The concepts of event sourcing (ES) and command-query responsibility segregation (CQRS) have been around for quite a while. They are getting more and more attention in the Java community, though they seem to have been much more popular over on the .NET side.
I have spent the last few months implementing a system with such an architecture at Oasis Digital. While working on it, we aimed for flexibility and the ability to make the right trade-offs and choose our own tools. Some interesting solutions came up in the process, things that would probably be impossible with existing frameworks like Axon.
I am going to write more about some of these pieces in the future. Before we get there, let’s start with a brief introduction to event sourcing and command-query responsibility segregation.
CQS
The main idea of command-query separation (CQS) is that all operations are either:
- commands, changing state of the system,
- queries, getting some information from the system.
Either one or the other, never both. For example, if a command changes anything in the system, it should not be used to read its state. Mutation-free read access should always be possible. Asking a system to change something to read a value seems plain wrong, and queries inadvertently changing state are very confusing, surprising and leading to bugs at best.
These principles can be applied on all levels. Uncle Bob in “Clean Code” calls it one of the main principles of good function design. The pattern is also applicable to system design.
CQRS in System Architecture
Command-query responsibility segregation (CQRS) is a pattern in system architecture inspired by CQS. It divides the system in two distinct parts, separating the components used for writing (executing commands) from those for querying. In such a system we can find two kinds of requests corresponding to these two models.
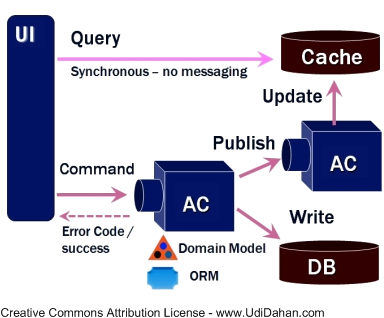
Firstly, there are commands – ordering the system do something or change its state. A piece of business logic updates the domain model (or rejects the command) and lets the client know that the change has been accepted (or not).
The business logic is often implemented using domain-driven design, but it may just as well be transaction script or any other applicable technique. Actually, we ended up using a mix of these two in one area of the system.
Whenever anything changes, the domain model somehow notifies everyone – for example by publishing domain events. These events are received by view models, which update their own representation of the state, separate from the domain model.
This leads us to the second kind of requests: queries, getting information from the system without changing its state. These only use the view models, not the domain.
What is especially powerful about this pattern is the separation of concerns.
The domain (write) side is all about the business. It does not care about queries, all the different ways to show this information to the users, performance, optimal storage for these purposes and all that.
On the other hand, the query (read) side is all about the read access. Its main purpose is making queries fast and convenient.
While the domain is only implemented once, there can be multiple view models over the same data. They often use different databases. They can even be using different technologies – all kinds of NoSQL, normalized and denormalized SQL, in-memory representations, Lucene indexes, OLAP cubes etc.
The read models are also free to use different languages, if they make anything easier. There are no obstacles to implementing the domain model in Scala, but doing view models in Clojure or even SQL stored procedures.
Overall, the view models are very good (and safe) candidates for innovation.
Unlike the domain model, code quality in view models does not have to be perfect. They’re all about reshaping data and moving it around to make reads convenient. Some shortcuts and dirty tricks may be acceptable, as long as they don’t make the whole thing unmaintainable.
Read models are often denormalized, prepared to answer concrete questions in optimal way. It can even be as extreme as having a precomputed set answers to every query that the system will handle, stored in some trivial key-value way.
We often call the view models “projections” – because they “project” the domain events to a particular model, keeping only as much information as is necessary and in optimal shape for queries they serve.
Note that all the domain logic is only implemented in the domain (write) model. It’s done once and in the right place. Even if a value is directly derived (calculated), as soon as it has a business meaning or is calculated with some business logic, it belongs in the domain model.
Event Sourcing
Another pattern commonly used with CQRS is event sourcing.
In short, it means that all data in the system is stored in the form of events, in an event log. An event is a piece of information stating that something has occurred (user created, name changed, shipping address added, order submitted, order delivered). They’re always in past tense, saying that something has happened.
The events never change. You can never delete or update them. If something has happened, it’s happened. If it was a mistake, it can be corrected with a complementary action generating a new “inverse” event, but there’s no going back and saying it has not happened.
Combining ES and CQRS
Event sourcing and command-query responsibility segregation perfectly fit each other. It’s a powerful synergy effect: each of them becomes more powerful thanks to the combination.
When a command comes in, the domain model calculates the new state of the system and possibly emits some new events (which are the only way the changes are persisted). When another command comes in for the same logical area, the domain model is restored from the past events, and responds to the new command by generating some new events. The events represent concrete changes that have business meanings. Technically in a sense they are “deltas” (or “diffs”) of the system state.
The view models simply handle these events, picking up only these they are interested in, and updating their state to support future queries.
Benefits
There are many benefits to using this approach, let me just point out a few of them.
CQRS naturally leads to task-based UIs. Every action represents some very concrete business event. There can be a huge difference between changing someone’s name, changing their shipping address, or making them a gold customer. If end user wants to change name, they get a small form that has exactly what is needed for that operation. If they make a customer gold – that’s another action in another form.
Contrast this with the traditional CRUD, spreadsheet-like systems. They have no such operations as “change name” or “change customer status to gold”. All the users can do is “change user”. Implementing logic that changes something when a particular field changes all of a sudden becomes harder. Validation is a nightmare. Auditing and simply seeing when something happened and what the users did, is impossible without adding more layers of complexity on top.
It is harder for the users, too – the use cases have to be implemented in their minds, knowing what to change when to achieve a desired effect.
Related to the above, and a reason why CQRS is often used with domain-driven design, is that the shape of the system naturally maps to business contexts and use cases. Commands correspond to concrete user intents, and queries are designed to answer concrete questions. Once again, it’s the exact opposite of a glorified spreadsheet-like DB frontend.
It’s applicable on higher level, too: Different areas of the business (bounded contexts in the DDD lingo) can be implemented as separate models. For example, a warehousing context can represent a book in a completely different way than a sales context. One may be interested in its size, weight and number on stock. The other – in author, genre, cover image, publisher description etc.
Event sourcing also makes reporting a lot easier. By definition it never loses information. Maybe yesterday you did not need to know how often users add and remove items from the shopping cart, and only cared about the orders they eventually submitted. But today business wants to trace this information, so maybe they can discover items that clients wanted but changed their mind. It may be worthwhile to tempt them with these items in future ads.
Answering such a change in a “traditional” system would be a nontrivial effort. With ES+CQRS chances are that all it will take is just another straightforward projection of data that is already there, and immediately answer questions about the past!
Finally, another obvious benefit is performance. Since the view models are separate, they can have very different schema. Avoid joins, keep data denormalized, answer many questions in linear or even constant time. Read-only access is much easier to scale, as is the write side which doesn’t care about queries anymore.
Costs
ES+CQRS is not without cost, and is not the best approach to all systems. More about this in a future post.
More Resources
Like I said in the beginning, these ideas have been around for quite a few years. There is a huge number of resources available online, in books and at conferences. This post has merely scratched the surface and is only meant as (yet another) humble introduction to the topic.
Here’s a few links to the masters:
- Martin Fowler on Event Sourcing, CQS and CQRS.
- Udi Dahan on CQRS.
- Greg Young:
- CQRS, Task Based UIs, Event Sourcing agh! – very quick introduction to ES, CQRS and task-based UIs.
- CQRS and Event Sourcing – Code on the Beach 2014 (video)
- Six-hour long class (video)
- 8 Lines of Code (video)
- Sandro Mancuso on Crafted Design (video) – pragmatic approach to architecture inspired by CQRS.
This post also appeared on the Oasis Digital blog.
| Reference: | Introduction to Event Sourcing and Command-Query Responsibility Segregation from our JCG partner Konrad Garus at the Squirrel’s blog. |
