This is the last in a series of Postgres posts that Pat Shaughnessy wrote based on his presentation at the Barcelona Ruby Conference. You can also watch the video recording of the presentation. The series was originally published on his personal blog, and we are republishing it on Codeship with his kind permission. You can also read posts one, two, and three in the series.

We all know indexes are one of the most powerful and important features of relational database servers. How do you search for a value quickly? Create an index. What do you have to remember to do when joining two tables together? Create an index. How do you speed up a SQL statement that’s beginning to run slowly? Create an index.
But what are indexes, exactly? And how do they speed up our database searches?
To find out, I decided to read the C source code inside the PostgreSQL database server, to follow along as it searched an index for a simple string value. I expected to find sophisticated algorithms and efficient data structures. And I did.
Today I’ll show you what indexes look like inside Postgres and explain how they work. What I didn’t expect to find — what I discovered for the first time reading the Postgres C source code — was the Computer Science theory behind what it was doing. Reading the Postgres source was like going back to school and taking that class I never had time for when I was younger. The C comments inside Postgres not only explain what Postgres does, but why.
You know indexes are powerful. You know they’re important. But do you know how they work?
Sequence Scans: A Mindless Search
When we left the crew of the Nautilus, they were exhausted and beginning to faint: the Postgres sequence scan algorithm was mindlessly looping over all of the records in the users table!
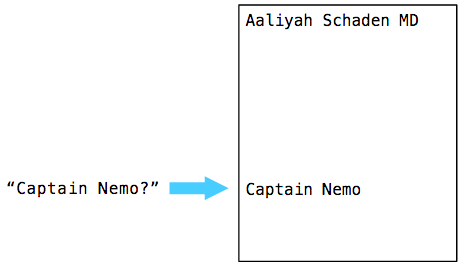
Recall in my last post we had executed this simple SQL statement to find Captain Nemo:

Postgres first parsed, analyzed and planned the query. Then ExecSeqScan, the C function inside of Postgres that implements the sequence scan (SEQSCAN) plan node, quickly found Captain Nemo:
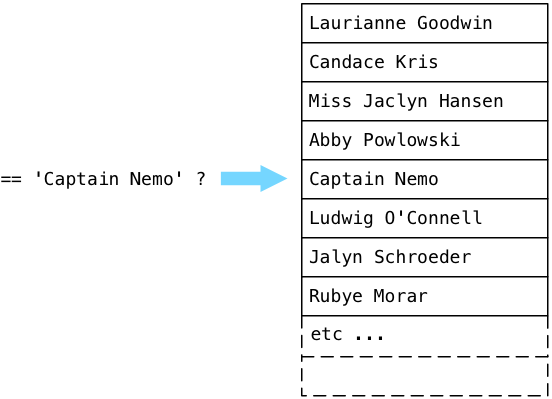
But then inexplicably Postgres continued to loop through the entire user table, comparing each name to “Captain Nemo,” even though we had already found what we were looking for!
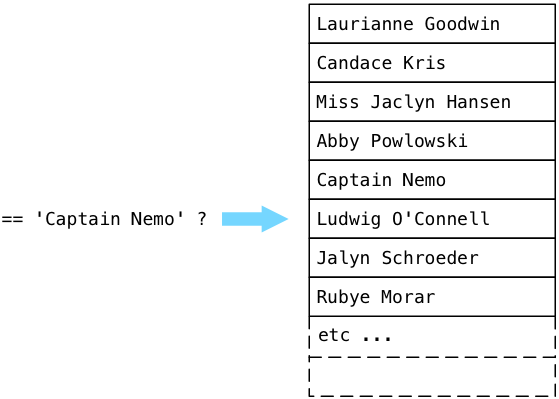
Imagine if our users table had millions of records; this could take a very long time. Of course, we could have avoided this by removing the sort and rewriting our query to accept the first name, but the deeper problem here is the inefficient way Postgres searches for our target string.
Using a sequence scan to compare every single value in the users table with “Captain Nemo” is slow, inefficient and depends on the random order the names appear in the table. What are we doing wrong? There must be a better way!
The answer is simple: We forgot to create an Index. Let’s do that now.
Creating an Index
Creating an index is straightforward — we just need to run this command:
![]()
As Ruby developers, of course, we would use the add_index ActiveRecord migration instead; this would run the same CREATE INDEX command behind the scenes. When we rerun our select statement, Postgres will create a plan tree as usual — but this time the plan tree will be slightly different:
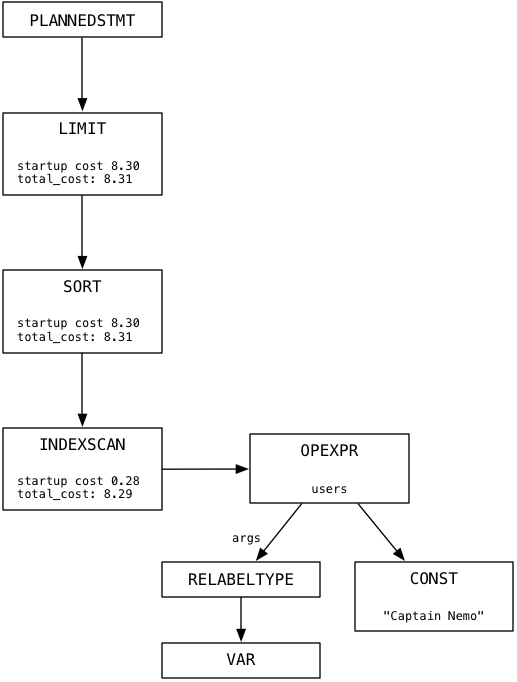
Notice at the bottom Postgres now uses INDEXSCAN instead of SEQSCAN. Unlike SEQSCAN, INDEXSCAN won’t iterate over the entire users table. Instead, it will use the index we just created to find and return the Captain Nemo records quickly and efficiently.
Creating an index has solved our performance problem, but it’s also left us with many interesting, unanswered questions:
- What is a Postgres index, exactly?
- If I could go inside of a Postgres database and take a close look at an index, what would it look like?
- And how does an index speed up searches?
Let’s try to answer these questions by reading the Postgres C source code.
What Is a Postgres Index, Exactly?
We can get started with a look at the documentation for the CREATE INDEX command.
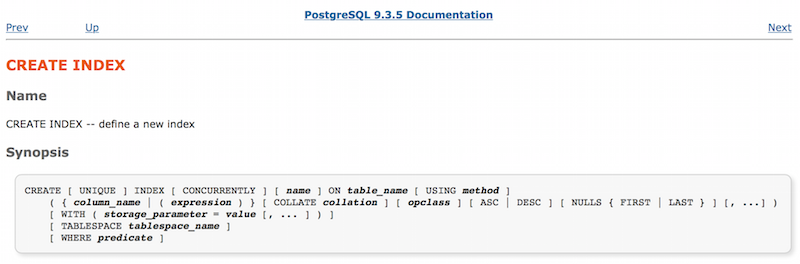
Here you can see all of the options we can use to create an index, such as UNIQUE and CONCURRENTLY. Notice there’s an option called USING method. This tells Postgres what kind of index we want. Farther down the same page is some information about method, the argument to the USING keyword:

It turns out Postgres implements four different types of indexes. You can use them for different types of data and in different situations. Because we didn’t specify USING at all, our index_users_on_name index is a “btree” (or B-Tree) index, the default type.
This is our first clue: a Postgres index is a B-Tree. But what is a B-Tree? Where can we find one? Inside of Postgres, of course! Let’s search the Postgres C source code for files containing “btree:”
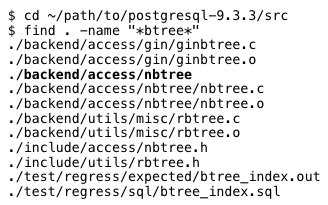
The key result is in bold: “./backend/access/nbtree.” Inside this directory is a README file; let’s read it:


Amazingly, this README file turns out to be an extensive 12-page document! The Postgres source code not only contains helpful and interesting C comments, it also contains documentation about the theory and implementation of the database server.
Reading and understanding the code in open source projects can often be intimidating and difficult, but not for Postgres. The developers behind Postgres have gone to great lengths to help the rest of us understand their work.
The title of the README document, “Btree Indexing,” confirms this directory contains the C code that implements Postgres B-Tree indexes. But the first sentence is even more interesting: it’s a reference to an academic paper that explains what a B-Tree is, and how Postgres indexes work: Efficient Locking for Concurrent Operations on B-Trees, by Lehman and Yao.
We’ll find our first look at a B-Tree inside this academic paper.
What Does a B-Tree Index Look Like?
Lehman and Yao’s paper explains an innovation they made to the B-Tree algorithm in 1981. I’ll discuss this a bit later. But they start with a simple introduction to the B-Tree data structure, which was actually invented 9 years earlier in 1972. One of their diagrams shows an example of a simple B-Tree:
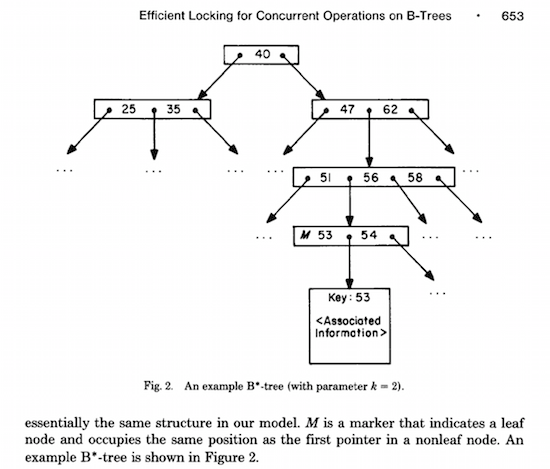
The term B-Tree actually stands for “balanced tree.” B-Trees make searching easy and fast. For example, if we wanted to search for the value 53 in this example, we first start at the root node which contains the value 40:
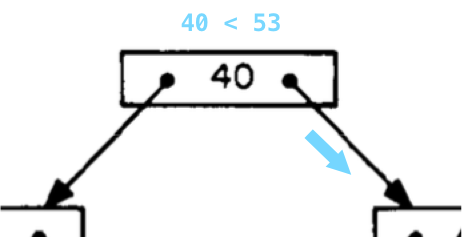
We compare our target value of 53 with the value we find in the tree node. Is 53 greater than or less than 40? Because 53 is greater than 40, we follow the pointer down to the right. If we were searching for 29, we would go down to the left. Pointers on the right lead to larger values; pointers on the left to smaller ones.
Following the pointer down the tree to the next child tree node, we encounter a node that contains 2 values:
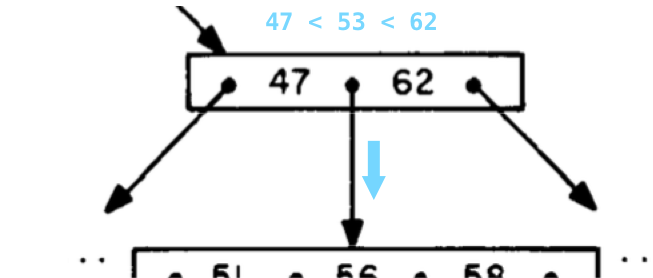
This time we compare 53 with both 47 and 62, and find that 47 < 53 < 62. Note the values in the tree node are sorted, so this will be easy to do. This time we follow the center pointer down. Now we get to another tree node, this one with 3 values in it:
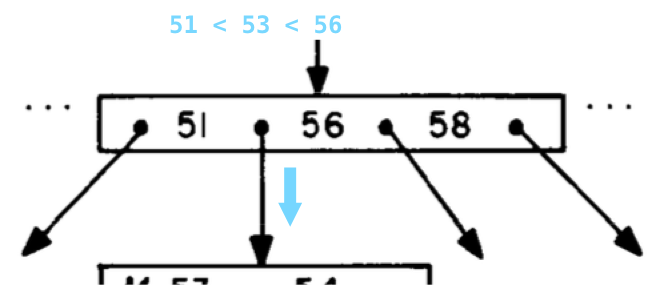
Looking through the sorted list of numbers, we find 51 < 53 < 56, and follow the second of four pointers down. Finally, we come to a leaf node in the tree:

And we’ve found the value 53!
B-Trees speed up searches because:
- They sort the values (known as keys) inside of each node.
- They are balanced: B-Trees evenly distribute the keys among the nodes, minimizing the number of times we have to follow a pointer from one node to another. Each pointer leads to a child node that contains more or less the same number of keys each other child node does.
What Does a Postgres Index Look Like?
Lehman and Yao drew this diagram over 30 years ago — what does it have to do with how Postgres works today? Astonishingly, the index_users_on_name index we created earlier looks very similar to Figure 2: We created an index in 2014 that looks just like a diagram from 1981!
When we executed the CREATE INDEX command, Postgres saved all of the names from our users table into a B-Tree. These became the keys of the tree. Here’s what a node inside a Postgres B-Tree index looks like:
![]()
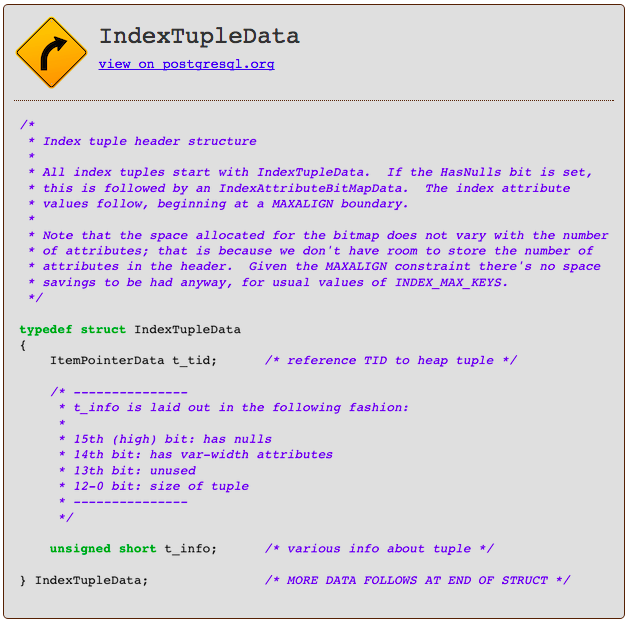
Each entry in the index consists of a C structure called IndexTupleData and is followed by a bitmap and a value. Postgres uses the bitmap to record whether any of the index attributes in a key are NULL, to save space. The actual values in the index appear after the bitmap.
Let’s take a closer look at the IndexTupleData structures:

Above you can see each IndexTupleData structure contains:
- t_tid: This is a pointer to either another index tuple, or to a database record. Note this isn’t a C pointer to physical memory; instead, it contains numbers Postgres can use to find the referenced value among its memory pages.
- t_info: This contains information about the index tuple, such as how many values it contains, and whether or not there are null values.
To understand this better, let’s show a few entries from our index_users_on_name index:
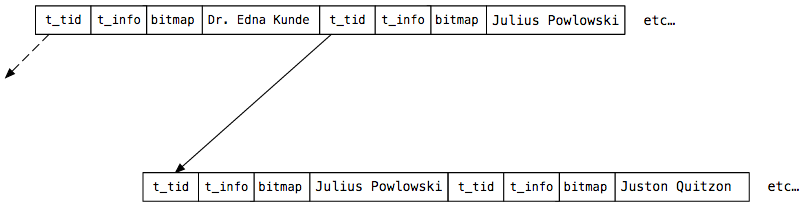
Now I’ve replaced “value” with some names from my users table. The upper tree node includes the keys “Dr. Edna Kunde” and “Julius Powlowski,” while the lower tree node contains “Julius Powlowski” and “Juston Quitzon.”
Notice that, unlike Lehman and Yao’s diagram, Postgres repeats the parent keys in each child node. Here “Julius Powlowski” is a key in the upper node and in the child node. The t_tid pointer from Julius in the upper node references the same Julius name in the lower node.
To learn more about exactly how Postgres stores key values into a B-Tree node, refer to the itup.h C header file:
Finding the B-Tree Node Containing Captain Nemo
Now let’s return to our original SELECT statement again:
How exactly does Postgres search our index_users_on_name index for “Captain Nemo?” Why is using the index faster than the sequence scan we saw in my last post? To find out, let’s zoom out a bit and take a look at some of the user names in our index:
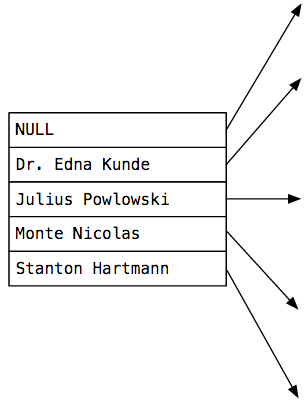
This is the root node of the index_users_on_name B-Tree. I’ve turned the tree on its side so the names would fit. You can see 4 names and a NULL value. Postgres created this root node when I created index_users_on_name.
Note that, aside from the first NULL value which represents the beginning of the index, the other 4 names are more or less evenly distributed in alphabetical order.
Remember that a B-Tree is a balanced tree. In this example, the B-Tree has 5 child nodes:
- the names that appear before Dr. Edna Kunde alphabetically
- names that appear between Dr. Edna Kunde and Julius Powlowski
- names that appear between Julius Powlowski and Monte Nicolas
- etc…
Because we’re searching for Captain Nemo, Postgres follows the first, top arrow to the right. This is because Captain Nemo comes before Dr. Edna Kunde alphabetically:
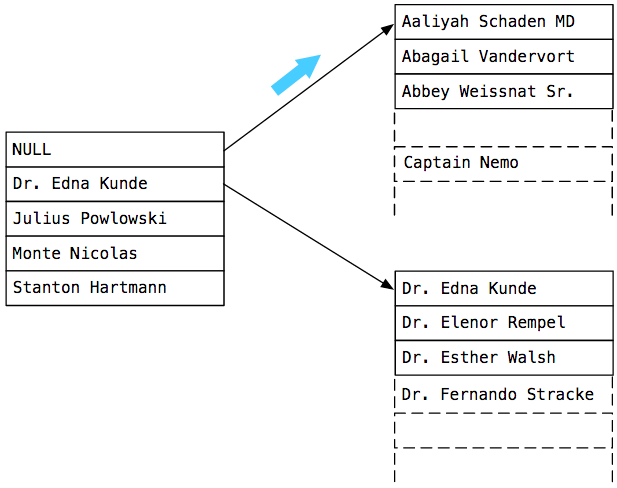
You can see on the right that Postgres has found the B-Tree node that contains Captain Nemo. For my test I added 1000 names to the users table; this child node in the B-Tree contained about 200 names (240 actually). The B-Tree has narrowed down Postgres’s search considerably.
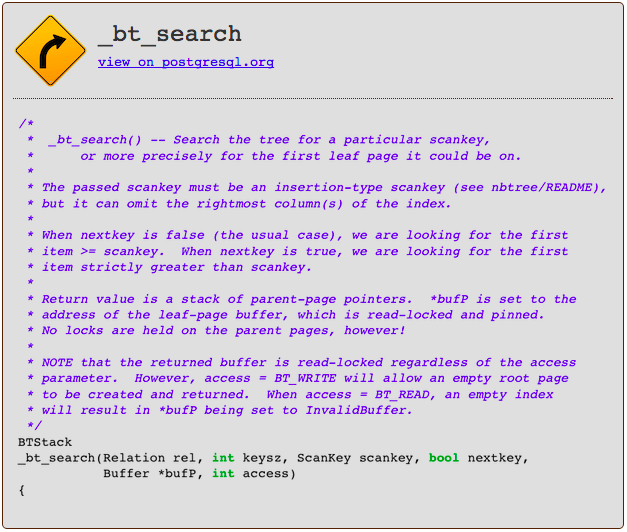
To learn more about the precise algorithm Postgres uses to search for the target B-Tree node among all of the nodes in the tree, read the _bt_search function.
Finding Captain Nemo Inside a Single B-Tree Node
Now that Postgres has narrowed down the search to a B-Tree node containing about 200 names, it still has to find Captain Nemo… how does it do this? Does it perform a sequence scan on this shorter list?

No. To search for a key value inside of a tree node, Postgres switches to use a binary search algorithm. It starts by comparing the key that appears at the 50% position in the tree node with “Captain Nemo:”
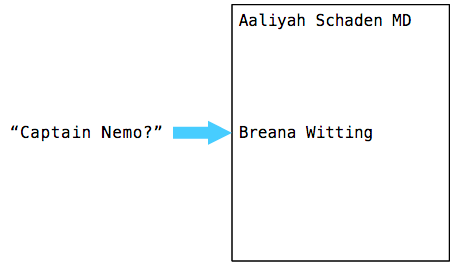
Because Captain Nemo comes after Breana Witting alphabetically, Postgres jumps down to the 75% position and performs another comparison:
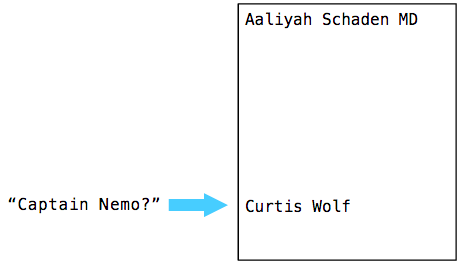
This time Captain Nemo comes before Curtis Wolf, so Postgres jumps back a bit. Skipping a few more steps (it actually took Postgres 8 comparisons to find Captain Nemo in my example), Postgres eventually finds what we are looking for:
To learn more about exactly how Postgres searches for a value in a single B-Tree node, read the _bt_binsrch function:

So Much More to Learn
I don’t have space in this blog post to cover many other fascinating details about B-Trees, database indexes or Postgres internals… maybe I should write Postgres Under a Microscope. But for now, here are just a few interesting bits of theory you can read about in Efficient Locking for Concurrent Operations on B-Trees or in the other academic papers it references.
- Inserting into B-Trees: The most beautiful part of the B-Tree algorithm has to do with inserting new keys into a tree. Key are inserted in sorted order into the proper tree node — but what happens when there’s no more room for a new key? In this situation, Postgres splits the node into two, inserts the new key into one of them, and also adds the key from the split point into the parent node, along with a pointer to the new child node. Of course, the parent node might also have to be split to fit its new key, resulting in a complex, recursive operation.
- Deleting from B-Trees: The converse operation is also interesting. When deleting a key from a node, Postgres will combine sibling nodes together when possible, removing a key from their parent. This can also be a recursive operation.
- B-Link-Trees: Lehman and Yao’s paper actually discusses an innovation they researched related to concurrency and locking when multiple threads are using the same B-Tree. Remember, Postgres’s code and algorithms need to be multithreaded because many clients could be searching or modifying the same index at the same time. By adding another pointer from each B-Tree node to the next sibling node — the so-called “right arrow” — one thread can search a tree even while a second thread is splitting a node without locking the entire index:
![]()
Don’t Be Afraid To Explore Beneath The Surface

Professor Aronnax risked his life and career to find the elusive Nautilus and to join Captain Nemo on a long series of amazing underwater adventures.
We should do the same: Don’t be afraid to dive underwater — inside and underneath the tools, languages and technologies that you use every day. You may know all about how to use Postgres, but do you really know how Postgres itself works internally?
Take a look inside; before you know it, you’ll be on an underwater adventure of your own.
Studying the Computer Science at work behind the scenes of our applications isn’t just a matter of having fun, it’s part of being a good developer.
As software development tools improve year after year, and as building web sites and mobile apps becomes easier and easier, we shouldn’t lose sight of the Computer Science we depend on. We’re all standing on the shoulders of giants — people like Lehman and Yao, and the open source developers who used their theories to build Postgres.
Don’t take the tools you use everyday for granted — take a look inside them! You’ll become a wiser developer and you’ll find insights and knowledge you could never have imagined before.
“Discovering the computer science behind Postgres indexes” via @pat_shaughnessy
| Reference: | Discovering the Computer Science Behind Postgres Indexes from our JCG partner Pat Shaughnessy at the Codeship Blog blog. |
