I’ve worked for Spark backend of Apache Gora as my GSoC 2015 project and finished it. At this blog post, I’ll explain how it works and how to use it. First of all, I suggest you to read my previous posts about my GSoC 2015 acceptance: http://furkankamaci.com/gsoc-2015-acceptance-for-apache-gora/ and Apache Gora: http://www.javacodegeeks.com/2015/08/in-memory-data-model-and-persistence-for-big-data.html if you haven’t read them.
Apache Gora provides an in-memory data model and persistence for big data. Gora supports persisting to column stores, key value stores, document stores and RDBMSs, and analyzing the data with extensive Apache Hadoop MapReduce support. Roughly, Gora is a powerful project which can work like Hibernate of NoSQL world and one can run Map/Reduce jobs on it. Even Spark is so powerful compared to Map/Reduce which Gora currently supports; there was no Spark backend for Gora and my GSoC project is aimed that.
I’ll follow a log analytics example to explain Spark backend implementation during my post. It will use Apache server logs which is persisted at a data store. I suggest you download and compile Gora source code (https://github.com/apache/gora) and read Gora tutorial (http://gora.apache.org/current/tutorial.html) to find and persist example log. You can use its built-in scripts at Gora to persist example data.
Due to we are using Apache Gora, we can either use Hbase, Solr, MongoDB or etc. (for a full list: http://gora.apache.org/) as a data store. Gora will run your code independent of which data store you are using. At this example, I’ll persist an example set of Apache server logs into Hbase (version: 1.0.1.1), I’ll read them from there, run Spark codes on it and write result into Solr (version: 4.10.3).
Firstly, startup a data store to read value from. I’ll start Hbase as a persistence data store:
1 2 | furkan@kamaci:~/apps/hbase-1.0.1.1$ ./bin/start-hbase.shstarting master, logging to /home/furkan/apps/hbase-1.0.1.1/bin/../logs/hbase-furkan-master-kamaci.out |
Persist example logs into Hbase (you should have extracted access.log.tar.gz before this command):
1 | furkan@kamaci:~/projects/gora$ ./bin/gora logmanager -parse gora-tutorial/src/main/resources/access.log |
After running parse command, run shell command of hbase:
1 2 3 4 5 | furkan@kamaci:~/apps/hbase-1.0.1.1$ ./bin/hbase shell2015-08-31 00:20:16,026 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableHBase Shell; enter 'help<RETURN>' for list of supported commands.Type "exit<RETURN>" to leave the HBase ShellVersion 1.0.1.1, re1dbf4df30d214fca14908df71d038081577ea46, Sun May 17 12:34:26 PDT 2015 |
and run list command. You should see the output below if there were not any tables at your Hbase before:
1 2 3 4 5 | hbase(main):025:0> listTABLEAccessLog1 row(s) in 0.0150 seconds=> ["AccessLog"] |
Check whether any data exists at table:
01 02 03 04 05 06 07 08 09 10 11 | hbase(main):026:0> scan 'AccessLog', {LIMIT=>1}ROW COLUMN+CELL\x00\x00\x00\x00\x00\x00\x00\x00 column=common:ip, timestamp=1440970360966, value=88.240.129.183\x00\x00\x00\x00\x00\x00\x00\x00 column=common:timestamp, timestamp=1440970360966, value=\x00\x00\x01\x1F\xF1\xAElP\x00\x00\x00\x00\x00\x00\x00\x00 column=common:url, timestamp=1440970360966, value=/index.php?a=1__wwv40pdxdpo&k=218978\x00\x00\x00\x00\x00\x00\x00\x00 column=http:httpMethod, timestamp=1440970360966, value=GET\x00\x00\x00\x00\x00\x00\x00\x00 column=http:httpStatusCode, timestamp=1440970360966, value=\x00\x00\x00\xC8\x00\x00\x00\x00\x00\x00\x00\x00 column=http:responseSize, timestamp=1440970360966, value=\x00\x00\x00+\x00\x00\x00\x00\x00\x00\x00\x00 column=misc:referrer, timestamp=1440970360966, value=http://www.buldinle.com/index.php?a=1__WWV40pdxdpo&k=218978\x00\x00\x00\x00\x00\x00\x00\x00 column=misc:userAgent, timestamp=1440970360966, value=Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)1 row(s) in 0.0810 seconds |
To write result into Solr, create a schemaless core named as Metrics. To do it easily, you can rename default core of collection1 to Metrics which is at solr-4.10.3/example/example-schemaless/solr folder and edit /home/furkan/Desktop/solr-4.10.3/example/example-schemaless/solr/Metrics/core.properties as:
1 | name=Metrics |
Then run start command for Solr:
1 | furkan@kamaci:~/Desktop/solr-4.10.3/example$ java -Dsolr.solr.home=example-schemaless/solr/ -jar start.jar |
Let’s start the example. Read data from Hbase, generate some metrics and write results into Solr with Spark via Gora. Here is how to initialize in and out data stores:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 | public int run(String[] args) throws Exception {DataStore<Long, Pageview> inStore;DataStore<String, MetricDatum> outStore;Configuration hadoopConf = new Configuration();if (args.length > 0) {String dataStoreClass = args[0];inStore = DataStoreFactory.getDataStore(dataStoreClass, Long.class, Pageview.class, hadoopConf);if (args.length > 1) {dataStoreClass = args[1];}outStore = DataStoreFactory.getDataStore(dataStoreClass, String.class, MetricDatum.class, hadoopConf);} else {inStore = DataStoreFactory.getDataStore(Long.class, Pageview.class, hadoopConf);outStore = DataStoreFactory.getDataStore(String.class, MetricDatum.class, hadoopConf);}...} |
Pass input data store’s key and value classes and instantiate a GoraSparkEngine:
1 2 | GoraSparkEngine<Long, Pageview> goraSparkEngine = new GoraSparkEngine<>(Long.class,Pageview.class); |
Construct a JavaSparkContext. Register input data store’s value class as Kryo class:
1 2 3 4 5 6 | SparkConf sparkConf = new SparkConf().setAppName("Gora Spark Integration Application").setMaster("local");Class[] c = new Class[1];c[0] = inStore.getPersistentClass();sparkConf.registerKryoClasses(c);JavaSparkContext sc = new JavaSparkContext(sparkConf); |
You can get JavaPairRDD from input data store:
1 | JavaPairRDD<Long, Pageview> goraRDD = goraSparkEngine.initialize(sc, inStore); |
When you get it, you can work on it as like you are writing a code for Spark! For example:
1 2 | long count = goraRDD.count();System.out.println("Total Log Count: " + count); |
Here is my functions for map and reduce phases for this example:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 | /** The number of milliseconds in a day */private static final long DAY_MILIS = 1000 * 60 * 60 * 24;/*** map function used in calculation*/private static Function<Pageview, Tuple2<Tuple2<String, Long>, Long>> mapFunc = new Function<Pageview, Tuple2<Tuple2<String, Long>, Long>>() {@Overridepublic Tuple2<Tuple2<String, Long>, Long> call(Pageview pageview)throws Exception {String url = pageview.getUrl().toString();Long day = getDay(pageview.getTimestamp());Tuple2<String, Long> keyTuple = new Tuple2<>(url, day);return new Tuple2<>(keyTuple, 1L);}}; |
1 2 3 4 5 6 7 8 9 | /*** reduce function used in calculation*/private static Function2<Long, Long, Long> redFunc = new Function2<Long, Long, Long>() {@Overridepublic Long call(Long aLong, Long aLong2) throws Exception {return aLong + aLong2;}}; |
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 | /*** metric function used after map phase*/private static PairFunction<Tuple2<Tuple2<String, Long>, Long>, String, MetricDatum> metricFunc = new PairFunction<Tuple2<Tuple2<String, Long>, Long>, String, MetricDatum>() {@Overridepublic Tuple2<String, MetricDatum> call(Tuple2<Tuple2<String, Long>, Long> tuple2LongTuple2) throws Exception {String dimension = tuple2LongTuple2._1()._1();long timestamp = tuple2LongTuple2._1()._2();MetricDatum metricDatum = new MetricDatum();metricDatum.setMetricDimension(dimension);metricDatum.setTimestamp(timestamp);String key = metricDatum.getMetricDimension().toString();key += "_" + Long.toString(timestamp);metricDatum.setMetric(tuple2LongTuple2._2());return new Tuple2<>(key, metricDatum);}}; |
1 2 3 4 5 6 7 | /*** Rolls up the given timestamp to the day cardinality, so that data can be* aggregated daily*/private static long getDay(long timeStamp) {return (timeStamp / DAY_MILIS) * DAY_MILIS;} |
Here is how to run map and reduce functions at existing JavaPairRDD:
1 2 3 4 | JavaRDD<Tuple2<Tuple2<String, Long>, Long>> mappedGoraRdd = goraRDD.values().map(mapFunc);JavaPairRDD<String, MetricDatum> reducedGoraRdd = JavaPairRDD.fromJavaRDD(mappedGoraRdd).reduceByKey(redFunc).mapToPair(metricFunc); |
When you want to persist result into output data store, (in our example it is Solr), you should do it as follows:
1 2 | Configuration sparkHadoopConf = goraSparkEngine.generateOutputConf(outStore);reducedGoraRdd.saveAsNewAPIHadoopDataset(sparkHadoopConf); |
That’s all! Check Solr to see the results:
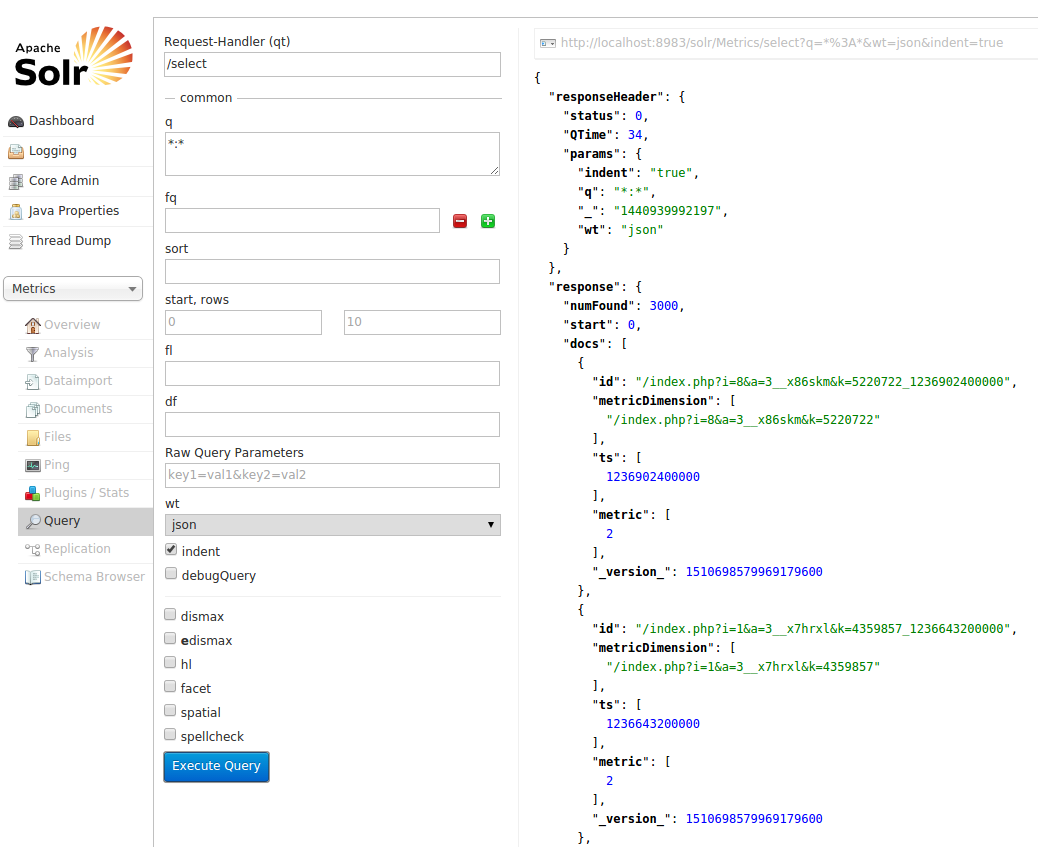
You can see that one can read data from a data store (i.e. Hbase), run Spark codes on it (map/reduce) and write results into same or another data store (i.e. Solr). GoraSparkEngine gives a Spark backend capability to Apache Gora and I think that it will make Gora much more powerful.
| Reference: | Spark Backend for Apache Gora from our JCG partner Furkan Kamaci at the FURKAN KAMACI blog. |
