My last post was written a couple of weeks ago and after some valid feedback I’d like to clarify a couple of points as a preface to this article.
The main takeaway from ‘Creating millions of objects with Zero Garbage‘ should be that with Chronicle you are not ‘limited’ to using jvm allocated on-heap memory when writing a Java program. Maybe the article would have been more aptly titled ‘Creating Millions of Objects using Zero Heap’. Another point I wanted to bring out was that when you have no heap memory you cause no GC activity.
A source of confusion came from the fact I used the term ‘garbage’ to describe the objects allocated on the heap. The objects allocated were actually not garbage though they caused GC activity.
I contrived an example to demonstrate, one, that ChronicleMap does not use heap memory whilst ConcurrentHashMap does, and two, that when you use heap memory you can’t ignore the GC. At the very least you need to tune your system carefully to ensure that you don’t end up suffering from long GC pauses. This does not mean that there are no issues with allocating from off heap (see the end of this post) and it also does not mean that you can’t tune your way through an on heap solution to eliminate GC. Going off heap is by no means a panacea to all Java performance issues but for very specific solutions it can deliver interesting opportunities some of which I will discuss in this post.
There may be occasions where you might need to share data between JVMs.
Let’s simplify for now and say that you have two JVMs running on the same machine, either or both of which would like to see updates from the other. Each Java program has a ConcurrentHashMap which it updates, those updates are stored and are available to it later. But how does the program get the updates applied by the other Java program to its map?
Fundamentally, JDK on-heap collections such as HashMap and ConcurrentHashMap can’t be shared directly between JVMs. This is because heap memory is contained by the JVM through which it was allocated. Therefore when the JVM exits the memory is released and the data is no longer available, there is no implicit way of persisting the memory outside the lifetime of the JVM. So you need to find some other mechanism to share the data between the JVMs. Typically you might use a database as an external sharable store and messaging service to send the data updates to other processes to notify them that some data has been updated.
This results in the following architecture:
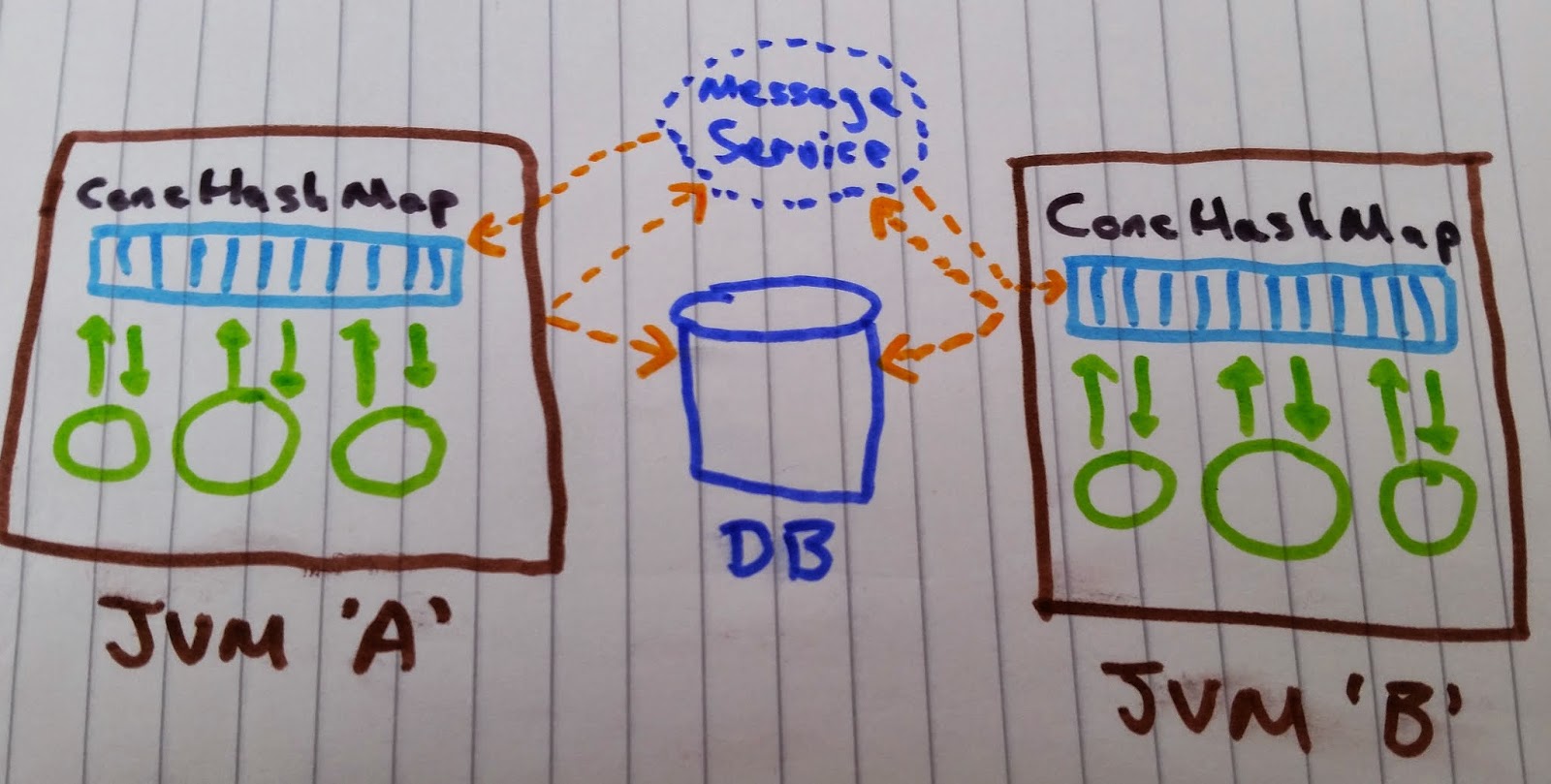
The problem with this architecture is that use lose the in-memory speeds of a HashMap, especially if writing to your database is not that fast and you want the write to be persisted before you send the message out over the messaging service. Also many solutions will involve TCP calls which can again be a source of latency.
There are of course much faster ways to persist data than writing to a fully fledged database using mechanisms like journaling to disk, for example using a product like ChronicleQueue or similar. But if you did use a journal you’d still have to build all the logic to recreate a Map data structure on restart not to mention having to keep a Map type structure up-to-date on another JVM.
(The reason you might want to persist the data at all is so that you should be able to recover in the event of a restart without having to replay all the data from source). In addition to the latency introduced by this architecture there is the complication of having to deal with the extra code and configuration for the database and messaging service.
Even accepting that this sort of functionality can be wrapped up in frameworks, wouldn’t it be great if your in memory Map was actually visible outside your JVM. The Map should be able to implicitly persist the data so that its data is available independently of the life time of the JVM. It should allow access with the same ‘memory’ speeds as you might achieve using an on heap Map.
This is where ChronicleMap comes in. ChronicleMap is an implementation of java.util.ConcurrentMap but critically it uses off heap memory which is visible outside the JVM to any other process running on the machine. (For a discussion about on-heap vs off-heap memory see here).
Each JVM will create a ChronicleMap pointing at the same memory mapped files. When one process writes into its ChronicleMap the other process can instantly (~40 nanoseconds) see the update in its ChronicleMap. Since the data is stored in memory outside the JVM, a JVM exit will not cause any data to be lost. The data will be held in memory (assuming there was no need for it to be paged out) and when the JVM restarts it can map it back in extremely quickly. The only way data can be lost is if the OS crashes whilst it has dirty pages that haven’t been persisted to disk. The solution to this is use replication which Chronicle supports but is beyond the scope of this post.
The architecture for this is simply this:
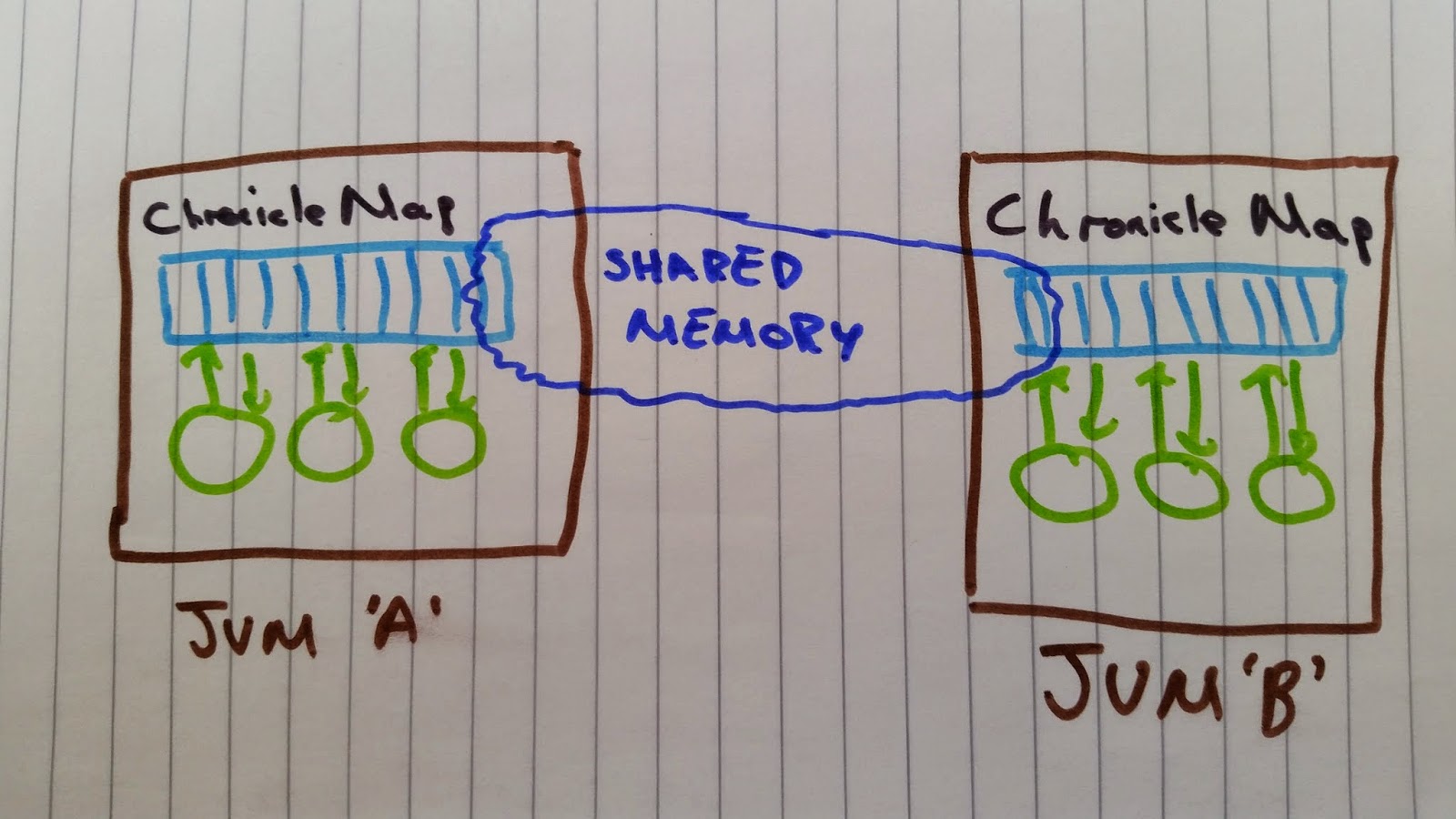
For a code example to get started with ChronicleMap see my last post or see the official ChronicleMap tutorial here.
There are a number of caveats and trade-offs to consider before diving into ChronicleMap.
- The ChronicleMap entries have to be Serializable. For systems that are very sensitive to performance you will need to implement the custom serialisation provided by Chronicle known as BytesMarshallable. Whilst this is pretty easy to implement it is not something that is necessary with an on-heap map. (Having said that storing data into a database will of course also require some method of serialisation.)
- Even with BytesMarshallable serialisation, the overhead of any serialisation might be significant to some systems. In such a scenario it is possible to employ a zero copy technique supported by Chronicle (see my last blog post for more details) to minimise the costs of serialisation. It is however a little trickier to implement than using ‘normal’ Java. On the other hand in latency sensitive programs it will have the huge benefit of not creating any objects that might then later need to be cleaned up by the GC.
- A ChronicleMap does not resize and must therefore be sized up front. This might be an issue if you have no idea how many items to expect. It should be noted however, that oversizing, at least on Linux, is not a huge problem as Linux passively allocates memory.
- Chronicle relies on the OS to asynchronously flush to disk. If you want to be absolutely sure that data has actually been written to disk (as opposed to just being held in memory) you will need to replicate to another machine. In truth any mission critical system should be replicating to another machine so this might not be a big issue in adopting Chronicle.
- ChronicleMap will be subject to OS memory paging issues. If memory is paged out and has to be swapped back in latency will be introduced into the system. Therefore even though you will be able to create ChronicleMaps with sizes well in excess of main memory, you will have to be aware that paging might occur depending on your access patterns on the data.
| Reference: | ChronicleMap – Java Architecture with Off Heap Memory from our JCG partner Daniel Shaya at the Rational Java blog. |
