Currently I am following the Coursera training ‘Mining Massive Datasets‘. I have been interested in MapReduce and Apache Hadoop for some time and with this course I hope to get more insight in when and how MapReduce can help to fix some real world business problems (another way to do so I described here). This Coursera course is mainly focussing on the theory of used algorithms and less about the coding itself. The first week is about PageRanking and how Google used this to rank pages. Luckily there is a lot to find about this topic in combination with Hadoop. I ended up here and decided to have a closer look at this code.
What I did was taking this code (forked it) and rewrote it a little. I created unit tests for the mappers and reducers as I described here. As a testcase I used the example from the course. We have three webpages linking to each other and/or themselves:
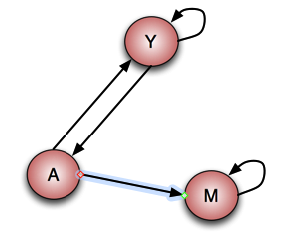
This linking scheme should resolve to the following page ranking:
- Y 7/33
- A 5/33
- M 21/33
Since the MapReduce example code is expecting ‘Wiki page’ XML as input I created the following test set:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | <mediawiki xmlns="http://www.mediawiki.org/xml/export-0.10/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mediawiki.org/xml/export-0.10/ http://www.mediawiki.org/xml/export-0.10.xsd" version="0.10" xml:lang="en"> <page> <title>A</title> <id>121173</id> <revision> ... <text xml:space="preserve" bytes="6523">[[Y]] [[M]]</text> </revision> </page> <page> <title>Y</title> <id>121173</id> <revision> ... <text xml:space="preserve" bytes="6523">[[A]] [[Y]]</text> </revision> </page> <page> <title>M</title> <id>121173</id> <revision> ... <text xml:space="preserve" bytes="6523">[[M]]</text> </revision> </page></mediawiki> |
The global way it works is already explained very nice at the original page itself. I will only describe the unit tests I created. With the original explanation and my unit tests you should be able to go through the matter and understand what happens.
As described the total job is divided in three parts:
- parsing
- calculating
- ordering
In the parsing part the raw XML is taken, split into pages and mapped so that we get as output the page as a key and a value of the pages it has outgoing links to. So the input for the unit test will be the three ‘Wiki’ pages XML as shown above. The expected out the ‘title’ of the pages with the linked pages. The unit test looks then like:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | package net.pascalalma.hadoop.job1;...public class WikiPageLinksMapperTest { MapDriver<LongWritable, Text, Text, Text> mapDriver; String testPageA = " <page>\n" + " <title>A</title>\n" + " ..." + " <text xml:space=\"preserve\" bytes=\"6523\">[[Y]] [[M]]</text>\n" + " </revision>"; String testPageY = " <page>\n" + " <title>Y</title>\n" + " ..." + " <text xml:space=\"preserve\" bytes=\"6523\">[[A]] [[Y]]</text>\n" + " </revision>\n" + " </page>"; String testPageM = " <page>\n" + " <title>M</title>\n" + " ..." + " <text xml:space=\"preserve\" bytes=\"6523\">[[M]]</text>\n" + " </revision>\n" + " </page>"; @Before public void setUp() { WikiPageLinksMapper mapper = new WikiPageLinksMapper(); mapDriver = MapDriver.newMapDriver(mapper); } @Test public void testMapper() throws IOException { mapDriver.withInput(new LongWritable(1), new Text(testPageA)); mapDriver.withInput(new LongWritable(2), new Text(testPageM)); mapDriver.withInput(new LongWritable(3), new Text(testPageY)); mapDriver.withOutput(new Text("A"), new Text("Y")); mapDriver.withOutput(new Text("A"), new Text("M")); mapDriver.withOutput(new Text("Y"), new Text("A")); mapDriver.withOutput(new Text("Y"), new Text("Y")); mapDriver.withOutput(new Text("M"), new Text("M")); mapDriver.runTest(false); }} |
The output of the mapper will be the input for our reducer. The unit test for that one looks like:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | package net.pascalalma.hadoop.job1;...public class WikiLinksReducerTest { ReduceDriver<Text, Text, Text, Text> reduceDriver; @Before public void setUp() { WikiLinksReducer reducer = new WikiLinksReducer(); reduceDriver = ReduceDriver.newReduceDriver(reducer); } @Test public void testReducer() throws IOException { List<Text> valuesA = new ArrayList<Text>(); valuesA.add(new Text("M")); valuesA.add(new Text("Y")); reduceDriver.withInput(new Text("A"), valuesA); reduceDriver.withOutput(new Text("A"), new Text("1.0\tM,Y")); reduceDriver.runTest(); }} |
As the unit test shows we expect the reducer to reduce the input to the value of an ‘initial’ page rank of 1.0 concatenated with all pages the (key) page has outgoing links to. That is the output of this phase and will be used as input for the ‘calculate’ phase.
In the calculate part a recalculation of the incoming page ranks will be performed to implement the ‘power iteration‘ method. This step will be performed multiple times to obtain an acceptable page rank for the given page set. As said before the output of the previous part is the input of this step as we see in the unit test for this mapper:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | package net.pascalalma.hadoop.job2;...public class RankCalculateMapperTest { MapDriver<LongWritable, Text, Text, Text> mapDriver; @Before public void setUp() { RankCalculateMapper mapper = new RankCalculateMapper(); mapDriver = MapDriver.newMapDriver(mapper); } @Test public void testMapper() throws IOException { mapDriver.withInput(new LongWritable(1), new Text("A\t1.0\tM,Y")); mapDriver.withInput(new LongWritable(2), new Text("M\t1.0\tM")); mapDriver.withInput(new LongWritable(3), new Text("Y\t1.0\tY,A")); mapDriver.withOutput(new Text("M"), new Text("A\t1.0\t2")); mapDriver.withOutput(new Text("A"), new Text("Y\t1.0\t2")); mapDriver.withOutput(new Text("Y"), new Text("A\t1.0\t2")); mapDriver.withOutput(new Text("A"), new Text("|M,Y")); mapDriver.withOutput(new Text("M"), new Text("M\t1.0\t1")); mapDriver.withOutput(new Text("Y"), new Text("Y\t1.0\t2")); mapDriver.withOutput(new Text("A"), new Text("!")); mapDriver.withOutput(new Text("M"), new Text("|M")); mapDriver.withOutput(new Text("M"), new Text("!")); mapDriver.withOutput(new Text("Y"), new Text("|Y,A")); mapDriver.withOutput(new Text("Y"), new Text("!")); mapDriver.runTest(false); }} |
The output here is explained in the source page. The ‘extra’ items with ‘!’ and ‘|’ are necessary in the reduce step for the calculations. The unit test for the reducer looks like:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | package net.pascalalma.hadoop.job2;...public class RankCalculateReduceTest { ReduceDriver<Text, Text, Text, Text> reduceDriver; @Before public void setUp() { RankCalculateReduce reducer = new RankCalculateReduce(); reduceDriver = ReduceDriver.newReduceDriver(reducer); } @Test public void testReducer() throws IOException { List<Text> valuesM = new ArrayList<Text>(); valuesM.add(new Text("A\t1.0\t2")); valuesM.add(new Text("M\t1.0\t1")); valuesM.add(new Text("|M")); valuesM.add(new Text("!")); reduceDriver.withInput(new Text("M"), valuesM); List<Text> valuesA = new ArrayList<Text>(); valuesA.add(new Text("Y\t1.0\t2")); valuesA.add(new Text("|M,Y")); valuesA.add(new Text("!")); reduceDriver.withInput(new Text("A"), valuesA); List<Text> valuesY = new ArrayList<Text>(); valuesY.add(new Text("Y\t1.0\t2")); valuesY.add(new Text("|Y,A")); valuesY.add(new Text("!")); valuesY.add(new Text("A\t1.0\t2")); reduceDriver.withInput(new Text("Y"), valuesY); reduceDriver.withOutput(new Text("A"), new Text("0.6\tM,Y")); reduceDriver.withOutput(new Text("M"), new Text("1.4000001\tM")); reduceDriver.withOutput(new Text("Y"), new Text("1.0\tY,A")); reduceDriver.runTest(false); }} |
As is shown the output from the mapper is recreated as input and we check that the output of the reducer matches the first iteration of the page rank calculation. Each iteration will lead to the same output format but with possible different page rank values.
Final step is the ‘ordering’ part. This is quite straightforward and so is the unit test. This part only contains a mapper which takes the output of the previous step and ‘reformats’ it to the wanted format: pagerank + page order by pagerank. The sorting by key is done by Hadoop framework when the mapper result is supplied to the reducer step so this ordering isn’t reflected in the Mapper unit test. The code for this unit test is:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | package net.pascalalma.hadoop.job3;...public class RankingMapperTest { MapDriver<LongWritable, Text, FloatWritable, Text> mapDriver; @Before public void setUp() { RankingMapper mapper = new RankingMapper(); mapDriver = MapDriver.newMapDriver(mapper); } @Test public void testMapper() throws IOException { mapDriver.withInput(new LongWritable(1), new Text("A\t0.454545\tM,Y")); mapDriver.withInput(new LongWritable(2), new Text("M\t1.90\tM")); mapDriver.withInput(new LongWritable(3), new Text("Y\t0.68898\tY,A")); //Please note that we cannot check for ordering here because that is done by Hadoop after the Map phase mapDriver.withOutput(new FloatWritable(0.454545f), new Text("A")); mapDriver.withOutput(new FloatWritable(1.9f), new Text("M")); mapDriver.withOutput(new FloatWritable(0.68898f), new Text("Y")); mapDriver.runTest(false); }} |
So here we just check that the mapper takes the input and formats the output correctly.
This concludes all the examples of the unit tests. With this project you should be able to test it yourself and get bigger insight in how the original code works. It sure helped me to understand it!
- The complete version of the code including unit tests can be found here.
| Reference: | Calculate PageRanks with Apache Hadoop from our JCG partner Pascal Alma at the The Pragmatic Integrator blog. |
