Introduction
Hibernate supports three data mapping types: basic (e.g String, int), Embeddable and Entity. Most often, a database row is mapped to an Entity, each database column being associated to a basic attribute. Embeddable types are more common when combining several field mappings into a reusable group (the Embeddable being merged into the owning Entity mapping structure).
Both basic types and Embeddables can be associated to an Entity through the @ElementCollection, in a one-Entity-many-non-Entity relationship.
Testing time
For the upcoming test cases we are going to use the following entity model:
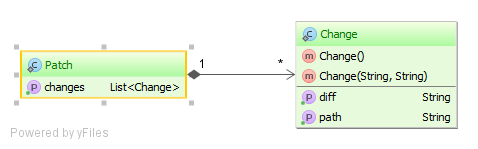
A Patch has a collection of Change Embeddable objects.
@ElementCollection
@CollectionTable(
name="patch_change",
joinColumns=@JoinColumn(name="patch_id")
)
private List<Change> changes = new ArrayList<>();The Change object is modeled as an Embeddable type and it can only be accessed through its owner Entity. The Embeddable has no identifier and it cannot be queried through JPQL. The Embeddable life-cycle is bound to that of its owner, so any Entity state transition is automatically propagated to the Embeddable collection.
First, we need to add some test data:
doInTransaction(session -> {
Patch patch = new Patch();
patch.getChanges().add(
new Change("README.txt", "0a1,5...")
);
patch.getChanges().add(
new Change("web.xml", "17c17...")
);
session.persist(patch);
});Adding a new element
Let’s see what happens when we add a new Change to an existing Patch:
doInTransaction(session -> {
Patch patch = (Patch) session.get(Patch.class, 1L);
patch.getChanges().add(
new Change("web.xml", "1d17...")
);
});This test generate the following SQL output:
DELETE FROM patch_change WHERE patch_id = 1 INSERT INTO patch_change (patch_id, diff, path) VALUES (1, '0a1,5...', 'README.txt') INSERT INTO patch_change(patch_id, diff, path) VALUES (1, '17c17...', 'web.xml') INSERT INTO patch_change(patch_id, diff, path) VALUES (1, '1d17...', 'web.xml')
By default, any collection operation ends up recreating the whole data set. This behavior is only acceptable for an in-memory collection and it’s not suitable from a database perspective. The database has to delete all existing rows, only to re-add them afterwords. The more indexes we have on this table, the greater the performance penalty.
Removing an element
Removing an element is no different:
doInTransaction(session -> {
Patch patch = (Patch) session.get(Patch.class, 1L);
patch.getChanges().remove(0);
});This test case generates these SQL statements:
DELETE FROM patch_change WHERE patch_id = 1 INSERT INTO patch_change(patch_id, diff, path) VALUES (1, '17c17...', 'web.xml')
All table rows were removed and the remaining in-memory entries have been flushed to the database.
The Java Persistence Wiki Book clearly documents this behavior:
The JPA 2.0 specification does not provide a way to define the Id in the Embeddable. However, to delete or update a element of the ElementCollection mapping, some unique key is normally required. Otherwise, on every update the JPA provider would need to delete everything from the CollectionTable for the Entity, and then insert the values back. So, the JPA provider will most likely assume that the combination of all of the fields in the Embeddable are unique, in combination with the foreign key (JoinColumn(s)). This however could be inefficient, or just not feasible if the Embeddable is big, or complex.
Some JPA providers may allow the Id to be specified in the Embeddable, to resolve this issue. Note in this case the Id only needs to be unique for the collection, not the table, as the foreign key is included. Some may also allow the unique option on the CollectionTable to be used for this. Otherwise, if your Embeddable is complex, you may consider making it an Entity and use a OneToMany instead.
Adding an OrderColumn
To optimize the ElementCollection behavior we need apply the same techniques that work for one-to-many associations. The collection of elements is like a unidirectional one-to-many relationship, and we already know that an idbag performs better than a unidirectional bag.
Because an Embeddable cannot contain an identifier, we can at least add an order column so that each row can be uniquely identified. Let’s see what happens when we add an @OrderColumn to our element collection:
@ElementCollection
@CollectionTable(
name="patch_change",
joinColumns=@JoinColumn(name="patch_id")
)
@OrderColumn(name = "index_id")
private List<Change> changes = new ArrayList<>();Removing an entity sees no improvement from the previous test results:
DELETE FROM patch_change WHERE patch_id = 1 INSERT INTO patch_change(patch_id, diff, path) VALUES (1, '17c17...', 'web.xml')
This is because the AbstractPersistentCollection checks for nullable columns, when preventing the collection from being recreated:
@Override
public boolean needsRecreate(CollectionPersister persister) {
if (persister.getElementType() instanceof ComponentType) {
ComponentType componentType =
(ComponentType) persister.getElementType();
return !componentType.hasNotNullProperty();
}
return false;
}We’ll now add the NOT NULL constraints and rerun our tests:
@Column(name = "path", nullable = false) private String path; @Column(name = "diff", nullable = false) private String diff;
Adding a new ordered element
Adding an element to the end of the list generates the following statement:
INSERT INTO patch_change(patch_id, index_id, diff, path) VALUES (1, 2, '1d17...', 'web.xml')
The index_id column is used to persist the in-memory collection order. Adding to the end of the collection doesn’t affect the existing elements order, hence only one INSERT statement is required.
Adding a new first element
If we add a new element at the beginning of the list:
doInTransaction(session -> {
Patch patch = (Patch) session.get(Patch.class, 1L);
patch.getChanges().add(0,
new Change("web.xml", "1d17...")
);
});Generates the following SQL output:
UPDATE patch_change
SET diff = '1d17...',
path = 'web.xml'
WHERE patch_id = 1
AND index_id = 0
UPDATE patch_change
SET diff = '0a1,5...',
path = 'README.txt'
WHERE patch_id = 1
AND index_id = 1
INSERT INTO patch_change (patch_id, index_id, diff, path)
VALUES (1, 2, '17c17...', 'web.xml')The existing database entries are updated to reflect the new in-memory data structure. Because the newly added element is added at the beginning of the list, it will trigger an update to the first table row. All INSERT statements are issued at the end of the list and all existing elements are updated according to the new list order.
This behavior is explained in the the @OrderColumn Java Persistence documentation:
The persistence provider maintains a contiguous (non-sparse) ordering of the values of the order column when updating the association or element collection. The order column value for the first element is 0.
Removing an ordered element
If we delete the last entry:
doInTransaction(session -> {
Patch patch = (Patch) session.get(Patch.class, 1L);
patch.getChanges().remove(patch.getChanges().size() - 1);
});There’s only one DELETE statement being issued:
DELETE FROM patch_change
WHERE patch_id = 1
AND index_id = 1Deleting the first element entry
If we delete the first element the following statements are executed:
DELETE FROM patch_change
WHERE patch_id = 1
AND index_id = 1
UPDATE patch_change
SET diff = '17c17...',
path = 'web.xml'
WHERE patch_id = 1
AND index_id = 0Hibernate deletes all extra rows and then it updates the remaining ones.
Deleting from the middle
If we delete an element from the middle of the list:
doInTransaction(session -> {
Patch patch = (Patch) session.get(Patch.class, 1L);
patch.getChanges().add(new Change("web.xml", "1d17..."));
patch.getChanges().add(new Change("server.xml", "3a5..."));
});
doInTransaction(session -> {
Patch patch = (Patch) session.get(Patch.class, 1L);
patch.getChanges().remove(1);
});The following statements are executed:
DELETE FROM patch_change
WHERE patch_id = 1
AND index_id = 3
UPDATE patch_change
SET diff = '1d17...',
path = 'web.xml'
WHERE patch_id = 1
AND index_id = 1
UPDATE patch_change
SET diff = '3a5...',
path = 'server.xml'
WHERE patch_id = 1
AND index_id = 2An ordered ElementCollection is updated like this:
- The database table size is adjusted, the DELETE statements removing the extra rows located at the end of the table. If the in-memory collection is larger than its database counterpart then all INSERT statements will be executed at the end of the list
- All elements situated before the adding/removing entry are left untouched
- The remaining elements located after the adding/removing one are updated to match the new in-memory collection state
Conclusion
Compared to an inverse one-to-many association, the ElementCollection is more difficult to optimize. If the collection is frequently updated then a collection of elements is better substituted by a one-to-many association. Element collections are more suitable for data that seldom changes, when we don’t want to add an extra Entity just for representing the foreign key side.
- Code available on GitHub.
| Reference: | How to optimize Hibernate EllementCollection statements from our JCG partner Vlad Mihalcea at the Vlad Mihalcea’s Blog blog. |
