 In this blog post, I will explain the resource allocation configurations for Spark on YARN, describe the yarn-client and yarn-cluster modes, and will include examples.
In this blog post, I will explain the resource allocation configurations for Spark on YARN, describe the yarn-client and yarn-cluster modes, and will include examples.
Spark can request two resources in YARN: CPU and memory. Note that Spark configurations for resource allocation are set in spark-defaults.conf, with a name like spark.xx.xx. Some of the them have a corresponding flag for client tools such as spark-submit/spark-shell/pyspark, with a name like –xx-xx. If the configuration has a corresponding flag for client tools, you need to put the flag after the configurations in parenthesis”()”. For example:
spark.driver.cores (--driver-cores)
1. yarn-client vs. yarn-cluster mode
There are two deploy modes that can be used to launch Spark applications on YARN:
Per Spark documentation:
- In yarn-client mode, the driver runs in the client process, and the application master is only used for requesting resources from YARN.
- In yarn-cluster mode, the Spark driver runs inside an application master process which is managed by YARN on the cluster, and the client can go away after initiating the application.
2. Application Master (AM)
a. yarn-client
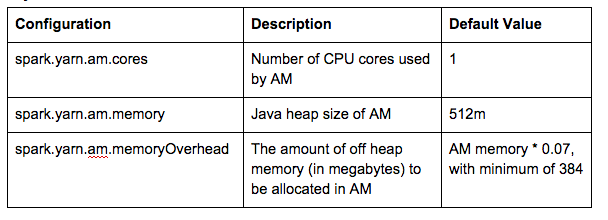
Let’s look at the settings below as an example:
[root@h1 conf]# cat spark-defaults.conf |grep am spark.yarn.am.cores 4 spark.yarn.am.memory 777m
By default, spark.yarn.am.memoryOverhead is AM memory * 0.07, with a minimum of 384. This means that if we set spark.yarn.am.memory to 777M, the actual AM container size would be 2G. This is because 777+Min(384, 777 * 0.07) = 777+384 = 1161, and the default yarn.scheduler.minimum-allocation-mb=1024, so 2GB container will be allocated to AM. As a result, a (2G, 4 Cores) AM container with Java heap size -Xmx777M is allocated:
Assigned container container_1432752481069_0129_01_000001 of capacity
<memory:2048, vCores:4, disks:0.0>
b. yarn-cluster
In yarn-cluster mode, the Spark driver is inside the YARN AM. The driver-related configurations listed below also control the resource allocation for AM.
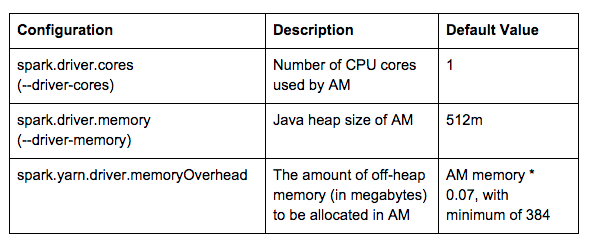
Take a look at the settings below as an example:
MASTER=yarn-cluster /opt/mapr/spark/spark-1.3.1/bin/spark-submit --class org.apache.spark.examples.SparkPi \ --driver-memory 1665m \ --driver-cores 2 \ /opt/mapr/spark/spark-1.3.1/lib/spark-examples*.jar 1000
Since 1665+Min(384,1665*0.07)=1665+384=2049 > 2048(2G), a 3G container will be allocated to AM. As a result, a (3G, 2 Cores) AM container with Java heap size -Xmx1665M is allocated:
Assigned container container_1432752481069_0135_02_000001 of capacity:
<memory:3072, vCores:2, disks:0.0>
3. Containers for Spark executors
For Spark executor resources, yarn-client and yarn-cluster modes use the same configurations:
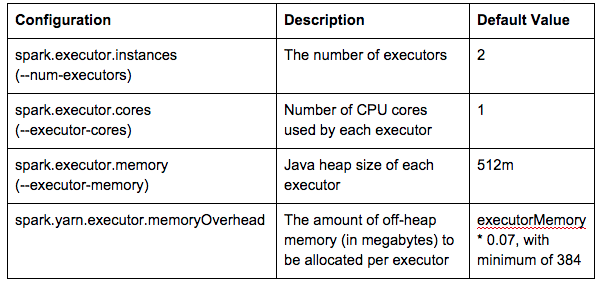
In spark-defaults.conf, spark.executor.memory is set to 2g.
Spark will start 2 (3G, 1 core) executor containers with Java heap size -Xmx2048M: Assigned container container_1432752481069_0140_01_000002 of capacity:
<memory:3072, vCores:1, disks:0.0>
Assigned container container_1432752481069_0140_01_000003 of capacity:
<memory:3072, vCores:1, disks:0.0>
However, one core per executor means only one task can be running at any time for one executor. In the case of a broadcast join, the memory can be shared by multiple running tasks in the same executor if we increase the number of cores per executor.
Note that if dynamic resource allocation is enabled by setting spark.dynamicAllocation.enabled to true, Spark can scale the number of executors registered with this application up and down based on the workload. In this case, you do not need to specify spark.executor.instances manually.
Key takeaways
- Spark driver resource related configurations also control the YARN application master resource in yarn-cluster mode.
- Be aware of the max (7%, 384m) overhead off-heap memory when calculating the memory for executors.
- The number of CPU cores per executor controls the number of concurrent tasks per executor.
In this blog post, you’ve learned about resource allocation configurations for Spark on YARN. If you have any further questions, please ask them in the comments section below.
| Reference: | Resource Allocation Configuration for Spark on YARN from our JCG partner Hao Zhu at the Mapr blog. |
