Continuing on with the Wimbledon data set I’ve been playing with I wanted to do some exploration on how the seeded players have fared over the years.
Taking the last 10 years worth of data there have always had 32 seeds and with the following function we can feed in a seeding and get back the round they would be expected to reach:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 | expected_round = function(seeding) { if(seeding == 1) { return("Winner") } else if(seeding == 2) { return("Finals") } else if(seeding <= 4) { return("Semi-Finals") } else if(seeding <= 8) { return("Quarter-Finals") } else if(seeding <= 16) { return("Round of 16") } else { return("Round of 32") }} > expected_round(1)[1] "Winner" > expected_round(4)[1] "Semi-Finals" |
We can then have a look at each of the Wimbledon tournaments and work out how far they actually got.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 | round_reached = function(player, main_matches) { furthest_match = main_matches %>% filter(winner == player | loser == player) %>% arrange(desc(round)) %>% head(1) return(ifelse(furthest_match$winner == player, "Winner", as.character(furthest_match$round)))} seeds = function(matches_to_consider) { winners = matches_to_consider %>% filter(!is.na(winner_seeding)) %>% select(name = winner, seeding = winner_seeding) %>% distinct() losers = matches_to_consider %>% filter( !is.na(loser_seeding)) %>% select(name = loser, seeding = loser_seeding) %>% distinct() return(rbind(winners, losers) %>% distinct() %>% mutate(name = as.character(name)))} |
Let’s have a look how the seeds got on last year:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | matches_to_consider = main_matches %>% filter(year == 2014) result = seeds(matches_to_consider) %>% group_by(name) %>% mutate(expected = expected_round(seeding), round = round_reached(name, matches_to_consider)) %>% ungroup() %>% arrange(seeding) rounds = c("Did not enter", "Round of 128", "Round of 64", "Round of 32", "Round of 16", "Quarter-Finals", "Semi-Finals", "Finals", "Winner")result$round = factor(result$round, levels = rounds, ordered = TRUE)result$expected = factor(result$expected, levels = rounds, ordered = TRUE) > result %>% head(10)Source: local data frame [10 x 4] name seeding expected round1 Novak Djokovic 1 Winner Winner2 Rafael Nadal 2 Finals Round of 163 Andy Murray 3 Semi-Finals Quarter-Finals4 Roger Federer 4 Semi-Finals Finals5 Stan Wawrinka 5 Quarter-Finals Quarter-Finals6 Tomas Berdych 6 Quarter-Finals Round of 327 David Ferrer 7 Quarter-Finals Round of 648 Milos Raonic 8 Quarter-Finals Semi-Finals9 John Isner 9 Round of 16 Round of 3210 Kei Nishikori 10 Round of 16 Round of 16 |
We’ll wrap all of that code into the following function:
01 02 03 04 05 06 07 08 09 10 11 12 | expectations = function(y, matches) { matches_to_consider = matches %>% filter(year == y) result = seeds(matches_to_consider) %>% group_by(name) %>% mutate(expected = expected_round(seeding), round = round_reached(name, matches_to_consider)) %>% ungroup() %>% arrange(seeding) result$round = factor(result$round, levels = rounds, ordered = TRUE) result$expected = factor(result$expected, levels = rounds, ordered = TRUE) return(result)} |
Next, instead of showing the round names it’d be cool to come up with numerical value indicating how well the player did:
- -1 would mean they lost in the round before their seeding suggested e.g. seed 2 loses in Semi Final
- 2 would mean they got 2 rounds further than they should have e.g. Seed 7 reaches the Final
The unclass function comes to our rescue here:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | # expectations plotyears = 2005:2014exp = data.frame()for(y in years) { differences = (expectations(y, main_matches) %>% mutate(expected_n = unclass(expected), round_n = unclass(round), difference = round_n - expected_n))$difference %>% as.numeric() exp = rbind(exp, data.frame(year = rep(y, length(differences)), difference = differences)) } > exp %>% sample_n(10)Source: local data frame [10 x 6] name seeding expected_n round_n difference year1 Tomas Berdych 6 6 5 -1 20112 Tomas Berdych 7 6 6 0 20133 Rafael Nadal 2 8 5 -3 20144 Fabio Fognini 16 5 4 -1 20145 Robin Soderling 13 5 5 0 20096 Jurgen Melzer 16 5 5 0 20107 Nicolas Almagro 19 4 2 -2 20108 Stan Wawrinka 14 5 3 -2 20119 David Ferrer 7 6 5 -1 201110 Mikhail Youzhny 14 5 5 0 2007 |
We can then group by the ‘difference’ column to see how seeds are getting on as a whole:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 | > exp %>% count(difference)Source: local data frame [9 x 2] difference n1 -5 22 -4 73 -3 244 -2 705 -1 666 0 857 1 438 2 179 3 4 library(ggplot2)ggplot(aes(x = difference, y = n), data = exp %>% count(difference)) + geom_bar(stat = "identity") + scale_x_continuous(limits=c(min(potential), max(potential) + 1)) |
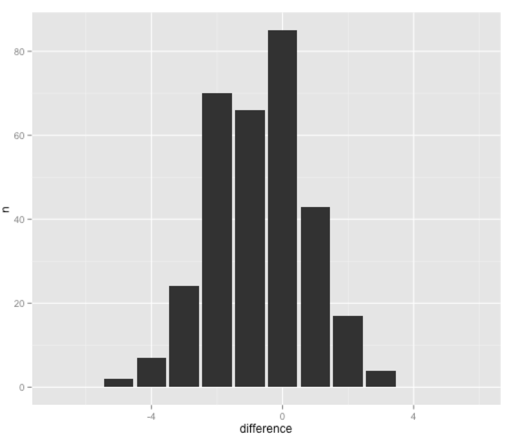
So from this visualisation we can see that the most common outcome for a seed is that they reach the round they were expected to reach. There are still a decent number of seeds who do 1 or 2 rounds worse than expected as well though.
Antonios suggested doing some analysis of how the seeds fared on a year by year basis – we’ll start by looking at what % of them exactly achieved their seeding:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 | exp$correct_pred = 0exp$correct_pred[dt$difference==0] = 1 exp %>% group_by(year) %>% summarise(MeanDiff = mean(difference), PrcCorrect = mean(correct_pred), N=n()) Source: local data frame [10 x 4] year MeanDiff PrcCorrect N1 2005 -0.6562500 0.2187500 322 2006 -0.8125000 0.2812500 323 2007 -0.4838710 0.4193548 314 2008 -0.9677419 0.2580645 315 2009 -0.3750000 0.2500000 326 2010 -0.7187500 0.4375000 327 2011 -0.7187500 0.0937500 328 2012 -0.7500000 0.2812500 329 2013 -0.9375000 0.2500000 3210 2014 -0.7187500 0.1875000 32 |
Some years are better than others – we can use a chisq test to see whether there are any significant differences between the years:
1 2 3 4 5 6 7 8 9 | tbl = table(exp$year, exp$correct_pred)tbl > chisq.test(tbl) Pearson's Chi-squared test data: tblX-squared = 14.9146, df = 9, p-value = 0.09331 |
This looks for at least one statistically significant different between the years, although it doesn’t look like there are any. We can also try doing a comparison of each year against all the others:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 | > pairwise.prop.test(tbl) Pairwise comparisons using Pairwise comparison of proportions data: tbl 2005 2006 2007 2008 2009 2010 2011 2012 20132006 1.00 - - - - - - - - 2007 1.00 1.00 - - - - - - - 2008 1.00 1.00 1.00 - - - - - - 2009 1.00 1.00 1.00 1.00 - - - - - 2010 1.00 1.00 1.00 1.00 1.00 - - - - 2011 1.00 1.00 0.33 1.00 1.00 0.21 - - - 2012 1.00 1.00 1.00 1.00 1.00 1.00 1.00 - - 2013 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 - 2014 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 P value adjustment method: holm |
2007/2011 and 2010/2011 show the biggest differences but they’re still not significant. Since we have so few data items in each bucket there has to be a really massive difference for it to be significant.
- The data I used in this post is available on this gist if you want to look into it and come up with your own analysis.
| Reference: | R: Wimbledon – How do the seeds get on? from our JCG partner Mark Needham at the Mark Needham Blog blog. |
