This article is part of our Academy Course titled MongoDB – A Scalable NoSQL DB.
In this course, you will get introduced to MongoDB. You will learn how to install it and how to operate it via its shell. Moreover, you will learn how to programmatically access it via Java and how to leverage Map Reduce with it. Finally, more advanced concepts like sharding and replication will be explained. Check it out here!
Table Of Contents
1. Introduction
Sharding is a technique used to split large amount of data across multiple server instances. Nowadays, data volumes are growing exponentially and a single physical server often is not able to store and manage such a mass. Sharding helps in solving such issues by dividing the whole data set into smaller parts and distributing them across large number of servers (or shards). Collectively, all shards make up a whole data set or, in terms of MongoDB , a single logical database.
2. Configuration
MongoDB supports sharding out of the box using sharded clusters configurations: config servers (three for production deployments), one or more shards (replica sets for production deployments), and one or more query routing processes.
- shards store the data: for high availability and data consistency reason, each shard should be a replica set (we will talk more about replication in Part 5. MongoDB Replication Guide)
- query routers (mongos processes) forward client applications and direct operations to the appropriate shard or shards (a sharded cluster can contain more than one query router to balance the load)
- config servers store the cluster’s metadata: mapping of the cluster’s data set to the shards (the query routers use this metadata to target operations to specific shards), for high availability the production sharded cluster should have 3 config servers but for testing purposes a cluster with a single config server may be deployed
MongoDB shards (partitions) data on a per-collection basis. The sharded collections in a sharded cluster should be accessed through the query routers (mongos processes) only. Direct connection to a shard gives access to only a fraction of the cluster’s data. Additionally, every database has a so called primary shard that holds all the unsharded collections in that database.
Config servers are special mongod process instances that store the metadata for a single sharded cluster. Each cluster must have its own config servers. Config servers use a two-phase commit protocol to ensure consistency and reliability. All config servers must be available to deploy a sharded cluster or to make any changes to cluster metadata. Clusters become inoperable without the cluster metadata.
3. Sharding (Partitioning) Schemes
MongoDB distributes data across shards at the collection level by partitioning a collection’s data by the shard key (for more details, please refer to official documentation).
Shard key is either an indexed simple or compound field that exists in every document in the collection. Using either range-based partitioning or hash-based partitioning, MongoDB splits the shard key values into chunks and distributes those chunks evenly across the shards. To do that, MongoDB uses two background processes:
- splitting: a background process that keeps chunks from growing too large. When a particular chunk grows beyond a specified chunk size (by default, 64 Mb), MongoDB splits the chunk in a half. Inserts and updates of the sharded collection may triggers splits.
- balancer: a background process that manages chunk migrations. The balancer runs on every query router in a cluster. When the distribution of a sharded collection in a cluster is uneven, the balancer moves chunks from the shard that has the largest number of chunks to the shard with the lowest number of chunks until balance is reached.
3.1. Range-based sharding (partitioning)
In range-base sharding (partitioning), MongoDB splits the data set into ranges determined by the shard key values. For example, if shard key is numeric field, MongoDB partitions the whole field’s value range into smaller, non-overlapping intervals (chunks).
Although range-based sharding (partitioning) supports more efficient range queries, it may result into uneven data distribution.
3.2. Hash-based sharding (partitioning)
In hash-based sharding (partitioning), MongoDB computes the hash value of the shard key and then uses these hashes to split the data between shards. Hash-based partitioning ensures an even distribution of data but leads to inefficient range queries.
4. Adding / Removing Shards
MongoDB allows adding and removing shards to/from running shared cluster. When new shards are added, it breaks the balance since the new shards have no chunks. While MongoDB begins migrating data to the new shards immediately, it can take a while before the cluster restores the balance.
Accordingly, when shards are being removed from the cluster, the balancer migrates all chunks from those shards to other shards. When migration is done, the shards can be safely removed.
5. Configuring Sharded Cluster
Now that we understand the MongoDB sharding basics, we are going to deploy a small sharded cluster from scratch using simplified (test-like) configuration without replica sets and single config server instance.
The deployment of sharded cluster begins with running mongod server process in a config server mode using the --configsvr command line argument. Each config server requires its own data directory to store a complete the cluster’s metadata and that should be provided using --dbpath command line argument (which we have already seen in Part 1. MongoDB Installation – How to install MongoDB). That being said, let us perform the following steps:
- Create a data folder (we need to do that only once):
mkdir configdb - Run MongoDB server:
bin/mongod --configsvr --dbpath configdb
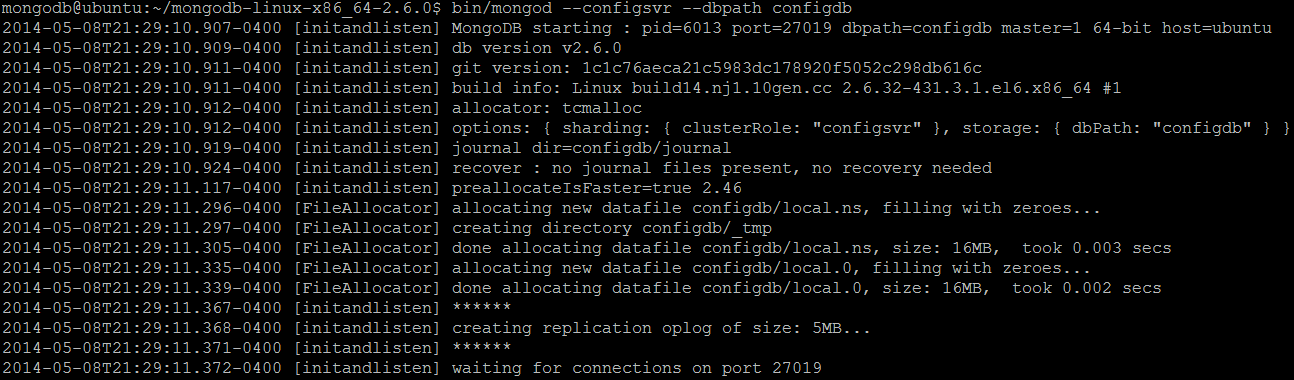
By default, config servers listen on a port 27019. All config servers should be up and running before starting up a sharded cluster. In our deployment, the single config server is run on a host with name ubuntu.
Next step is to run the instances of mongos processes. Those are lightweight and require only knowing the location of config servers. For that, the command line argument --configdb is being used followed by comma-separated config server names (in our case, only single config server on host ubuntu):
bin/mongos --configdb ubuntu
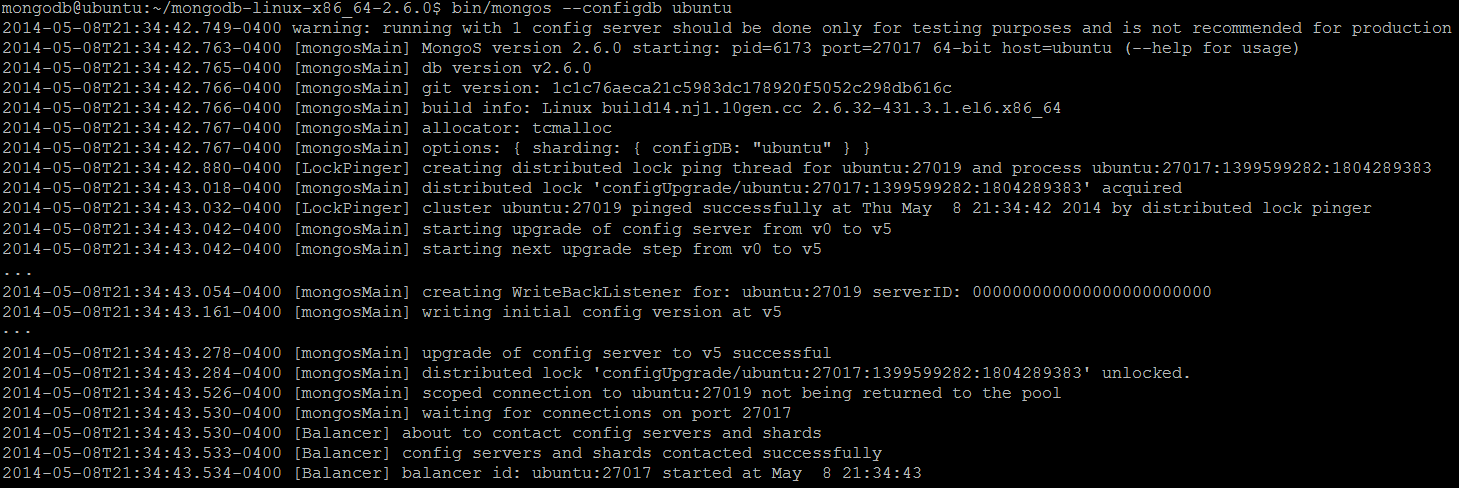
The default port mongos process listens to is 27017, the same as a usual MongoDB server.
The final step is to add some regular MongoDB server instances (shards) into the sharded cluster. Les us start two MongoDB server instances on different ports, 27000 and 27001 respectively.
- Run first MongoDB server instance (shard) on port 27000
mkdir data-shard1 bin/mongod --dbpath data-shard1 --port 27000
- Run second MongoDB server instance (shard) on port 27001
mkdir data-shard2 bin/mongod --dbpath data-shard2 --port 27001
Once the standalone MongoDB server instances are up and running, it is a time to add them into sharded cluster with the help of MongoDB shell. Up to now, we have used MongoDB shell to connect to standalone MongoDB servers. In sharded cluster, the mongos processesare the entry points for all clients and as such we are going to connect to the one we have just run (running on default port 27017): bin/mongo --port 27017 --host ubuntu

MongoDB shell provides a useful command sh.addShard() for adding shards (please refer to Shell Sharding Command Helpers for more details). Let us issue this command against the two standalone MongoDB server instances we have run before:
sh.addShard( "ubuntu:27000" ) sh.addShard( "ubuntu:27001" )

Let us check the current sharded cluster configuration by issuing another very helpful MongoDB shell command sh.status().
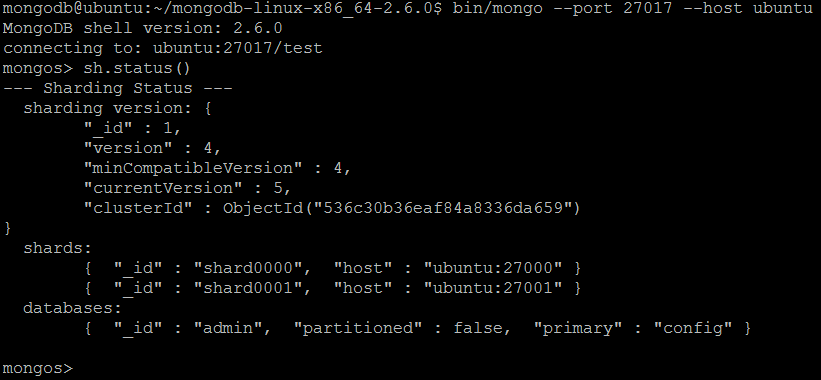
At this point the sharded cluster infrastructure is configured and we can move on with sharding database collections.
Shard tags
MongoDB allows to associate tags to specific ranges of a shard key with a specific shard or subset of shards. A single shard may have multiple tags, and multiple shards may also have the same tag. But any given shard key range may only have one assigned tag. The overlapping of the ranges is not allowed as well as tagging the same range more than once.
For example, let us assign tags to each of the shards in our sharded cluster by using sh.addShardTag() command.
sh.addShardTag( "shard0001", "bestsellers" ) sh.addShardTag( "shard0000", "others" )
To find all shards associated with a particular tag, the command against config database should be issued. For example, to find all shards tagged as “bestsellers” the following commands should be typed in MongoDB shell:
use config
db.shards.find( { tags: "bestsellers" } )
Another collection in config database named tags contains all tags definitions and may be queried the regular way for all available tags.
Respectively, tags could be removed from the shard using the sh.removeShardTag()command. For example:
sh.removeShardTag( "shard0000", "others" )
6. Sharding databases and collections
As we already know, MongoDB performs sharding on collection level. But before a collection could be sharded, the sharding must be enabled for the collection’s database. Enabling sharding for a database does not redistribute data but makes it possible to shard the collections in that database.
For demonstration purposes, we are going to reuse the bookstore example from Part 3. MongoDB and Java Tutorial and make the books collection shardable. Let us reconnect to mongos instance by providing additionally the database name bin/mongo --port 27017 --host ubuntu bookstore(or just issue the command use bookstorein the existing MongoDB shell session) and insert couple of documents into the books collection.
db.books.insert( {
"title" : "MongoDB: The Definitive Guide",
"published" : "2013-05-23",
"categories" : [ "Databases", "NoSQL", "Programming" ],
"publisher" : { "name" : "O'Reilly" }
} )
db.books.insert( {
"title" : "MongoDB Applied Design Patterns",
"published" : "2013-03-19",
"categories" : [ "Databases", "NoSQL", "Patterns", "Programming" ],
"publisher" : { "name" : "O'Reilly" }
} )
db.books.insert( {
"title" : "MongoDB in Action",
"published" : "2011-12-16",
"categories" : [ "Databases", "NoSQL", "Programming" ],
"publisher" : { "name" : "Manning" }
} )
db.books.insert( {
"title" : "NoSQL Distilled: A Brief Guide to the Emerging World of Polyglot Persistence",
"published" : "2012-08-18",
"categories" : [ "Databases", "NoSQL" ],
"publisher" : { "name" : "Addison Wesley" }
} )As we mentioned before, sharding is not yet enabled nor for bookstore database nor for books collection so the whole dataset ends up on primary shard (as we mentioned in Introduction section). Let us enable sharding for bookstore database by issuing the command sh.enableSharding() in MongoDB shell.

We are getting very close to have our sharded cluster to actually do some work and to start sharding real collections. Each collection should have a shard key (please refer to Sharding (Partitioning) Schemes section) in order to be partitioned across multiple shards. Let us define a hash-based sharding key (please refer to Hash-based sharding (partitioning) section) for books collection based on document _id field.
db.books.ensureIndex( { "_id": "hashed" } )With that, let us tell MongoDB to shard the books collection using sh.shardCollection() command (please see Sharding commands and command helpers for more details).
sh.shardCollection( "bookstore.books", { "_id": "hashed" } )
And with that, the sharded cluster is up and running! In the next section we are going to look closely on the commands available specifically to manage sharded deployments.
7. Sharding commands and command helpers
MongoDB shell provides a command helpers and sh context variable to simplify sharding management and deployment.
| Command | listShards |
| Description | Outputs a list of configured shards. It should be run in context of admin database. |
| Example | In MongoDB shell, let us issue the command:db.adminCommand( { listShards: 1 } )
|
| Reference | http://docs.mongodb.org/manual/reference/command/listShards/ |
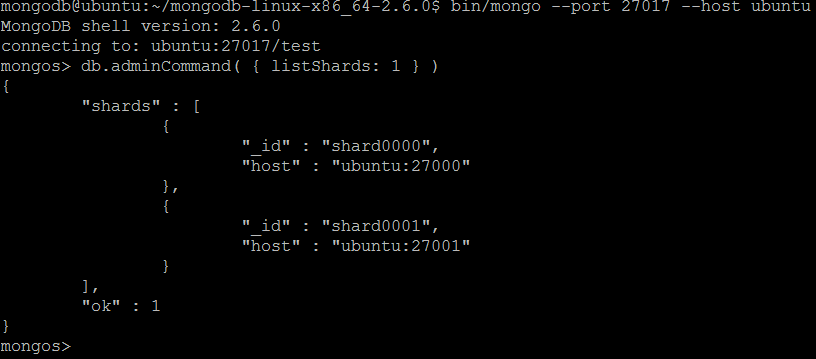
listShards
| Command | shardConnPoolStats |
| Description | Reports statistics on the pooled and cached connections in the sharded connection pool. |
| Example | In MongoDB shell, let us issue the command:db.runCommand( { shardConnPoolStats: 1 } )
|
| Reference | http://docs.mongodb.org/manual/reference/command/shardConnPoolStats/ |
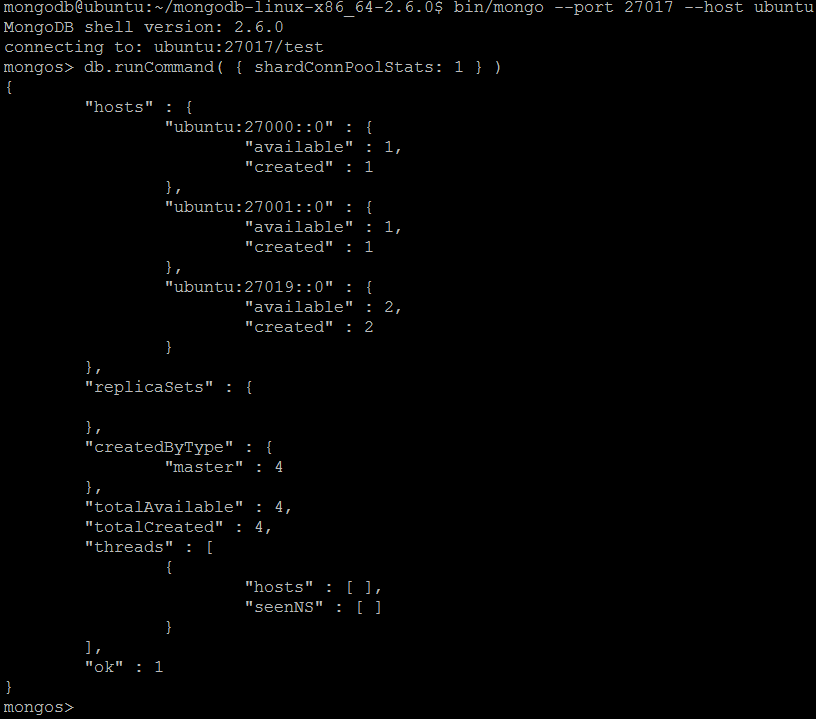
shardConnPoolStats
| Command | connPoolStats |
| Description | Reports statistics regarding the number of open connections to the current database instance, including client connections and server-to-server connections for replication and clustering. |
| Example | In MongoDB shell, let us issue the command:db.runCommand( { connPoolStats: 1 } )
|
| Reference | http://docs.mongodb.org/manual/reference/command/connPoolStats/ |
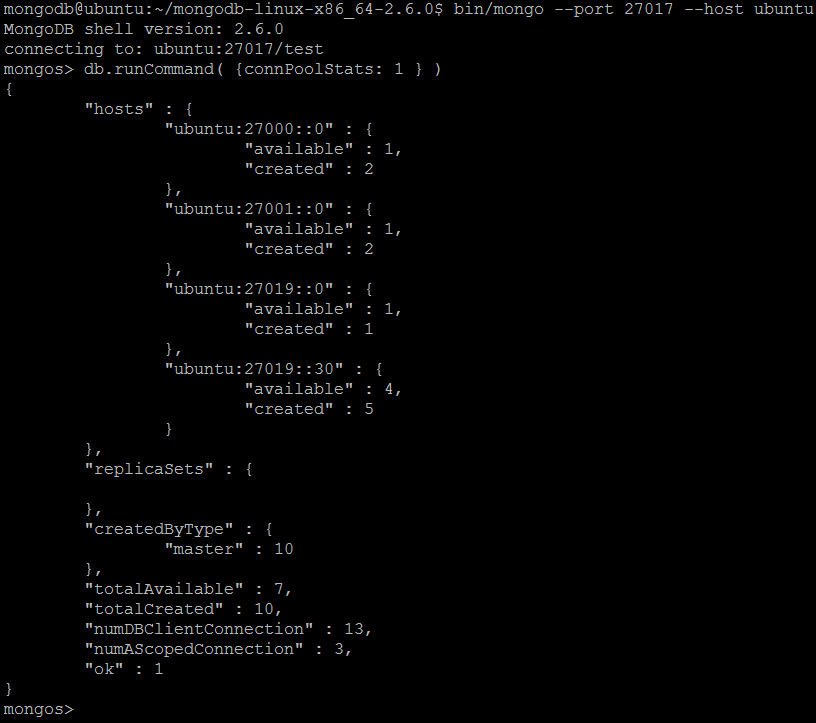
connPoolStats
| Command | isdbgrid |
| Description | This command verifies that a process MongoDB shell is connected to is a mongos. |
| Example | In MongoDB shell, let us issue the command:db.runCommand( { isdbgrid: 1 } )
|
| Reference | http://docs.mongodb.org/manual/reference/command/isdbgrid/ |

isdbgrid
| Command | flushRouterConfig |
| Description | Clears the current sharded cluster information cached by a mongos instance and reloads all sharded cluster metadata from the config database. It should be issued against mongos process instance and run in context of admin database. |
| Example | In MongoDB shell, let us issue the command:db.adminCommand( { flushRouterConfig: 1 } )
|
| Reference | http://docs.mongodb.org/manual/reference/command/flushRouterConfig/ |

flushRouterConfig
| Command | shardingState |
| Description | Reports if the current instance of MongoDB server is a member of a sharded cluster. It should be run in context of admin database. |
| Example | Let us connect to any of the standalone MongoDB server instances using MongoDB shell:bin/mongo --port 27001 And issue the command: db.adminCommand( { shardingState: 1 } )
|
| Reference | http://docs.mongodb.org/manual/reference/command/shardingState/ |
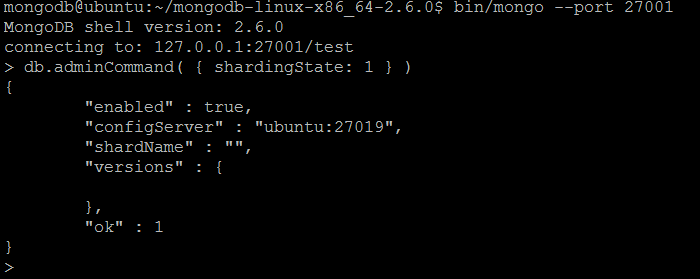
shardingState
| Command | movePrimary |
| Parameters | {
movePrimary : <database>,
to : <shard name>
}
|
| Description | The command reassigns the database’s primary shard, which holds all unsharded collections in the database, to another shard in the sharded cluster. It should be issued against mongos process instance and run in context of admin database. |
| Example | In MongoDB shell, let us issue the command:db.adminCommand
( { movePrimary : "test", to : "shard0001" } )
|
| Reference | http://docs.mongodb.org/manual/reference/command/movePrimary/ |

movePrimary
| Command | sh.help() |
| Description | Outputs the brief description for all sharding-related shell functions. |
| Example | In MongoDB shell, let us issue the command:sh.help()
|
| Reference | http://docs.mongodb.org/manual/reference/method/sh.help/ |
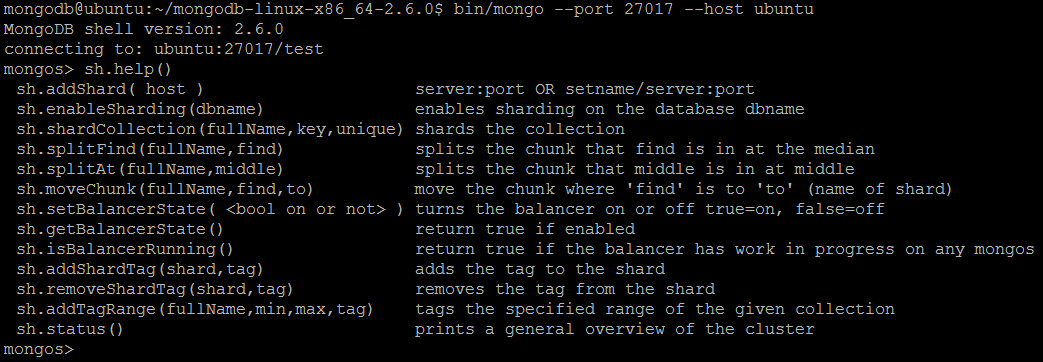
sh.help()
| Command | addShard |
| Parameters | {
addShard: <hostname><:port>,
maxSize: <size>,
name: <shard_name>
}
|
| Wrapper | sh.addShard(<host>) |
| Description | The command adds either a database instance or a replica set to a sharded cluster. It should be issues against mongos process instance. |
| Example | See please Configuring Sharded Cluster section. |
| Reference | http://docs.mongodb.org/manual/reference/command/addShard/ http://docs.mongodb.org/manual/reference/method/sh.addShard/ |
addShard
| Command | db.printShardingStatus() |
| Description | The command outputs a formatted report of the sharding configuration and the information regarding existing chunks in a sharded cluster. The default behavior suppresses the detailed chunk information if the total number of chunks is greater than or equal to 20. |
| Example | See please Configuring Sharded Cluster section. |
| Reference | http://docs.mongodb.org/manual/reference/method/sh.status/ |
db.printShardingStatus()
sh.status()
| Command | enableSharding |
| Parameters | {
enableSharding: <database>
}
|
| Wrapper | sh.enableSharding(database) |
| Description | Enables sharding on the specified database. It does not automatically shard any collections but makes it possible to begin sharding collections using sh.shardCollection() command. |
| Example | See please Sharding databases and collections section. |
| Reference | http://docs.mongodb.org/manual/reference/command/enableSharding/ http://docs.mongodb.org/manual/reference/method/sh.enableSharding/ |
enableSharding
| Command | shardCollection |
| Parameters | {
shardCollection: <database>.<collection>,
key: <shardkey>
} |
| Wrapper | sh.shardCollection(namespace, key, unique) |
| Description | The command enables sharding for a collection and allows MongoDB to begin distributing data among shards. Before issuing this command, the sharding should be enabled on database level using sh.enableSharding() command. |
| Example | See please Sharding databases and collections section. |
| Reference | http://docs.mongodb.org/manual/reference/command/shardCollection/ http://docs.mongodb.org/manual/reference/method/sh.shardCollection/ |
shardCollection
| Command | sh.getBalancerHost() |
| Description | The command returns the name of a mongos responsible for the balancer process. |
| Example | In MongoDB shell, let us issue the command:sh.getBalancerHost()
|
| Reference | http://docs.mongodb.org/manual/reference/method/sh.getBalancerHost/ |

sh.getBalancerHost()
| Command | sh.getBalancerState() |
| Description | The command returns true when the balancer is enabled and false if the balancer is disabled. |
| Example | In MongoDB shell, let us issue the command:sh.getBalancerState()
|
| Reference | http://docs.mongodb.org/manual/reference/method/sh.getBalancerState/ |

sh.getBalancerState()
| Command | sh.isBalancerRunning() |
| Description | The command returns true if the balancer process is currently running and migrating chunks and false if the balancer process is not running. |
| Example | In MongoDB shell, let us issue the command:sh.isBalancerRunning()
|
| Reference | http://docs.mongodb.org/manual/reference/method/sh.isBalancerRunning/ |

sh.isBalancerRunning()
| Command | setBalancerState (true | false) |
| Description | The command enables or disables the balancer in the sharded cluster. |
| Example | In MongoDB shell, let us issue the command:sh.setBalancerState(false)
|
| Reference | http://docs.mongodb.org/manual/reference/method/sh.disableBalancing/ |

setBalancerState (true | false)
| Command | sh.startBalancer(timeout, interval) |
| Description | The command enables the balancer in a sharded cluster and waits for balancing to start. |
| Example | In MongoDB shell, let us issue the command:sh.startBalancer(5000, 100)
|
| Reference | http://docs.mongodb.org/manual/reference/method/sh.startBalancer/ |

sh.startBalancer(timeout, interval)
| Command | sh.stopBalancer(timeout, interval) |
| Description | The command disables the balancer in a sharded cluster and waits for balancing to finish. |
| Example | In MongoDB shell, let us issue the command:sh.stopBalancer(5000, 100)
|
| Reference | http://docs.mongodb.org/manual/reference/method/sh.stopBalancer/ |

sh.stopBalancer(timeout, interval)
| Command | db.<collection>.getShardDistribution() |
| Description | Outputs the data distribution statistics for a sharded collection in the sharded cluster. |
| Example | In MongoDB shell, let us issue the commands:use bookstore db.books.getShardDistribution()
|
| Reference | http://docs.mongodb.org/manual/reference/method/db.collection.getShardDistribution/ |
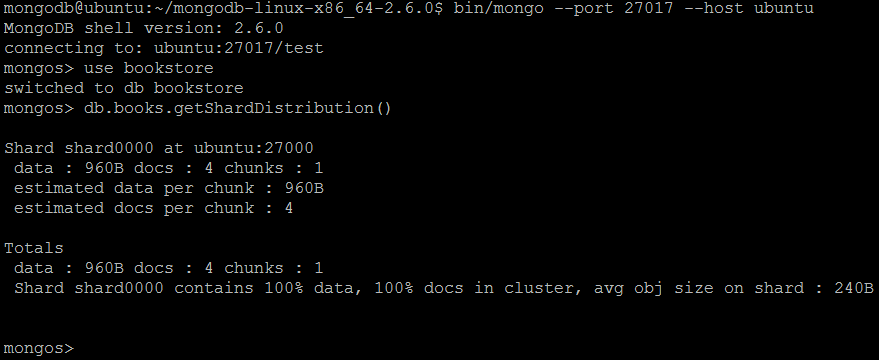
db..getShardDistribution()
| Command | removeShard |
| Parameters | {
removeShard: <shard name>
} |
| Description | The command removes a shard from a sharded cluster. Upon run, MongoDB moves the shard’s chunks to other shards in the cluster and only than removes the shard. It should be run in context of admin database. |
| Example | In MongoDB shell, let us issue the command:db.adminCommand( { removeShard: "shard0002" } )
|
| Reference | http://docs.mongodb.org/manual/reference/command/removeShard/ |
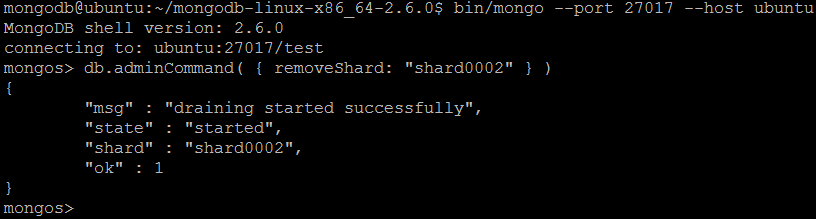
removeShard
| Command | mergeChunks |
| Parameters | {
mergeChunks : <database>.<collection> ,
bounds : [
{ <shardKeyField>: <minFieldValue> },
{ <shardKeyField>: <maxFieldValue> }
]
} |
| Description | The command combines two contiguous chunk ranges the same shard into a single chunk. At least one of chunk must not have any documents. The command should be issued against mongos instance and run in context of admin database. |
| Reference | http://docs.mongodb.org/manual/reference/command/mergeChunks/ |
mergeChunks
| Command | split |
| Parameters | {
split: <database>.<collection>,
<find|middle|bounds>
} |
| Wrapper | sh.splitAt(namespace, query) sh.splitFind(namespace, query) |
| Description | The command manually splits a chunk in a sharded cluster into two chunks. The command should be run in context of admin database. |
| Example | In MongoDB shell, let us issue the command: db.adminCommand( { split: “bookstore.books”, find: { “title”: “MongoDB in action” } } )
Alternatively, let us run the same command using command wrapper: sh.splitFind( “bookstore.books”, { “title”: “MongoDB in action” } ) |
| Reference | http://docs.mongodb.org/manual/reference/command/split/ http://docs.mongodb.org/manual/reference/method/sh.splitAt/ http://docs.mongodb.org/manual/reference/method/sh.splitFind/ |

split
| Command | sh.moveChunk(namespace, query, shard name) |
| Description | The command moves the chunk that contains the document specified by the query to another shard with name shard name. |
| Example | In MongoDB shell, let us issue the commands:use bookstore sh.moveChunk( "bookstore.books",
{ "title": "MongoDB in action" }, "shard0001" )db.books.getShardDistribution()
|
| Reference | http://docs.mongodb.org/manual/reference/method/sh.moveChunk/ |
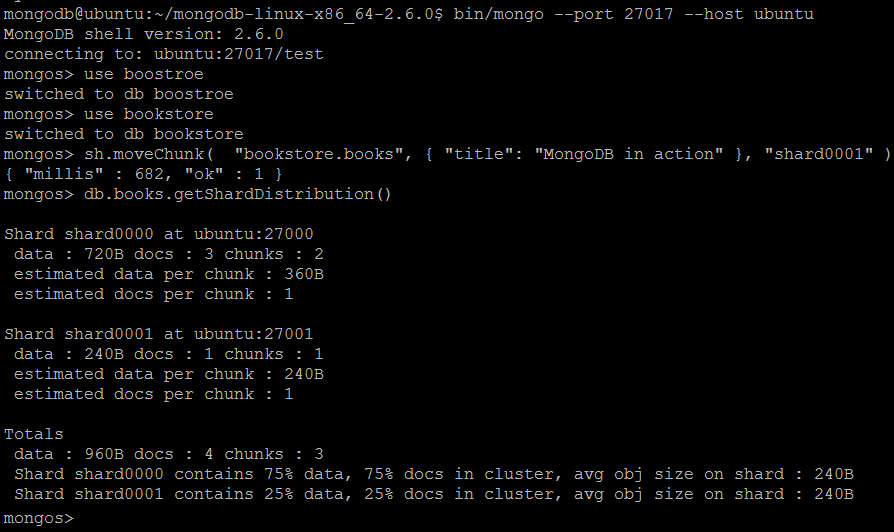
sh.moveChunk(namespace, query, shard name)
| Command | sh.addShardTag(shard, tag) |
| Description | The command associates a shard with a tag or identifier. MongoDB uses these identifiers to direct chunks that fall within a tagged range to specific shards. |
| Example | See please Shard tags section. |
| Reference | http://docs.mongodb.org/manual/reference/method/sh.addShardTag/ |
sh.addShardTag(shard, tag)
| Command | sh.addTagRange(namespace, minimum, maximum, tag) |
| Description | The command attaches a range of shard key values to a shard tag created previously using the sh.addShardTag() command. |
| Example | See please Shard tags section. |
| Reference | http://docs.mongodb.org/manual/reference/method/sh.addTagRange/ |
sh.addTagRange(namespace, minimum, maximum, tag)
| Command | sh.removeShardTag(shard, tag) |
| Description | The command removes the association between a tag and a shard. The command should be issued against mongos instance |
| Example | See please Shard tags section. |
| Reference | http://docs.mongodb.org/manual/reference/method/sh.removeShardTag/ |
sh.removeShardTag(shard, tag)
8. What’s next
In this part we have covered basics of MongoDB sharding (partitioning) capabilities. For more complete and comprehensive details please refer to official documentation. In the next section we are going to take a look on MongoDB replication.
