 In a previous post I described an example to perform a PageRank calculation which is part of the Mining Massive Dataset course with Apache Hadoop. In that post I took an existing Hadoop job in Java and modified it somewhat (added unit tests and made file paths set by a parameter). This post shows how to use this job on a real-life Hadoop cluster. The cluster is a AWS EMR cluster of 1 Master Node and 5 Core Nodes, each being backed by a m3.xlarge instance.
In a previous post I described an example to perform a PageRank calculation which is part of the Mining Massive Dataset course with Apache Hadoop. In that post I took an existing Hadoop job in Java and modified it somewhat (added unit tests and made file paths set by a parameter). This post shows how to use this job on a real-life Hadoop cluster. The cluster is a AWS EMR cluster of 1 Master Node and 5 Core Nodes, each being backed by a m3.xlarge instance.
The first step is to prepare the input for the cluster. I make use of AWS S3 since this is a convenient way when working with EMR. I create a new bucket, ‘emr-pagerank-demo’, and made the following subfolders:
- in: the folder containing the input files for the job
- job: the folder containing my executable Hadoop jar file
- log: the folder where EMR will put its log files
In the ‘in’ folder I then copied the data that I want to be ranked. I used this file as input. Unzipped it became a 5 GB file with XML content, although not really massive, it is sufficient for this demo. When you take the sources of the previous post and run ‘mvn clean install’ you will get the jar file: ‘hadoop-wiki-pageranking-0.2-SNAPSHOT.jar’. I uploaded this jar file to the ‘job’ folder.
That is it for the preparation. Now we can fire up the cluster. For this demo I used the AWS Management Console:
- Name the cluster
- Enter the log folder as log location
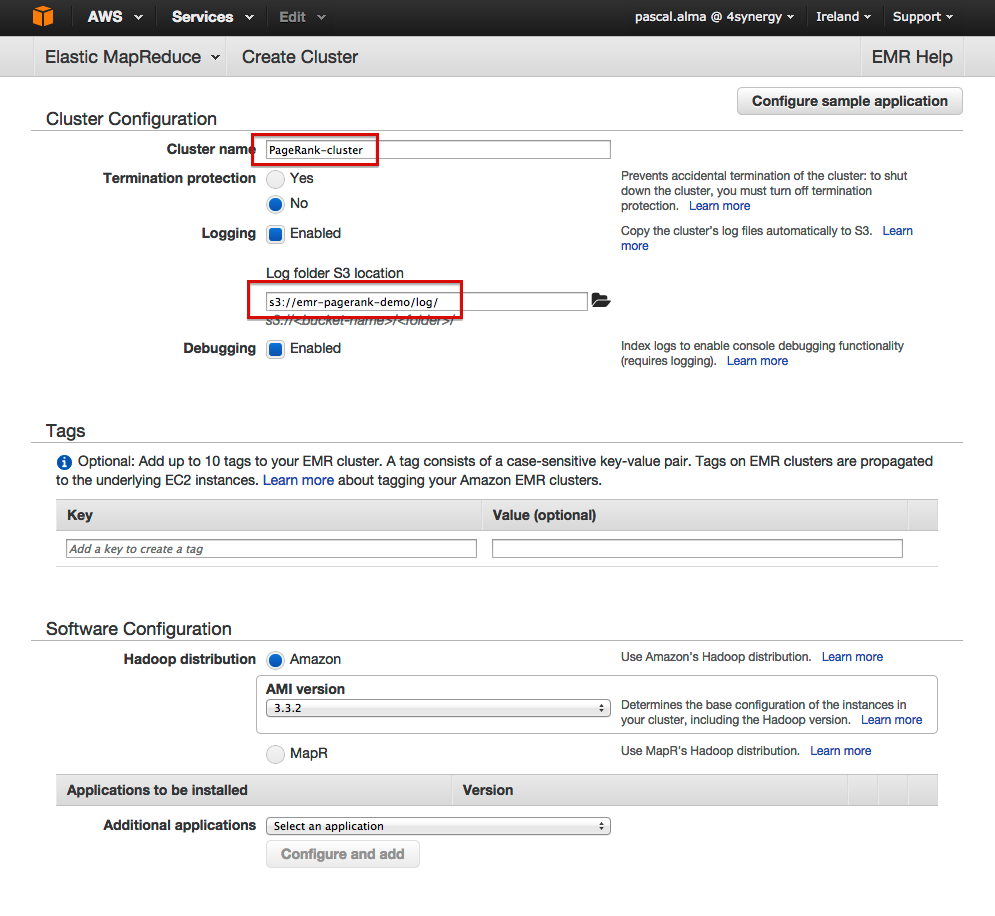
- Enter the number of Core instances
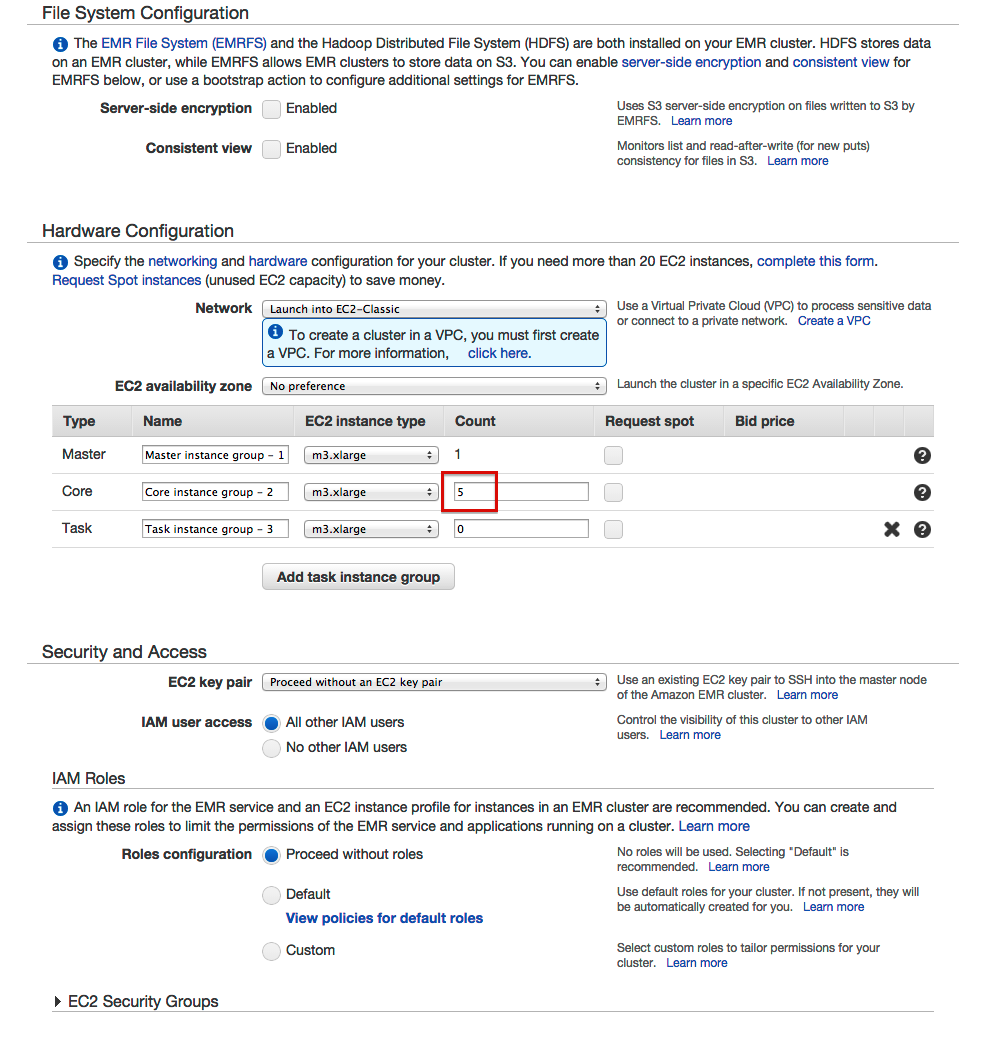
- Add a step for our custom jar
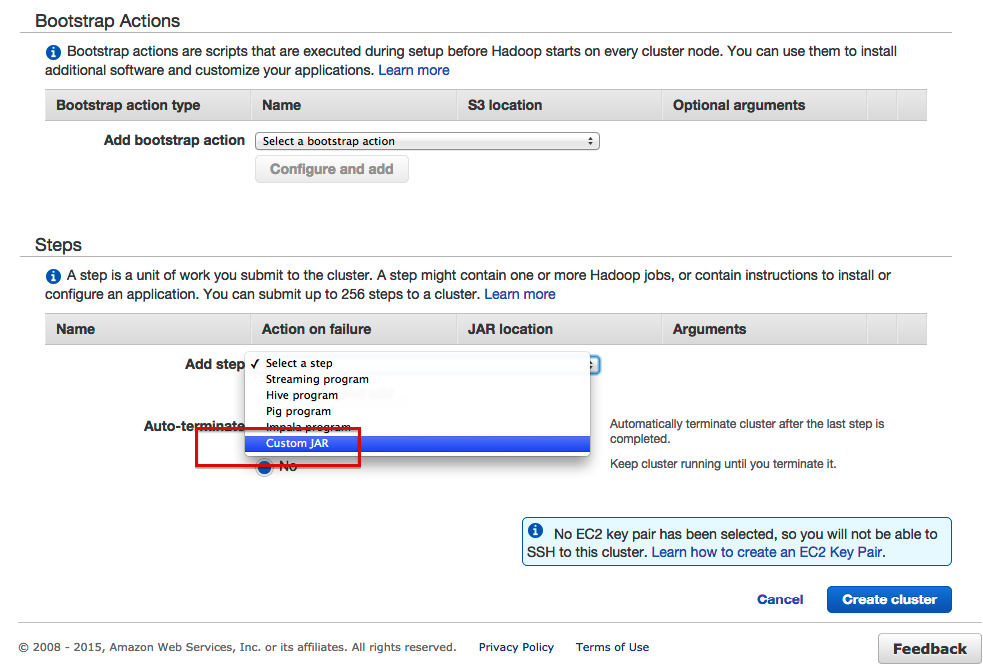
- Configure the step like this:
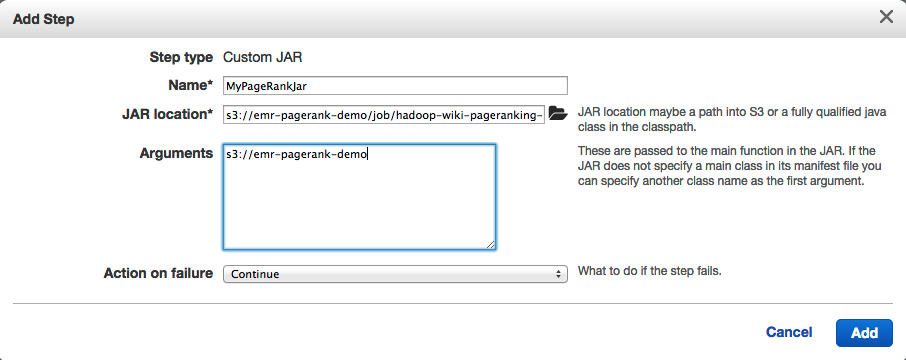
- This should result in the following overview:
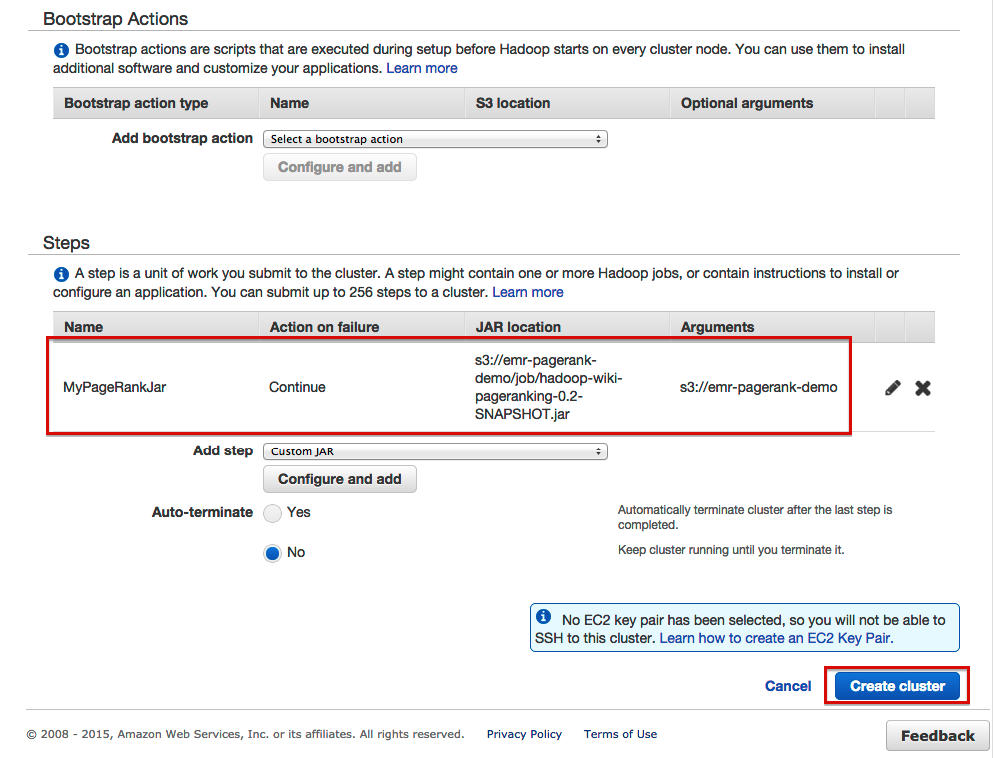
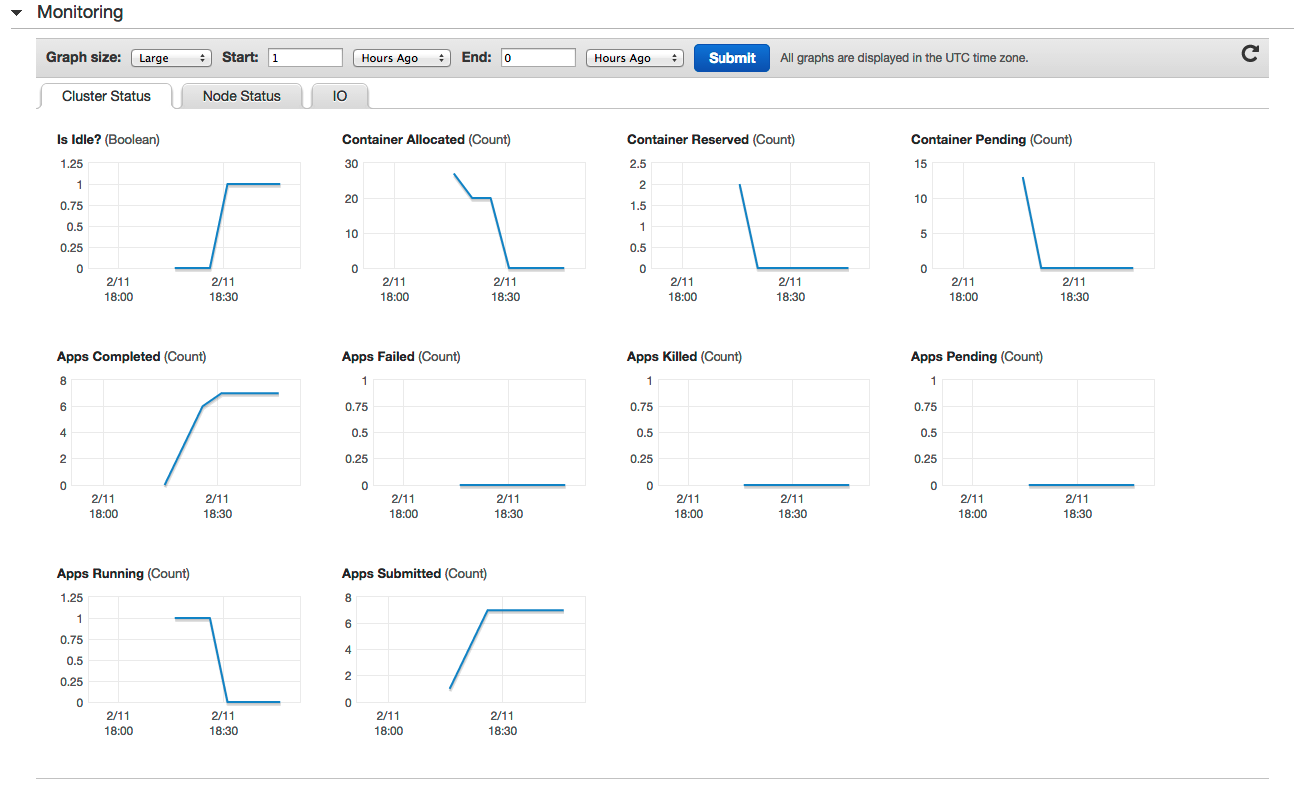
If this is correct you can press the ‘Create Cluster’ button and have EMR doing its work. You can monitor the cluster in the ‘Monitoring’ part of the console:
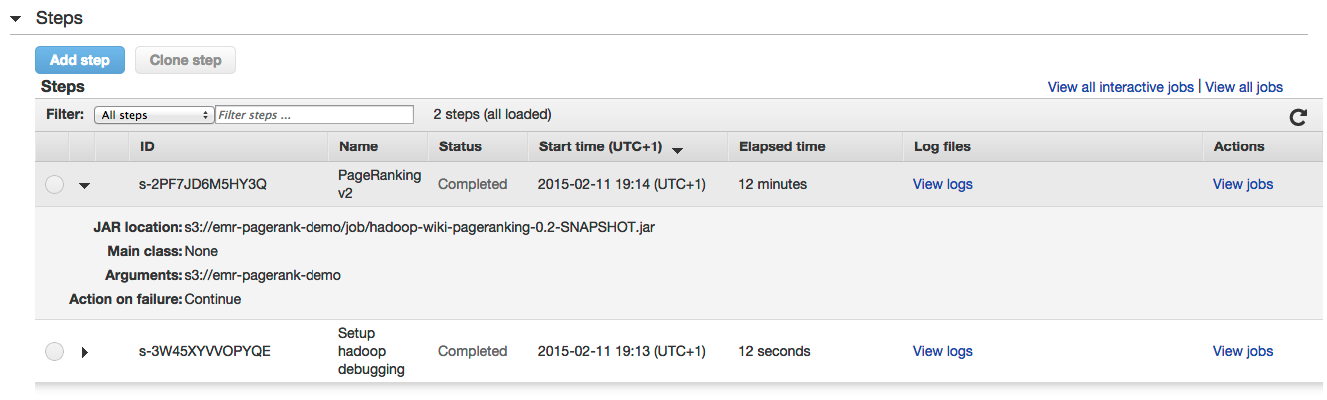
And monitor the status of the steps in the ‘Steps’ part:
After a few minutes the job will be finished (depending on the size of the input files and used cluster of course). In our S3 bucket we can see log files are created in the ‘log’ folder:
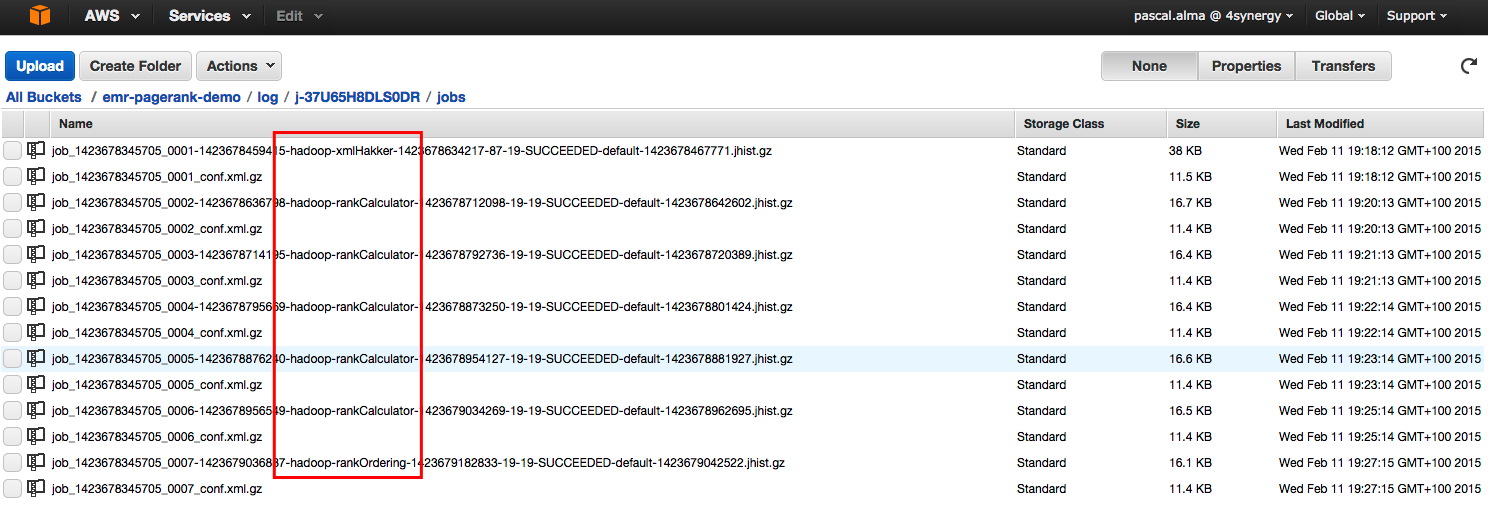
Here we see a total of 7 jobs: 1 x the Xml preparation step, 5 x the rankCalculator step and 1 x the rankOrdering step.
And more important we can see the results in the ‘Result’ folder:
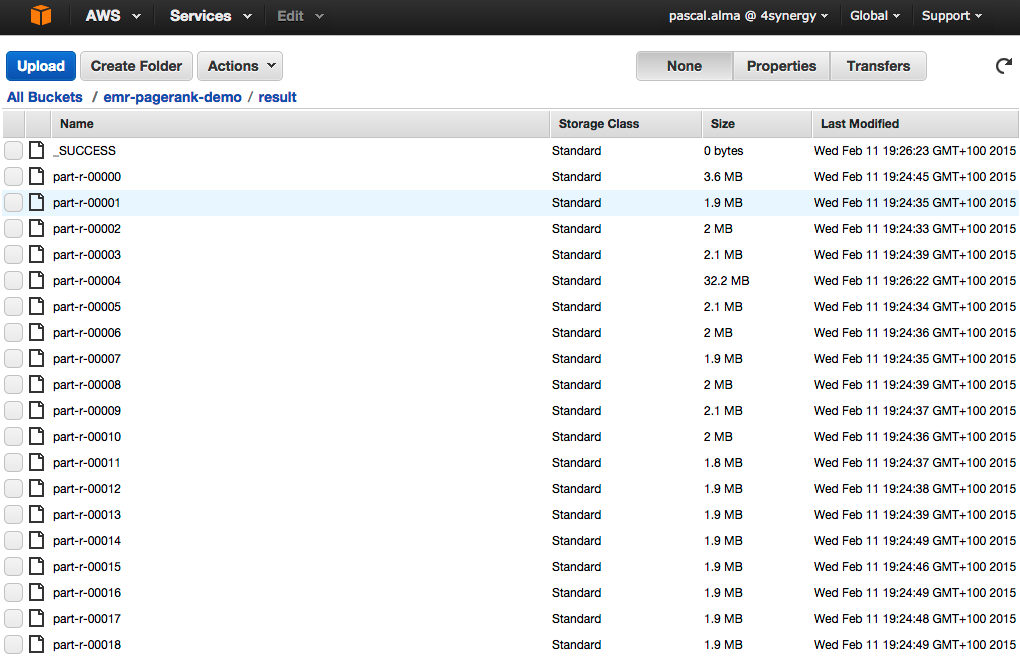
Each reducer creates its own result file so we have multiple files here. We are interested in the one with the highest number since there are the pages with the highest ranks. If we look into this file we see the following result as top-10 ranking:
01 02 03 04 05 06 07 08 09 10 | 271.6686 Spaans274.22974 Romeinse_Rijk276.7207 1973285.39502 Rondwormen291.83002 Decapoda319.89224 Brussel_(stad)390.02606 2012392.08563 Springspinnen652.5087 20072241.2773 Boktorren |
Please note that the current implementation only runs the calculation 5 times (hard coded), so not really the power iteration as described in the theory of MMDS (nice modification for a next release of the software :-)).
Also note that the cluster is not terminated after the job is finished when the default settings are used, so costs for the cluster increase until the cluster is terminated manually.
| Reference: | Running PageRank Hadoop job on AWS Elastic MapReduce from our JCG partner Pascal Alma at the The Pragmatic Integrator blog. |
