Introduction
In my previous post, I introduced the READ_ONLY CacheConcurrencyStrategy, which is the obvious choice for immutable entity graphs. When cached data is changeable, we need to use a read-write caching strategy and this post will describe how NONSTRICT_READ_WRITE second-level cache works.
Inner workings
When the Hibernate transaction is committed, the following sequence of operations is executed:
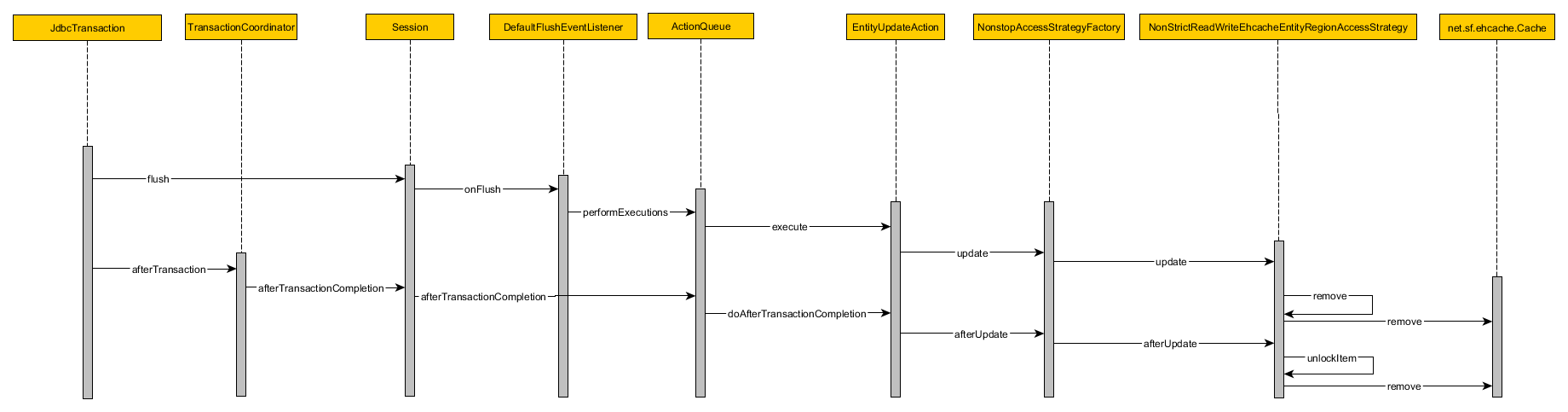
First, the cache is invalidated before the database transaction gets committed, during flush time:
- The current Hibernate Transaction (e.g. JdbcTransaction, JtaTransaction) is flushed
- The DefaultFlushEventListener executes the current ActionQueue
- The EntityUpdateAction calls the update method of the EntityRegionAccessStrategy
- The NonStrictReadWriteEhcacheCollectionRegionAccessStrategy removes the cache entry from the underlying EhcacheEntityRegion
After the database transaction is committed, the cache entry is removed once more:
- The current Hibernate Transaction after completion callback is called
- The current Session propagates this event to its internal ActionQueue
- The EntityUpdateAction calls the afterUpdate method on the EntityRegionAccessStrategy
- The NonStrictReadWriteEhcacheCollectionRegionAccessStrategy calls the remove method on the underlying EhcacheEntityRegion
Inconsistency warning
The NONSTRICT_READ_WRITE mode is not a write-though caching strategy because cache entries are invalidated, instead of being updated. Tthe cache invalidation is not synchronized with the current database transaction. Even if the associated Cache region entry gets invalidated twice (before and after transaction completion), there’s still a tiny time window when the cache and the database might drift apart.
The following test will demonstrate this issue. First we are going to define Alice transaction logic:
doInTransaction(session -> {
LOGGER.info("Load and modify Repository");
Repository repository = (Repository)
session.get(Repository.class, 1L);
assertTrue(getSessionFactory().getCache()
.containsEntity(Repository.class, 1L));
repository.setName("High-Performance Hibernate");
applyInterceptor.set(true);
});
endLatch.await();
assertFalse(getSessionFactory().getCache()
.containsEntity(Repository.class, 1L));
doInTransaction(session -> {
applyInterceptor.set(false);
Repository repository = (Repository)
session.get(Repository.class, 1L);
LOGGER.info("Cached Repository {}", repository);
});Alice loads a Repository entity and modifies it in her first database transaction.
To spawn another concurrent transaction right when Alice prepares to commit, we are going to use the following Hibernate Interceptor:
private AtomicBoolean applyInterceptor =
new AtomicBoolean();
private final CountDownLatch endLatch =
new CountDownLatch(1);
private class BobTransaction extends EmptyInterceptor {
@Override
public void beforeTransactionCompletion(Transaction tx) {
if(applyInterceptor.get()) {
LOGGER.info("Fetch Repository");
assertFalse(getSessionFactory().getCache()
.containsEntity(Repository.class, 1L));
executeSync(() -> {
Session _session = getSessionFactory()
.openSession();
Repository repository = (Repository)
_session.get(Repository.class, 1L);
LOGGER.info("Cached Repository {}",
repository);
_session.close();
endLatch.countDown();
});
assertTrue(getSessionFactory().getCache()
.containsEntity(Repository.class, 1L));
}
}
}Running this code generates the following output:
[Alice]: Load and modify Repository
[Alice]: select nonstrictr0_.id as id1_0_0_, nonstrictr0_.name as name2_0_0_ from repository nonstrictr0_ where nonstrictr0_.id=1
[Alice]: update repository set name='High-Performance Hibernate' where id=1
[Alice]: Fetch Repository from another transaction
[Bob]: select nonstrictr0_.id as id1_0_0_, nonstrictr0_.name as name2_0_0_ from repository nonstrictr0_ where nonstrictr0_.id=1
[Bob]: Cached Repository from Bob's transaction Repository{id=1, name='Hibernate-Master-Class'}
[Alice]: committed JDBC Connection
[Alice]: select nonstrictr0_.id as id1_0_0_, nonstrictr0_.name as name2_0_0_ from repository nonstrictr0_ where nonstrictr0_.id=1
[Alice]: Cached Repository Repository{id=1, name='High-Performance Hibernate'}- Alice fetches a Repository and updates its name
- The custom Hibernate Interceptor is invoked and Bob’s transaction is started
- Because the Repository was evicted from the Cache, Bob will load the 2nd level cache with the current database snapshot
- Alice transaction commits, but now the Cache contains the previous database snapshot that Bob’s just loaded
- If a third user will now fetch the Repository entity, he will also see a stale entity version which is different from the current database snapshot
- After Alice transaction is committed, the Cache entry is evicted again and any subsequent entity load request will populate the Cache with the current database snapshot
Stale data vs lost updates
The NONSTRICT_READ_WRITE concurrency strategy introduces a tiny window of inconsistency when the database and the second-level cache can go out of sync. While this might sound terrible, in reality we should always design our applications to cope with these situations even if we don’t use a second-level cache. Hibernate offers application-level repeatable reads through its transactional write-behind first-level cache and all managed entities are subject to becoming stale. Right after an entity is loaded into the current Persistence Context, another concurrent transaction might update it and so, we need to prevent stale data from escalating to losing updates.
Optimistic concurrency control is an effective way of dealing with lost updates in long conversations and this technique can mitigate the NONSTRICT_READ_WRITE inconsistency issue as well.
Conclusion
The NONSTRICT_READ_WRITE concurrency strategy is a good choice for read-mostly applications (if backed-up by the optimistic locking mechanism). For write-intensive scenarios, the cache invalidation mechanism would increase the cache miss rate, therefore rendering this technique inefficient.
- Code available on GitHub.
| Reference: | How does Hibernate NONSTRICT_READ_WRITE CacheConcurrencyStrategy work from our JCG partner Vlad Mihalcea at the Vlad Mihalcea’s Blog blog. |
