This article is part of our Academy Course titled Apache Lucene Fundamentals.
In this course, you will get an introduction to Lucene. You will see why a library like this is important and then learn how searching works in Lucene. Moreover, you will learn how to integrate Lucene Search into your own applications in order to provide robust searching capabilities. Check it out here!
Table Of Contents
1. Introduction
The Index is the heart of any component that utilizes Lucene. Much like the index of a book, it organizes all the data so that it is quickly accessible. An index consists of Documents containing one or more Fields. Documents and Fields can represent whatever we choose but a common metaphor is that Documents represent entries in a database table and Fields are akin to the fields in the table.
2. Understanding the indexing operation
Let’s look at the diagrammatic representation of Lucene search indexing.
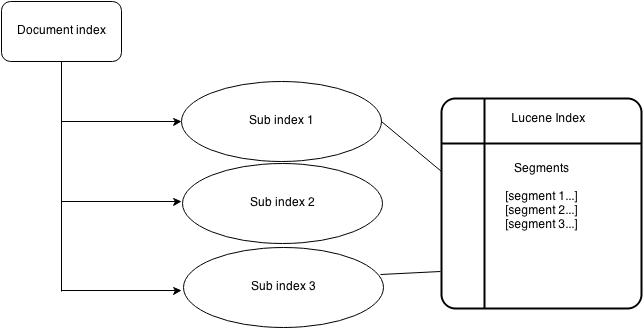
In a nutshell, when Lucene indexes a document it breaks it down into a number of terms. It then stores the terms in an index file where each term is associated with the documents that contain it. We could think of it a bit as a hashtable. Terms are generated using an analyzer which stems each word to its root form. When a query is issued, it is processed through the same analyzer that was used to build the index and then used to look up the matching term(s) in the index. That provides a list of documents that match the query.
Now lets take a look at the overall Lucene searching process.
The fundamental concepts are index, document, field and term.
- An index contains a collection of documents.
- A document is a collection of fields.
- A field is a collection of terms.
- A term is a paired string<field,term-string>.
2.1 Inverted Indexing
The index stores statistics about terms in order to make term-based search more efficient. Lucene’s index falls into the family of indexes known as an inverted index. This is because it can list, for a term, the documents that contain it. This is the inverse of the natural relationship, in which documents list terms.
2.2 Types of Fields
In Lucene, fields may be stored, in which case their text is stored in the index literally, in a non-inverted manner. Fields that are inverted are called indexed. A field may be both stored and indexed.
The text of a field may be tokenized into terms to be indexed, or the text of a field may be used literally as a term to be indexed. Most fields are tokenized, but sometimes it is useful for certain identifier fields to be indexed literally.
2.3 Segments
Lucene indexes may be composed of multiple sub-indexes, or segments. Each segment is a fully independent index, which could be searched separately. Indexes evolve by:
- Creating new segments for newly added documents.
- Merging existing segments.
- Searches may involve multiple segments and/or multiple indexes, each index potentially composed of a set of segments.
2.4 Document Numbers
Internally, Lucene refers to documents by an integer document number. The first document added to an index is numbered zero, and each subsequent document added gets a number one greater than the previous.
Note that a document’s number may change, so caution should be taken when storing these numbers outside of Lucene. In particular, numbers may change in the following situations:
The numbers stored in each segment are unique only within the segment, and must be converted before they can be used in a larger context. The standard technique is to allocate each segment a range of values, based on the range of numbers used in that segment. To convert a document number from a segment to an external value, the segment’s base document number is added. To convert an external value back to a segment-specific value, the segment is identified by the range that the external value is in, and the segment’s base value is subtracted. For example two five-document segments might be combined, so that the first segment has a base value of zero, and the second of five. Document three from the second segment would have an external value of eight.
When documents are deleted, gaps are created in the numbering. These are eventually removed as the index evolves through merging. Deleted documents are dropped when segments are merged. A freshly-merged segment thus has no gaps in its numbering.
2.5 Search Index
Search indexes are defined by a javascript function. This is run over all of your documents, in a similar manner to a view’s map function, and defines the fields that your search can query. Search index is a variant of database. It is similar with RDBMS as it needs to have a fast lookup for keys, but the bulk of the data resides on a secondary storage.
3. Creating an index
So far we have seen all the components of Lucene indexing. In this section we will create an index of documents using Lucene indexing.
Consider a project where students are submitting their yearly magazine articles. The input console consists of options for student name, title of the article, category of the article and the body of article. We are assuming that this project is running in the web & can be accessible through it. To index this article we will need the article itself, the name of the author, the date it was written, the topic of the article, the title of the article, and the URL where the file is located. With that information we can build a program that can properly index the article to make it easy to find.
Let’s look at the basic framework of our class including all the imports we will need.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 | import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.queryParser.QueryParser;import org.apache.lucene.search.Hits; import java.util.Date; public class ArticleIndexer { } |
The first thing we will need to add is a way to convert our article into a Document object.
For that we will use a method createDocument(),
01 02 03 04 05 06 07 08 09 10 11 12 13 | private Document createDocument(String article, String author, String title, String topic, String url, Date dateWritten) { Document document = new Document(); document.add(Field.Text("author", author)); document.add(Field.Text("title", title)); document.add(Field.Text("topic", topic)); document.add(Field.UnIndexed("url", url)); document.add(Field.Keyword("date", dateWritten)); document.add(Field.UnStored("article", article)); return document; } |
First we create a new Document object. The next thing we need to do is add the different sections of the article to the Document. The names that we give to each section are completely arbitrary and work much like keys in a HashMap. The name used must be a String. The add method of Document will take a Field object which we build using one of the static methods provided in the Field class. There are four methods provided for adding Field objects to a Document.
Field.Keyword – The data is stored and indexed but not tokenized. This is most useful for data that should be stored unchanged such as a date. In fact, the Field.Keyword can take a Date object as input.
Field.Text – The data is stored, indexed, and tokenized. Field.Text fields should not be used for large amounts of data such as the article itself because the index will get very large since it will contain a full copy of the article plus the tokenized version.
Field.UnStored – The data is not stored but it is indexed and tokenized. Large amounts of data such as the text of the article should be placed in the index unstored.
Field.UnIndexed – The data is stored but not indexed or tokenized. This is used with data that you want returned with the results of a search but you won’t actually be searching on this data. In our example, since we won’t allow searching for the URL there is no reason to index it but we want it returned to us when a search result is found.
Now that we have a Document object, we need to get an IndexWriter to write this Document to the index.
1 2 3 4 5 6 7 8 9 | String indexDirectory = "lucene-index"; private void indexDocument(Document document) throws Exception { Analyzer analyzer = new StandardAnalyzer(); IndexWriter writer = new IndexWriter(indexDirectory, analyzer, false); writer.addDocument(document); writer.optimize(); writer.close(); } |
We first create a StandardAnalyzer and then create an IndexWriter using the analyzer. In the constructor we must specify the directory where the index will reside. The boolean at the end of the constructor tells the IndexWriter whether it should create a new index or add to an existing index. When adding a new document to an existing index we would specify false. We then add the Document to the index. Finally, we optimize and then close the index. If you are going to add multiple Document objects you should always optimize and then close the index after all the Document objects have been added to the index.
Now we just need to add a method to pull the pieces together.
To drive the indexing operation, we will write a method indexArticle() which takes some parameters.
1 2 3 4 5 6 7 8 9 | public void indexArticle(String article, String author, String title, String topic, String url, Date dateWritten) throws Exception { Document document = createDocument(article, author, title, topic, url, dateWritten); indexDocument(document); } |
Running this for an article will add that article to the index. Changing the boolean in the IndexWriter constructor to true will create an index so we should use that the first time we create an index and whenever we want to rebuild the index from scratch. Now that we have constructed an index, we need to search it for an article.
An index is stored as a set of files within a single directory.
An index consists of any number of independent segments which store information about a subset of indexed documents. Each segment has its own terms dictionary, terms dictionary index, and document storage (stored field values). All segment data is stored in _xxxxx.cfs files, where xxxxx is a segment name.
Once an index segment file is created, it can’t be updated. New documents are added to new segments. Deleted documents are only marked as deleted in an optional .del file.
4. Basic index operations
Indexing data
Lucene lets us index any data available in textual format. Lucene can be used with almost any data source as long as textual information can be extracted from it. We can use Lucene to index and search data stored in HTML documents, Microsoft Word documents, PDF files, and more. The first step in indexing data is to make it available in simple text format. It is possible to do using custom parsers and data converters.
The indexing process
Indexing is a process of converting text data into a format that facilitates rapid searching. A simple analogy is an index you would find at the end of a book: That index points you to the location of topics that appear in the book.
Lucene stores the input data in a data structure called an inverted index, which is stored on the file system or memory as a set of index files. Most Web search engines use an inverted index. It lets users perform fast keyword look-ups and finds the documents that match a given query. Before the text data is added to the index, it is processed by an analyzer (using an analysis process).
Analysis
Analysis is converting the text data into a fundamental unit of searching, which is called as term. During analysis, the text data goes through multiple operations: extracting the words, removing common words, ignoring punctuation, reducing words to root form, changing words to lowercase, etc. Analysis happens just before indexing and query parsing. Analysis converts text data into tokens, and these tokens are added as terms in the Lucene index.
Lucene comes with various built-in analyzers, such as SimpleAnalyzer, StandardAnalyzer, StopAnalyzer, SnowballAnalyzer, and more. These differ in the way they tokenize the text and apply filters. As analysis removes words before indexing, it decreases index size, but it can have a negative effect on the precision of query processing. You can have more control over the analysis process by creating custom analyzers using basic building blocks provided by Lucene. Table 1 shows some of the built-in analyzers and the way they process data.
4.1 Core indexing classes
Directory
An abstract class that represents the location where index files are stored. There are primarily two subclasses commonly used:
FSDirectory — An implementation of Directory that stores indexes in the actual file system. This is useful for large indices.
RAMDirectory — An implementation that stores all the indices in the memory. This is suitable for smaller indices that can be fully loaded in memory and destroyed when the application terminates. As the index is held in memory, it is comparatively faster.
Analyzer
As discussed, the analyzers are responsible for preprocessing the text data and converting it into tokens stored in the index. IndexWriter accepts an analyzer used to tokenize data before it is indexed. To index text properly, you should use an analyzer that’s appropriate for the language of the text that needs to be indexed.
Default analyzers work well for the English language. There are several other analyzers in the Lucene sandbox, including those for Chinese, Japanese, and Korean.
IndexDeletionPolicy
An interface used to implement a policy to customize deletion of stale commits from the index directory. The default deletion policy is KeepOnlyLastCommitDeletionPolicy, which keeps only the most recent commits and immediately removes all prior commits after a new commit is done.
IndexWriter
A class that either creates or maintains an index. Its constructor accepts a Boolean that determines whether a new index is created or whether an existing index is opened. It provides methods to add, delete, or update documents in the index.
The changes made to the index are initially buffered in the memory and periodically flushed to the index directory. IndexWriter exposes several fields that control how indices are buffered in the memory and written to disk. Changes made to the index are not visible to IndexReader unless the commit or close method of IndexWriter are called. IndexWriter creates a lock file for the directory to prevent index corruption by simultaneous index updates. IndexWriter lets users specify an optional index deletion policy.
4.2 Adding data to an index
There are two classes involved in adding text data to the index.
Field represents a piece of data queried or retrieved in a search. The Field class encapsulates a field name and its value. Lucene provides options to specify if a field needs to be indexed or analyzed and if its value needs to be stored. These options can be passed while creating a field instance. The table below shows the details of Field metadata options.
| Option | Description |
Field.Store.Yes | Used to store the value of fields. Suitable for fields displayed with search results — file path and URL, for example. |
Field.Store.No | Field value is not stored — e-mail message body, for example. |
Field.Index.No | Suitable for the fields that are not searched — often used with stored fields, such as file path. |
Field.Index.ANALYZED | Used for fields that are indexed but not analyzed. It preserves a field’s original value in its entirety — dates and personal names, for example. |
Field.Index.NOT_ANALYZED | Used for fields that are indexed but not analyzed. It preserves a field’s original value in its entirety — dates and personal names, for example. |
Details of Field metadata options
And a Document is a collection of fields. Lucene also supports boosting documents and fields, which is a useful feature if you want to give importance to some of the indexed data. Indexing a text file involves wrapping the text data in fields, creating a document, populating it with fields, and adding the document to the index using IndexWriter.
5. Documents & fields
As you already saw previously, a Document is the unit of the indexing and searching process.
5.1 Documents
A Document is a set of fields. Each field has a name and a textual value. A field may be stored with the document, in which case it is returned with search hits on the document. Thus each document should typically contain one or more stored fields which uniquely identify it.
You add a document to the index and, after you perform a search, you get a list of results and they are documents. A document is just an unstructured collection of Fields.
5.2 Fields
Fields are the actual content holders of Lucene.net: they are basically a hashtable, with a name and value. If we had infinite disk space and infinite processing power that’s all we needed to know. But unfortunately disk space and processing power are constrained so you can’t just analyze everything and store into the index. But Lucene.net provides different ways of adding a field to the index.
Lucene offers four different types of fields from which a developer can choose: Keyword, UnIndexed, UnStored, and Text. Which field type you should use depends on how you want to use that field and its values.
Keyword fields are not tokenized, but are indexed and stored in the index verbatim. This field is suitable for fields whose original value should be preserved in its entirety, such as URLs, dates, personal names, Social Security numbers, telephone numbers, etc.
UnIndexed fields are neither tokenized nor indexed, but their value is stored in the index word for word. This field is suitable for fields that you need to display with search results, but whose values you will never search directly. Because this type of field is not indexed, searches against it are slow. Since the original value of a field of this type is stored in the index, this type is not suitable for storing fields with very large values, if index size is an issue.
UnStored fields are the opposite of UnIndexed fields. Fields of this type are tokenized and indexed, but are not stored in the index. This field is suitable for indexing large amounts of text that does not need to be retrieved in its original form, such as the bodies of Web pages, or any other type of text document.
Text fields are tokenized, indexed, and stored in the index. This implies that fields of this type can be searched, but be cautious about the size of the field stored as Text field.
If you look back at the LuceneIndexExample class, you will see that I used a Text field:
1 | document.add(Field.Text("fieldname", text)); |
If we wanted to change the type of field fieldname we would call one of the other methods of class Field:
1 | document.add(Field.Keyword("fieldname", text)); |
or
1 | document.add(Field.UnIndexed("fieldname", text)); |
or
1 | document.add(Field.UnStored("fieldname", text)); |
Although the Field.Text, Field.Keyword, Field.UnIndexed, and Field.UnStored calls may at first look like calls to constructors, they are really just calls to different Field class methods. Table 1 summarizes the different field types.
| Field method/type | Tokenized | Indexed | Stored |
Field.Keyword(String, String) | No | Yes | Yes |
Field.UnIndexed(String, String) | No | No | Yes |
Field.UnStored(String, String) | Yes | Yes | No |
Field.Text(String, String) | Yes | Yes | Yes |
Field.Text(String, Reader) | Yes | Yes | No |
Table 1: An overview of different field types.
5.3 Boosting Documents in Lucene
In Information Retrieval, a document’s relevance to a search is measured by how similar it is to the query. There are several similarity models implemented in Lucene, and you can implement your own by extending the Similarity class and using the index statistics that Lucene saves. Documents can also be assigned a static score to denote their importance in the overall corpus, irrespective of the query that is being executed, e.g their popularity, ratings or PageRank.
Prior to Lucene 4.0, you could assign a static score to a document by calling document.setBoost. Internally, the boost was applied to every field of the document, by multiplying the field’s boost factor with the document’s. However, this has never worked correctly and depending on the type of query executed, might not affect the document’s rank at all.
With the addition of DocValues to Lucene, boosting documents is as easy as adding a NumericDocValuesField and use it in a CustomScoreQuery, which multiplies the computed score by the value of the ‘boost’ field. The code example below illustrates how to achieve that:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 | // add two documents to the indexDocument doc = new Document();doc.add(new TextField("f", "test document", Store.NO));doc.add(new NumericDocValuesField("boost", 1L));writer.addDocument(doc); doc = new Document();doc.add(new TextField("f", "test document", Store.NO));doc.add(new NumericDocValuesField("boost", 2L));writer.addDocument(doc); // search for 'test' while boosting by field 'boost'Query baseQuery = new TermQuery(new Term("f", "test"));Query boostQuery = new FunctionQuery(new LongFieldSource("boost"));Query q = new CustomScoreQuery(baseQuery, boostQuery);searcher.search(q, 10); |
The new Expressions module can also be used for boosting documents by writing a simple formula, as depicted below. While it’s more verbose than using CustomScoreQuery, it makes boosting by computing more complex formulas trivial, e.g. sqrt(_score) + ln(boost).
1 2 3 4 5 6 | Expression expr = JavascriptCompiler.compile("_score * boost");SimpleBindings bindings = new SimpleBindings();bindings.add(new SortField("_score", SortField.Type.SCORE));bindings.add(new SortField("boost", SortField.Type.LONG));Sort sort = new Sort(expr.getSortField(bindings, true));searcher.search(baseQuery, null, 10, sort); |
Now that Lucene allows updating NumericDocValuesFields without re-indexing the documents, you can incorporate frequently changing fields (popularity, ratings, price, last-modified time…) in the boosting factor without re-indexing the document every time any one of them changes.
