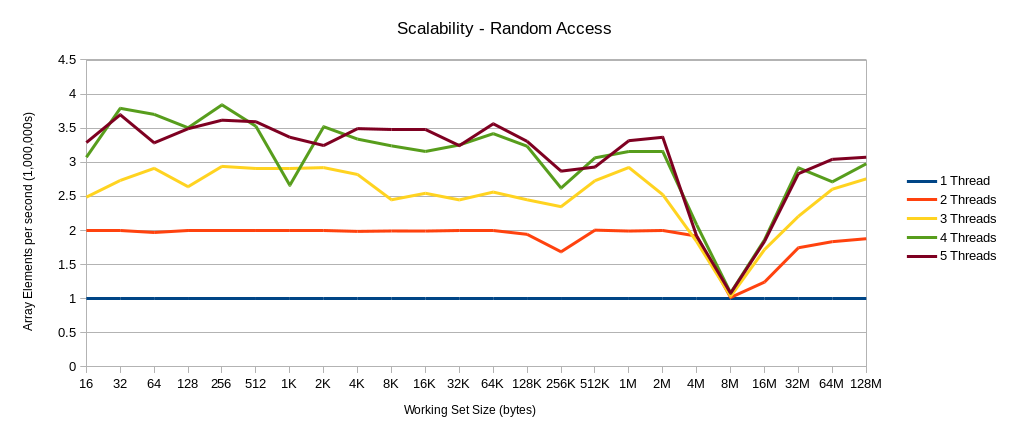
There is clearly a dramatic drop in the “speed up” or scalability when the working set for each thread matches the size of the L3. This is what I referred to as the “uncanny valley” in the title of the post. At this point the code is “perfectly contended” or, to quote the story of Mel,
“most pessimum”. This shows very clearly that multiple threads working on completely independent sets of data can contend with each other when running on different cores, but the same socket. To the point where the performance degrades such that it is equivalent of running the code on a single thread.
There are a couple things that can be taken from this:
- Beware believing the specific numbers from micro-benchmarks as there is a good chance that when running on a busy system that other threads on the same core could be reducing the overall performance of the code that was benchmarked.
- If writing parallel code, working set size is very important. In fork/join style applications the point where the code stops subdividing should take into account the size of the working set to avoid contending on the L3.
There is one further thing to consider. The test above is based on a mix of sequential and random access. If we change the tested so that the index array wasn’t shuffled, so that all memory accesses are sequential, does the “uncanny valley” still make an appearance?
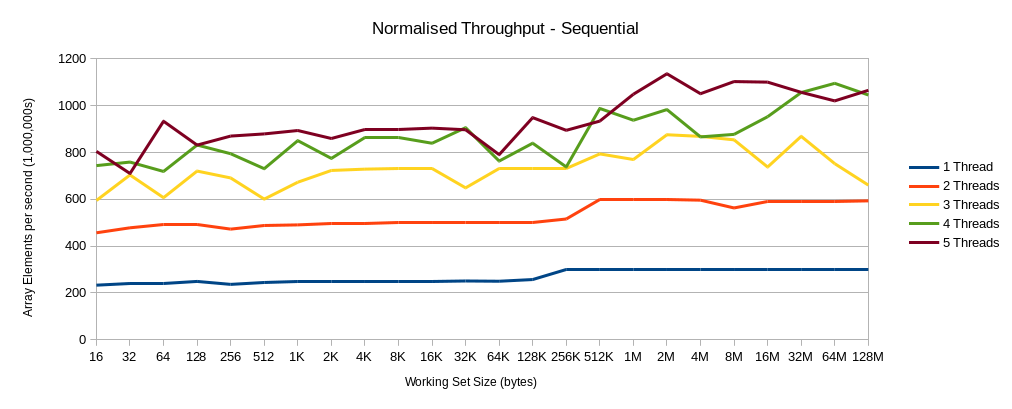
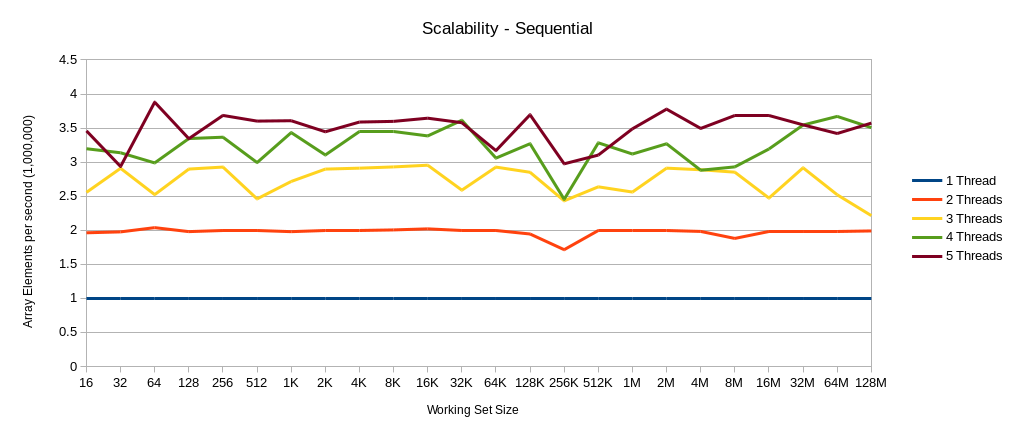
Looking at these charts, there is only a small movement in the “speed-up” at 8MB for the 2 Threads case. However, this could be explained by run-to-run variance, so is not conclusive. I think that if memory accesses are purely sequential then L3 cache contention is unlikely to have a significant affect on performance and scalability. So (surprise, surprise) algorithms that are completely (or mostly) sequential with regards to the way they access memory are going to suffer from fewer performance artefacts. However, there are many algorithms that are random access by their very nature, e.g. the mark phase of a garbage collection system. In those cases paying attention to working set size and what other threads in the system are doing will be important to ensure that the code runs well.
* Some of the latest Haswell CPUs have an L4 cache.
** Specifically higher latency.
*** Increase in throughput with additional threads.
| Reference: | The “Uncanny Valley” of L3 Cache Contention from our JCG partner Michael Barker at the Bad Concurrency blog. |
