Introduction
Every software application can, in essence, be divided into two types : Compute Intensive Applications and Data Intensive Applications. And then there are applications that fall somewhere between these two extremes.
Today I would be talking about how to define the High Level Architecture for applications that are focused on leveraging the data of the enterprise in order to build a data driven organisation that is capable of handling its vast amount of data that is quite varied and is being generated at a fast pace.
I intend to have a series of blogs that will aim to tackle different aspects of building the Big Data Architecture. This is the starting blog and in this blog post I would be talking about the following:
- The data ecosystem
- Architecting a Big Data Application – High Level Architecture
- Defining the architecture Principles, Capabilities and Patterns
In the coming blog posts I would be focusing on the following:
- Lambda Architecture
- Data Ingestion Pipeline (Kafka, Flume)
- Data Processing – Real Time as well as Batch (MR, Spark, Storm)
- Kappa Architecture
- Data Indexing and querying
- Data Governance
I hope you enjoy reading these concepts as much as I did putting them here.
The Data Ecosystem
The data in today’s world consists of varied sources. These sources could be within an organisation like CRM Data, OLTP data, Billing data, product data or any other type of data that you constantly work with. There is also a lot of data within an organisation that can be leveraged for a variety of analytical purposes. mainly this is log data for varied servers running loads of applications.
There is also data that is generated outside of the company’s own ecosystem. For eg. a customer visiting the company’s website, an event stream about the company, events from sensors at the Oil Well, a person tweeting about the company’s service, an employee putting up pictures about a company event on his Facebook account, a hacker trying to get through to the company defence system and so on. All this type of data can broadly be classified into:
- Structured Data (for eg. data from CRM system)
- Semi Structured Data (for eg. CSV export file, XML or JSON based data etc)
- UnStructured Data (Video files, audio files etc)
All these sources of data provide an opportunity for a company to either make there process efficient, or provide superior services to their customers or detect and avoid security breaches before its too late. So the bottom line is that every piece of data collected from any source can have potential benefits for an organisation. And in order to leverage this benefit, the first and foremost thing for a company to have in place is a system that has the ability to store this vast amount of data and process this data.
It is very important to understand the kind of data you would be leveraging in your application. That understanding will give you a good ground to choose tools and technologies that will simply work for you rather than making the tools and technologies work for you. You can do that, i.e. put in an effort to make a certain technology work for your Use Case, but the effort you will spend on it will be more (sometimes significantly more) compared to tools that are custom built for your purpose.
So choose wisely. Hadoop is not the answer to all the Big Data Use Cases.
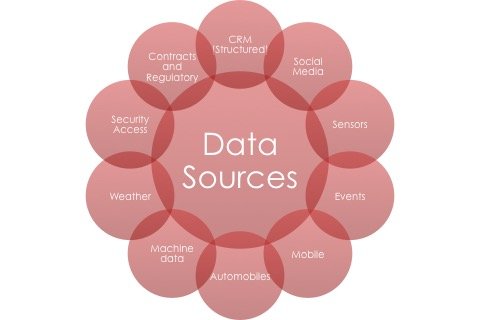
Big Data (Reference) Architecture
So how do we actually go about defining the an architecture for a Big Data Use Case. A good starting point is to have a reference architecture that guides you through the High Level Processes involved in a Big Data Application. you can find the reference architecture for Big Data developed by a lot of vendors in the Big data landscape, whether they are open source like Apache, Hortonworks or commercial like Cloudera, Oracle, IBM etc.
I prefer keeping things simple and not go too much in detail right now with the Reference Architecture. I will let it evolve naturally over the entire blog.
The picture below is inspired from one of Cloudera’s Blog : http://blog.cloudera.com/blog/2014/09/getting-started-with-big-data-architecture/
It is a good blog post to understand the High Level Big Data Architecture approach. I modified it slightly to keep it Technology Agnostic as well as I added Data Governance, which IMO, is a very important cross-cutting aspect that needs its separate bar.
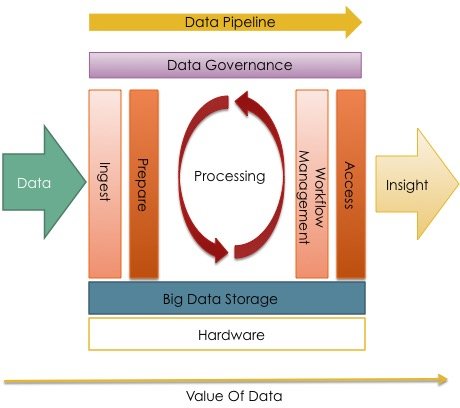
Let’s understand each of the above is slightly more detail.
Data Ingest: Ingestion is the process of bringing the data to the target system, in this case a Big data Storage system like Hadoop or Mongo or Cassandra or any other system that can handle the amount of data efficiently. This data can either arrive in bulk format (Batch Ingestion) or can be a continuous stream of data (Event or Stream Ingestion).
- Batch Ingestion: Typically used when you want to ingest data from one source to another. For example, you want to bring your CRM data into Hadoop. Typically what you would do is do a data dump from your relational Database and load this data dump into your Big Data Storage Platform. Thus you are doing a bulk or batch ingest of data.
- Stream Ingestion: When you have a continuous source of data that is emitting events regularly in the range of milliseconds to seconds, then you need a separate mechanism to ingest such data into your Big Data Storage Platform. You will typically employ some sort of Queueing system where events will be written and read regularly. Having a queueing system helps in offloading the load from the source.
As we will see in later blogs, having a robust Data Ingestion System that is capable of scaling, is distributed and supports parallel consumption is vital to your Big Data Application.
A quick note: Avoid using any sort of Single Consumer Queue as the Data Ingest Implementation.
Data Preparation: Data Preparation is the step performed typically before the actual processing of the data. Thus it can also be termed as preprocessing. But the main difference between Preparation and preprocessing is that the data is prepared once so that it can be processed efficiently by different processing scripts. Thus we call it here as Data Preparation.
Data Preparation involves steps like:
- Storing data in right format so that processing scripts can work on it efficiently (PlainText, CSV, SequenceFile, Avro, Parquet)
- Partitioning the data across hosts for things like data locality
- Data Access – to have data spread across your cluster in such a manner that multiple teams can work with the data without interfering with each others work. This is typically termed as multi tenancy. Defining Access Control Lists, different User Groups etc is part of the data access strategy
Data Processing: Data processing is all about taking an input data, transforming it into a usable format, for eg. a different file format or converting the CSV stored in your HDFS to an initial Hive Table. Ideally you do not loose any information when you perform the transformation step. Instead you simply restructure the data to work efficiently with it. Once you have done the transformation, you start performing some sort of analytics on the data. The analytics could be performed on the entire data set, or it could be performed on a subset of data. Usually analytics on the data set can be represented as Directed Acyclic Graph where you have a start node, you go through various steps, which are usually chosen by some form of Business Rules applied on the output of the previous node, and then finally you reach the last node which is the outcome of your business analytics algorithm. This output is ideally capable of answering the business queries, either on its own or by combining it with other outputs. This output is called a View. One thing to remember is that the analytics algorithm does not change your original data. Instead it simply reads the data at a different location, in-memory or on disk or somewhere else, modifies it and saves it as a view at a separate location.
Your original data is considered as your Master Data, the single source of truth for your entire application. You can always create the views again if you have your master data. But if your master data gets corrupted then it is not possible to recover back. So be extra careful while architecting the system for your master data management.
Workflow Management: At a given time there would be more than one analytics job that would be running on your master data set. There might be 10 different Map reduce jobs running, or x number of hive scripts, sqoop jobs, pig scripts etc. These needs to be managed somehow so that they are scheduled at the right time, do not consume lots of resources. May be you need to automate the whole workflow consisting of many hive scripts. Workflow management is the component that you use to manage the different jobs being executed on your Big Data System.
Data Access: Access to data is all about finding the mechanism to query your data, either through a simple SQL interface, of using Hive Queries or a query from an indexing engine like Solr. The access to data here mainly deals with access to your master data, which is your single source of truth. Your access methods could either be many, like Hive scripts, JDBC interfaces, REST APIs etc or it could be a single mechanism which is being used by all the teams. You need to make a choice based on your own setup and conditions within your organisation.
Data Insight: Once you have the data analysed, you then need to answer queries from your users. Answering queries could involve looking at the output of a single analytics job or combining the outputs from various jobs. Visualising the data is also sometimes considered part of developing insight into the data. Data Processing typically produces Key Performance Indicators (KPIs). These KPIs usually tells you part of the overall story. for example, an analytics system that monitors the Customer Premise Equipments (CPEs) like Modem can produce KPIs like LAN Configuration Error or Network Error. These KPIs give a initial view on the problem but may not be able to give the overall picture. For eg. a Network Error could happen because of many reasons. Thus these KPIs need to be correlated with other data set to gain insight into the actual problem.
Data Governance: Data Governance refers to the processes and policies to manage the data of an enterprise. Management tasks could involve availability of data, usability of data, security of data etc. An important aspect of data governance is Data Lineage. Data Lineage is defined as the lifecycle of data. We start with the origin of the data and capture metadata at each step the data is modified or moved. Data Lineage is important for a a variety of reasons. It may be an important tool for auditing your data. Or probably a user wants to know where the figure he sees in a report actually comes from and how it is derived.
Data Pipeline: A Data pipeline is a mechanism to move data between different components of your architecture. Consider it as a data bus that is fault tolerant and distributed
That is in essence there is all on the High Level Architecture for a Big Data System. There are still a lot of details that needs to be defined for the architecture and these details mainly concern with the non functional requirements of the System like Availability, Performance, Resilience, Maintenance and so on. We will go into each of the details later on in the coming blogs.
For now, I would like to focus on defining how to approach on defining a high level architecture for a Big Data System.
Now once you have a clear understanding that you are indeed dealing with Big Data and you need a System to handle your Big Data, the next step is to clearly define the Principles that your System should be built upon as well as any assumptions you have made. Typically the Principles guide the whole Architecture of the System and do not change throughout the lifecycle of your system.
Based on the Principles of the System, you start identifying the capabilities of your system like security, distributed processing, reliable messaging and so on. Finally when you have defined the capabilities, you look at different patterns that fit nicely with your capabilities and support your architecture principles. Thus in essence you do the following steps:
- Define the Architecture Principles
- Define the Architecture Capabilities
- Define the Architectural Patterns
Lets look at an example of defining each one of the above
Defining The Architecture Principles
An Architectural Principle is a rule that needs to be followed unless it has been proven beyond doubt that the Principle no more fits the overall goal of the application. View Architectural Principles as commandments written with a lot of thought and discussion and even though exceptions can be made to these rules, they should be rare. Thus, as an Architect it becomes extremely important to define the principles that align not only with the overall goal of the project but also takes into account other aspects like composition of the team, current available hardware and so on.
Here are some examples of Architecture Principles:
- The Application needs to be distributed across nodes. This may mean that platform components can be deployed on multiple nodes across the network transparently to the applications using this platform.
- The application should scale out under load and scale down during low activity without any downtime. This typically is termed as dynamic scaling.
- The services of the platform should be developed as loosely coupled components that interact using lightweight communication protocols.
When you are defining your Architectural Principles, make sure that they are technology neutral. So a principle should not be like this:
“The application should be developed using Java 7”
Principles are High Level Architecture Concerns. The low level details like implementation details, testing details should be kept out of them.
Defining the Architecture Capabilities
Once you have clearly identified the Architecture Principles, your next step should be to define the capabilities that your system should support. Typically, you define capabilities per architectural layer (UI Layer, Application gateway, Business Layer, Integration layer, data layer and sometimes also at Hardware layer) as well as capabilities that cut across different layers of the architecture like Logging and Monitoring Capabilities.
Here is an example of capabilities at different layers of a typical 4 layered architecture
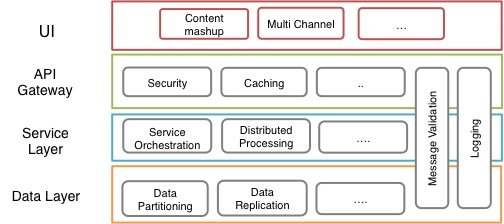
A capability is the ability to achieve a certain desired outcome using a set of features and or patterns. So when I say that Security is a capability, I mean that we would like to have Authentication and Authorization at the Service Gateway level. Now whether I use OAuth or SAML or JWT or any other technology is the next step. But I have identified that at the Service Gateway layer I need to have security in place otherwise I will be compromising my application. Thus for each of the layer you start thinking what set of capabilities you need in order to build your system. So for a Big Data System, you may need Distributed Processing Capability, Reliable Messaging Capability, Stream Processing Capability, Batch Processing Capability, Workflow management Capability, Data Replication Capability, Data Partitioning Capability ad so on.
Do not forget to peek back on your architectural principles at every possible time, just to be aligned with your principles.
Identifying the Architectural Patterns
Once you have defined the architectural capabilities, you then move to the next step of actually identifying how best you can implement that capability. For example, if you have the capability Data Partitioning, you need to define what pattern will you use to partition your data. For example will you use Hash Based Partitioning or will you use Range Based Partitioning. Deciding on patterns/strategies can sometimes be really easy (as you may have just one pattern and thus you don’t have to make choices) or it can be difficult when you need to understand and choose between different patterns and strategies.
I will be detailing on different patterns for scalable, distributed architecture in another blog post. For now it is important to understand that identifying and documenting the patterns for your application is an important first step in its success. You do not need to exhaustively define either the capabilities or the patterns, but you should have a good idea of them before you start moving to other parts of your architecture.
Conclusion
There is no right or wrong way to define an architecture for you application. As long as you are comfortable with what you have produced and are confident that you would be able to cleanly present as well as defend it in front of your stakeholders, that should be enough.
A clear an concise architecture description is the foundation to a successful system.
| Reference: | Architecting Data Intensive Applications – Part 1 from our JCG partner Anuj Kumar at the JavaWorld Blog blog. |

Awesome piece of writing. Thank you Anuj for sharing this. It really gives some insights about architecture of data processing and data management. Eagerly waiting for your next post.
Thanks Tanzeem.
A well written about data, really useful.. thanks for sharing