Interested to see how you can capture these Java Performance Metrics with AppDynamics? Start a FREE trial now!
The last couple articles presented an introduction to Application Performance Management (APM) and identified the challenges in effectively implementing an APM strategy. This article builds on these topics by reviewing five of the top performance metrics to capture to assess the health of your enterprise Java application.
Specifically this article reviews the following:
- Business Transactions
- External Dependencies
- Caching Strategy
- Garbage Collection
- Application Topology
1. Business Transactions
Business Transactions provide insight into real-user behavior: they capture real-time performance that real users are experiencing as they interact with your application. As mentioned in the previous article, measuring the performance of a business transaction involves capturing the response time of a business transaction holistically as well as measuring the response times of its constituent tiers. These response times can then be compared with the baseline that best meets your business needs to determine normalcy.
If you were to measure only a single aspect of your application I would encourage you to measure the behavior of your business transactions. While container metrics can provide a wealth of information and can help you determine when to auto-scale your environment, your business transactions determine the performance of your application. Instead of asking for the thread pool usage in your application server you should be asking whether or not your users are able to complete their business transactions and if those business transactions are behaving normally.
As a little background, business transactions are identified by their entry-point, which is the interaction with your application that starts the business transaction. A business transaction entry-point can be defined by interactions like a web request, a web service call, or a message on a message queue. Alternatively, you may choose to define multiple entry-points for the same web request based on a URL parameter or for a service call based on the contents of its body. The point is that the business transaction needs to be related to a function that means something to your business.
Once a business transaction is identified then its performance is measured across your entire application ecosystem. The performance of each individual business transaction is evaluated against its baseline to assess normalcy. For example, we might determine that if the response time of the business transaction is slower than two standard deviations from the average response time for this baseline that it is behaving abnormally, as shown in figure 1.

The baseline used to evaluate the business transaction is evaluated is consistent for the hour in which the business transaction is running, but the business transaction is being refined by each business transaction execution. For example, if you have chosen a baseline that compares business transactions against the average response time for the hour of day and the day of the week, after the current hour is over, all business transactions executed in that hour will be incorporated into the baseline for next week. Through this mechanism an application can evolve over time without requiring the original baseline to be thrown away and rebuilt; you can consider it as a window moving over time.
In summary, business transactions are the most reflective measurement of the user experience so they are the most important metric to capture.
2. External Dependencies
External dependencies can come in various forms: dependent web services, legacy systems, or databases; external dependencies are systems with which your application interacts. We do not necessarily have control over the code running inside external dependencies, but we often have control over the configuration of those external dependencies, so it is important to know when they are running well and when they are not. Furthermore, we need to be able to differentiate between problems in our application and problems in dependencies.
From a business transaction perspective, we can identify and measure external dependencies as being in their own tiers. Sometimes we need to configure the monitoring solution to identify methods that really wrap external service calls, but for common protocols, such as HTTP and JDBC, external dependencies can be automatically detected. For example, when I worked at an insurance company, we had an AS/400 and we used a proprietary protocol to communicate with it.
We identified that method call as an external dependency and attributed its execution to the AS/400. But we also had web service calls that could be automatically identified for us. And similar to business transactions and their constituent application tiers, external dependency behavior should be baselined and response times evaluated against those baselines.
Business transactions provide you with the best holistic view of the performance of your application and can help you triage performance issues, but external dependencies can significantly affect your applications in unexpected ways unless you are watching them.
3. Caching Strategy
It is always faster to serve an object from memory than it is to make a network call to retrieve the object from a system like a database; caches provide a mechanism for storing object instances locally to avoid this network round trip. But caches can present their own performance challenges if they are not properly configured. Common caching problems include:
- Loading too much data into the cache
- Not properly sizing the cache
I work with a group of people that do not appreciate Object-Relational Mapping (ORM) tools in general and Level-2 caches in particular. The consensus is that ORM tools are too liberal in determining what data to load into memory and in order to retrieve a single object, the tool needs to load a huge graph of related data into memory. Their concern with these tools is mostly unfounded when the tools are configured properly, but the problem they have identified is real. In short, they dislike loading large amounts of interrelated data into memory when the application only needs a small subset of that data.
When measuring the performance of a cache, you need to identify the number of objects loaded into the cache and then track the percentage of those objects that are being used. The key metrics to look at are the cache hit ratio and the number of objects that are being ejected from the cache. The cache hit count, or hit ratio, reports the number of object requests that are served from cache rather than requiring a network trip to retrieve the object.
If the cache is huge, the hit ratio is tiny (under 10% or 20%), and you are not seeing many objects ejected from the cache then this is an indicator that you are loading too much data into the cache. In other words, your cache is large enough that it is not thrashing (see below) and contains a lot of data that is not being used.
The other aspect to consider when measuring cache performance is the cache size. Is the cache too large, as in the previous example? Is the cache too small? Or is the cache sized appropriately?
A common problem when sizing a cache is not properly anticipating user behavior and how the cache will be used. Let’s consider a cache configured to host 100 objects, but that the application needs 300 objects at any given time. The first 100 calls will load the initial set of objects into the cache, but subsequent calls will fail to find the objects they are looking for. As a result, the cache will need to select an object to remove from the cache to make room for the newly requested object, such as by using a least-recently-used (LRU) algorithm.
The request will need to execute a query across the network to retrieve the object and then store it in the cache. The result is that we’re spending more time managing the cache rather than serving objects: in this scenario the cache is actually getting in the way rather than improving performance. To further exacerbate problems, because of the nature of Java and how it manages garbage collection, this constant adding and removing of objects from cache will actually increase the frequency of garbage collection (see below).
When you size a cache too small and the aforementioned behavior occurs, we say that the cache is thrashing and in this scenario it is almost better to have no cache than a thrashing cache. Figure 2 attempts to show this graphically.

In this situation, the application requests an object from the cache, but the object is not found. It then queries the external resource across the network for the object and adds it to the cache. Finally, the cache is full so it needs to choose an object to eject from the cache to make room for the new object and then add the new object to the cache.
Interested to see how you can capture these Java Performance Metrics with AppDynamics? Start a FREE trial now!
4. Garbage Collection
One of the core features that Java provided, dating back to its initial release, was garbage collection, which has been both both a blessing and a curse. Garbage collection relieves us from the responsibility of manually managing memory: when we finish using an object, we simply delete the reference to that object and garbage collection will automatically free it for us. If you come from a language that requires manually memory management, like C or C++, you’ll appreciate that this alleviates the headache of allocating and freeing memory.
Furthermore, because the garbage collector automatically frees memory when there are no references to that memory, it eliminates traditional memory leaks that occur when memory is allocated and the reference to that memory is deleted before the memory is freed. Sounds like a panacea, doesn’t it?
While garbage collection accomplished its goal of removing manual memory management and freeing us from traditional memory leaks, it did so at the cost of sometimes-cumbersome garbage collection processes. There are several garbage collection strategies, based on the JVM you are using, and it is beyond the scope of this article to dive into each one, but it suffices to say that you need to understand how your garbage collector works and the best way to configure it.
The biggest enemy of garbage collection is known as the major, or full, garbage collection. With the exception of the Azul JVM, all JVMs suffer from major garbage collections. Garbage collections come in a two general forms:
- Minor
- Major
Minor garbage collections occur relatively frequently with the goal of freeing short-lived objects. They do not freeze JVM threads as they run and they are not typically significantly impactful.
Major garbage collections, on the other hand, are sometimes referred to as “Stop The World” (STW) garbage collections because they freeze every thread in the JVM while they run. In order to illustrate how this happens, I’ve included a few figures from my book, Pro Java EE 5 Performance Management and Optimization.
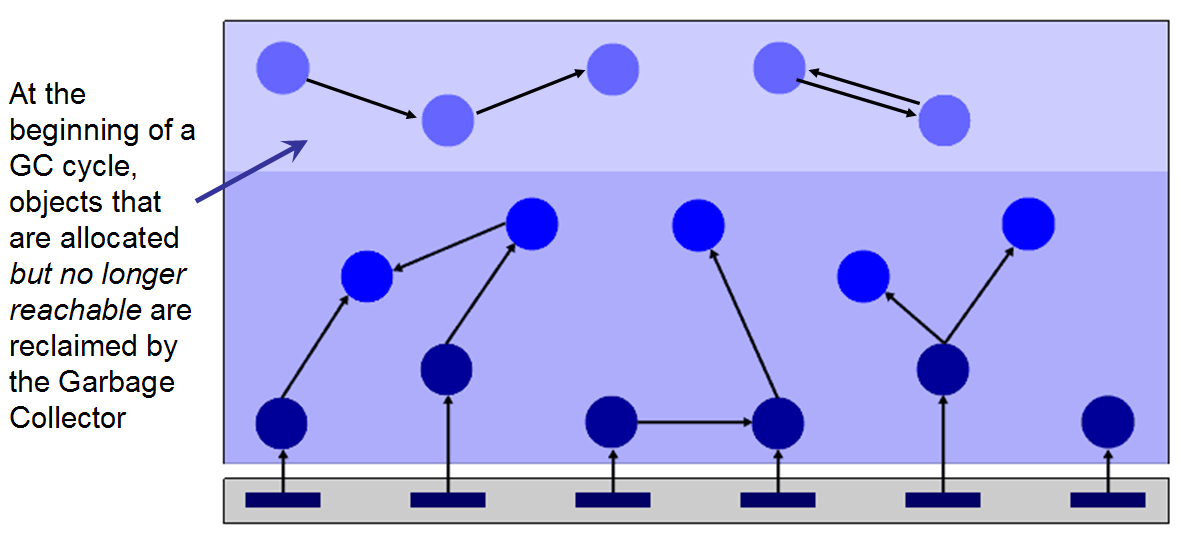
When garbage collection runs, it performs an activity called the reachability test, shown in figure 3. It constructs a “root set” of objects that include all objects directly visible by every running thread. It then walks across each object referenced by objects in the root set, and objects referenced by those objects, and so on, until all objects have been referenced. While it is doing this it “marks” memory locations that are being used by live objects and then it “sweeps” away all memory that is not being used. Stated more appropriately, it frees all memory to which there is not an object reference path from the root set. Finally, it compacts, or defragments, the memory so that new objects can be allocated.
Minor and major collections vary depending on your JVM, but figures 4 and 5 show how minor and major collections operate on a Sun JVM.

In a minor collection, memory is allocated in the Eden space until the Eden space is full. It performs a “copy” collector that copies live objects (reachability test) from Eden to one of the two survivor spaces (to space and from space). Objects left in Eden can then be swept away. If the survivor space fills up and we still have live objects then those live objects will be moved to the tenured space, where only a major collection can free them.
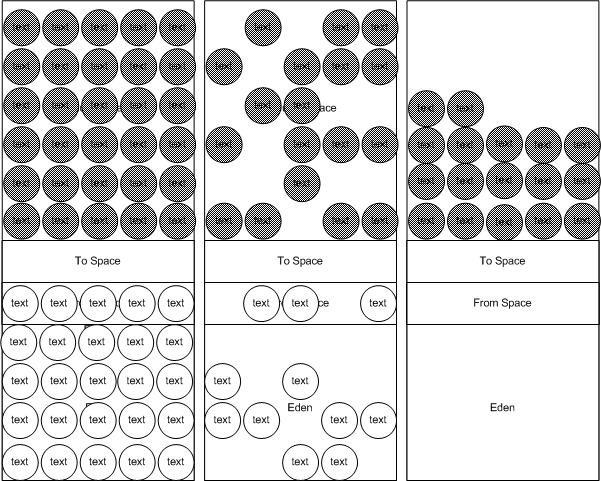
Eventually the tenured space will fill up and a minor collection will run, but it will not have any space in the tenured space to copy live objects that do not fit in the survivor space. When this occurs, the JVM freezes all threads in the JVM, performs the reachability test, clears out the young generation (Eden and the two survivor spaces), and compacts the tenured space. We call this a major collection.
As you might expect, the larger your heap, the less frequently major collections run, but when the do run they take much longer than smaller heaps. Therefore it is important to tune your heap size and garbage collection strategy to meet your application behavior.
5. Application Topology
The final performance component to measure in this top-5 list is your application topology. Because of the advent of the cloud, applications can now be elastic in nature: your application environment can grow and shrink to meet your user demand. Therefore, it is important to take an inventory of your application topology to determine whether or not your environment is sized optimally. If you have too many virtual server instances then your cloud-hosting cost is going to go up, but if you do not have enough then your business transactions are going to suffer.
It is important to measure two metrics during this assessment:
- Business Transaction Load
- Container Performance
Business transactions should be baselined and you should know at any given time the number of servers needed to satisfy your baseline. If your business transaction load increases unexpectedly, such as to more than two times the standard deviation of normal load then you may want to add additional servers to satisfy those users.
The other metric to measure is the performance of your containers. Specifically you want to determine if any tiers of servers are under duress and, if they are, you may want to add additional servers to that tier. It is important to look at the servers across a tier because an individual server may be under duress due to factors like garbage collection, but if a large percentage of servers in a tier are under duress then it may indicate that the tier cannot support the load it is receiving.
Because your application components can scale individually, it is important to analyze the performance of each application component and adjust your topology accordingly.
Conclusion
This article presented a top-5 list of metrics that you might want to measure when assessing the health of your application. In summary, those top-5 items were:
- Business Transactions
- External Dependencies
- Caching Strategy
- Garbage Collection
- Application Topology
In the next article we’re going to pull all of the topics in this series together to present the approach that AppDynamics took to implementing its APM strategy. This is not a marketing article, but rather an explanation of why certain decisions and optimizations were made and how they can provide you with a powerful view of the health of a virtual or cloud-based application.
Interested to see how you can capture these Java Performance Metrics with AppDynamics? Start a FREE trial now!
| Reference: | Top 5 Java Performance Metrics to Capture in Enterprise Applications from our JCG partner Steven Haines at the AppDynamics blog. |
