If you have experience of business application development, then most likely you will have encountered a requirement for the application to have a flexible reporting mechanism. The company I work for is mainly focused on developing business solutions and reporting is an essential, indeed, must have aspect of all the enterprise systems we develop. To enable flexible reporting in our systems, we have developed our own open-source (distributed under Apache 2.0 license) report generator – YARG (Yet Another Report Generator). Now YARG is a heart of the reporting in the CUBA platform – which itself is the basis of all the systems we develop.
Why is There a Need to Develop a New One
First of all, let me remark that we are not wheel reinventors. We are always looking for solutions to integrate with, as long as those solutions fit us. Unfortunately, in this case we couldn’t find any open source tool that met the following requirements we identified:
- Generate report in template format and/or convert the output to PDF
- Avoid use of external tools for report template creation (Microsoft Office or Libreoffice should be enough)
- Support various formats of templates: DOC, ODT, XLS, DOCX, XLSX, HTML
- Ability to use complex XLS and XLSX templates with charts, formulas and etc.
- Ability to use HTML layout and insert/embed images
- Split out data layer (report structure and data fetching) and presentation layer (report templates)
- Enable various methods of data fetching such as SQL, JPQL or Groovy script
- Ability to be integrated with IoC frameworks (Spring, Guice)
- Functionality to use the tool as a standalone application, to be able to use it b?yond of the Java ecosystem (e.g. to generate reports using PHP)
- Store report structure in a transparent XML format
The closest tool we could find was JasperReports, but there were a few blockers which stopped us from using it:
- The free version could not generate DOC reports (there was a commercial library which provided this functionality)
- XLS reports were very limited, and it was not possible to use charts, formulas and cell formatting
- To create a report, it is necessary to have a certain skillset and knowledge of how to use very specific tools (e.g. iReports)
- There is no clear separation between data and presentation layers
Of course we researched lots of other different tools, but all other libraries we found were focused on some specific format. We wanted to have a panacea for reporting – one tool for all kind of reports.
Taking in consideration all the points and thoughts listed above, we decided to develop another, but bespoke tool for report generation.
What’s Under the Hood
When we started YARG it was not a problem to find a library for XLS integration (POI-HSSF, JXLS, etc.). We decided to go for Apache POI as the most popular and well supported library.
The situation around DOC integration was completely the opposite. Only a very few options were available in the open-source market (POI-HWPF, COM and UNO Runtime). The POI-HWPF library was very limited in a number of ways and we did not consider it as a suitable option. We had to choose between COM and UNO Runtime, which is literally an API for the OpenOffice server side integration.
So, after deep investigation we decided to pick UNO Runtime, mainly because of the positive feedback from people who successfully employed it for systems coded in completely different languages, such as Python, Ruby, C#, etc.
While use of POI-HSSF was quite straightforward (except of charting), we faced a number of challenges integrating UNO Runtime:
- There is no clear API to work with tables
- Each time a report is generated, OpenOffice starts. Initially we used bootstrapconnector to manage OpenOffice processes, but later it became clear that in many cases it doesn’t kill the process after a report is generated. Thus, we had to re-implement the logic of OpenOffice start and shutdown (thanks to jodconverter developers, who pointed many good ideas on this matter)
- Also UNO Runtime (and OpenOffice Server itself) has significant problems with thread-safety and this can lead to the server freezing or terminating itself if an internal error occurs. To overcome this, we had to implement a mechanism to restart reports if the server fails, with an obvious detrimental consequence for performance
Later on, when the DOCX4J library became very mature and popular, we supported XLSX/DOCX. The main advantage of the DOCX4J library is that it provides the necessary low level access to the document structure (basically, you operate with XML). Another benefit of using DOCX4J is that it doesn’t require OpenOffice server integration for DOCX reports generation.
Also, there is an ability to use document with Freemarker markup as a report template. We usually use it to generate very custom reports as HTML and then convert the result to PDF.
Finally, YARG infrastructure is developed in an extendable way, so that experienced users can implement integration with any other template type by themselves.
Hello World Report
Let’s get to know YARG. The main idea of the report generator is to split out the data layer and presentation layer. The Data layer enables scripting or direct SQL querying to fetch the desired information and the presentation layer represents the markup of the fetched data.
All YARG reports consist of so-called ‘Bands’. A Band is something that links up data and presentation layers together. So, every band knows where to get the data from and where it is placed in the template.
For example, we want to print out all our employees to an Excel spreadsheet. We will need to create the ‘Staff’ band and define an SQL query to fetch the list of the employees:
1 | select name, surname, position from staff |
Java code
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 | ReportBuilder reportBuilder = new ReportBuilder();ReportTemplateBuilder reportTemplateBuilder = new ReportTemplateBuilder() .documentPath("/home/haulmont/templates/staff.xls") .documentName("staff.xls") .outputType(ReportOutputType.xls) .readFileFromPath();reportBuilder.template(reportTemplateBuilder.build());BandBuilder bandBuilder = new BandBuilder();ReportBand staff= bandBuilder.name("Staff") .query("Staff", "select name, surname, position from staff", "sql") .build();reportBuilder.band(staff);Report report = reportBuilder.build();Reporting reporting = new Reporting();reporting.setFormatterFactory(new DefaultFormatterFactory());reporting.setLoaderFactory( new DefaultLoaderFactory().setSqlDataLoader(new SqlDataLoader(datasource)));ReportOutputDocument reportOutputDocument = reporting.runReport( new RunParams(report), new FileOutputStream("/home/haulmont/reports/staff.xls")); |
The only thing left is to create the XLS template:

Here we go! Just run the program and enjoy the result!
Advanced Example without Java
Let’s assume we have a network of bookshops. There is a need to generate an XLS report showing the list of sold books, with reference to the bookshop where the books were sold. Moreover, we don’t have a Java developer, only a system administrator with the basic skill set of XML and SQL.
First of all we need to create an XLS template for the report:

As you can see, we define two named regions (corresponding to the bands): for shops (in blue) and for book instances (in white).
Now we have to fetch required data from the database:
1 2 3 4 5 6 | select shop.id as "id", shop.name as "name", shop.address as "address"from store shopselect book.author as "author", book.name as "name", book.price as "price", count(*) as "count"from book book where book.store_id = ${Shop.id} group by book.author, book.name, book.price |
Finally, we declare the bands structure of the report using XML:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | <?xml version="1.0" encoding="UTF-8"?><report name="report"> <templates> <template code="DEFAULT" documentName="bookstore.xls" documentPath="./test/sample/bookstore/bookstore.xls" outputType="xls" outputNamePattern="bookstore.xls"/> </templates> <rootBand name="Root" orientation="H"> <bands> <band name="Header" orientation="H"/> <band name="Shop" orientation="H"> <bands> <band name="Book" orientation="H"> <queries> <query name="Book" type="sql"> <script> select book.author as "author", book.name as "name", book.price as "price", count(*) as "count" from book where book.store_id = ${Shop.id} group by book.author, book.name, book.price </script> </query> </queries> </band> </bands> <queries> <query name="Shop" type="sql"> <script> select shop.id as "id", shop.name as "name", shop.address as "address" from store shop </script> </query> </queries> </band> </bands> <queries/> </rootBand></report> |
Let’s launch the report and have a look at the result (how to run a report is described below in Standalone section):
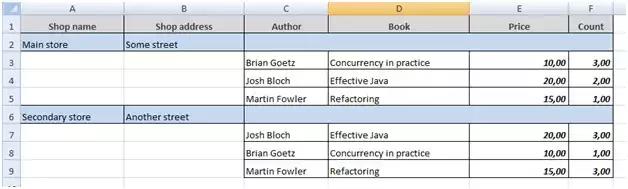
This use case shows that you can have a reference to the parent band: book.store_id = ${Shop.id}. This allowed us to filter the books sold by each particular bookshop.
One More Advanced Example
Let’s now create an invoice report. We will create a DOCX document and then convert to the immutable form – PDF document. To illustrate another way of how to load data, we will use groovy script, instead of the direct SQL query:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | <?xml version="1.0" encoding="UTF-8"?><report name="report"> <templates> <template code="DEFAULT" documentName="invoice.docx" documentPath="./test/sample/invoice/invoice.docx" outputType="pdf" outputNamePattern="invoice.pdf"/> </templates> <formats> <format name="Main.date" format="dd/MM/yyyy"/> <format name="Main.signature" format="${html}"/> </formats> <rootBand name="Root" orientation="H"> <bands> <band name="Main" orientation="H"> <queries> <query name="Main" type="groovy"> <script> return [ [ 'invoiceNumber':99987, 'client' : 'Google Inc.', 'date' : new Date(), 'addLine1': '1600 Amphitheatre Pkwy', 'addLine2': 'Mountain View, USA', 'addLine3':'CA 94043', 'signature':<![CDATA['<html><body><b><font color="red">Mr. Yarg</font></b></body></html>']]> ]] </script> </query> </queries> </band> <band name="Items" orientation="H"> <queries> <query name="Main" type="groovy"> <script> return [ ['name':'Java Concurrency in practice', 'price' : 15000], ['name':'Clear code', 'price' : 13000], ['name':'Scala in action', 'price' : 12000] ] </script> </query> </queries> </band> </bands> <queries/> </rootBand></report> |
As you may have noticed, Groovy script returns List<Map<String, Object>> object. So, each item is represented as a Key (parameter name) and Value (parameter value).
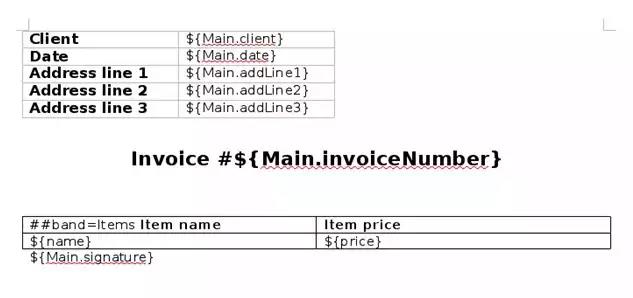
As a finishing touch we will need to create a DOCX template:
To link the bottom table to the list of of books we use ##band=Items marker.
After the report is generated we get the following output:

IoC Frameworks Integration
As mentioned before, one of the requirements was to provide an ability to integrate into IoC frameworks (Spring, Guice). We use YARG as a part of the powerful reporting engine in the CUBA platform – our high level Java framework for enterprise applications development. CUBA employs Spring as IoC mechanism, let’s have a look how YARG is integrated into the platform:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | <bean id="reporting_lib_Scripting" class="com.haulmont.reports.libintegration.ReportingScriptingImpl"/><bean id="reporting_lib_GroovyDataLoader" class="com.haulmont.yarg.loaders.impl.GroovyDataLoader"> <constructor-arg ref="reporting_lib_Scripting"/></bean><bean id="reporting_lib_SqlDataLoader" class="com.haulmont.yarg.loaders.impl.SqlDataLoader"> <constructor-arg ref="dataSource"/></bean><bean id="reporting_lib_JpqlDataLoader" class="com.haulmont.reports.libintegration.JpqlDataDataLoader"/><bean id="reporting_lib_OfficeIntegration" class="com.haulmont.reports.libintegration.CubaOfficeIntegration"> <constructor-arg value="${cuba.reporting.openoffice.path?:/}"/> <constructor-arg> <list> <value>8100</value> <value>8101</value> <value>8102</value> <value>8103</value> </list> </constructor-arg> <property name="displayDeviceAvailable"> <value>${cuba.reporting.displayDeviceAvailable?:false}</value> </property> <property name="timeoutInSeconds"> <value>${cuba.reporting.openoffice.docFormatterTimeout?:20}</value> </property></bean><bean id="reporting_lib_FormatterFactory" class="com.haulmont.yarg.formatters.factory.DefaultFormatterFactory"> <property name="officeIntegration" ref="reporting_lib_OfficeIntegration"/></bean><bean id="reporting_lib_LoaderFactory" class="com.haulmont.yarg.loaders.factory.DefaultLoaderFactory"> <property name="dataLoaders"> <map> <entry key="sql" value-ref="reporting_lib_SqlDataLoader"/> <entry key="groovy" value-ref="reporting_lib_GroovyDataLoader"/> <entry key="jpql" value-ref="reporting_lib_JpqlDataLoader"/> </map> </property></bean><bean id="reporting_lib_Reporting" class="com.haulmont.yarg.reporting.Reporting"> <property name="formatterFactory" ref="reporting_lib_FormatterFactory"/> <property name="loaderFactory" ref="reporting_lib_LoaderFactory"/></bean> |
In order to integrate YARG into Spring Framework the following beans should be registered:
reporting_lib_Reporting– provides an access to the core report generation functionality. The reporting_lib_FormatterFactory – manages the output to different formats (DOCX, XSLX, DOC, etc.)reporting_lib_LoaderFactory– provides the data load functionality (contains a number of beans corresponded to different sources)reporting_lib_OfficeIntegration– integrates report generator with the OpenOffice server (required for DOC and ODT reports generation)
As you can see YARG can be easily embedded within your application.
Standalone Use
Another valuable feature of YARG, is that it can be used as a standalone application. Technically, if you have JRE installed, you can run the report generator from the command prompt. For instance, if you have a server side PHP application and want to enable reporting in your application, then just create an XLS template, declare the report structure in XML and launch YARG from the command prompt:
1 | yarg -rp ~/report.xml -op ~/result.xls “-Pparam1=20/04/2014” |
More Features Available with the CUBA platform
YARG is deeply integrated into the CUBA platform and acts as the core engine for the powerful reporting mechanism implemented in the platform.
First of all, you can embed the reporting in one click using the CUBA Studio (read-only demo version is available here):
CUBA offers convenient user interface for reports management:
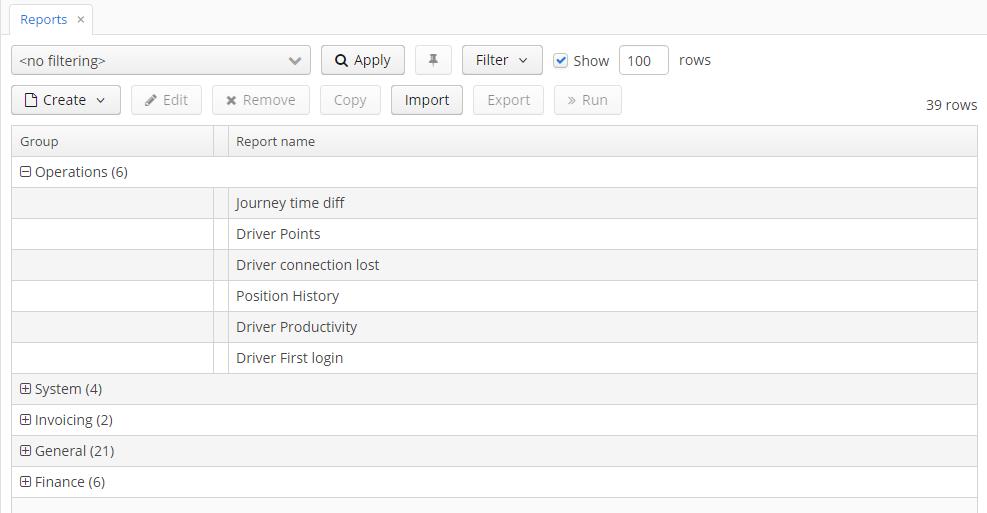
- Report browser with options to import/export and run a report.

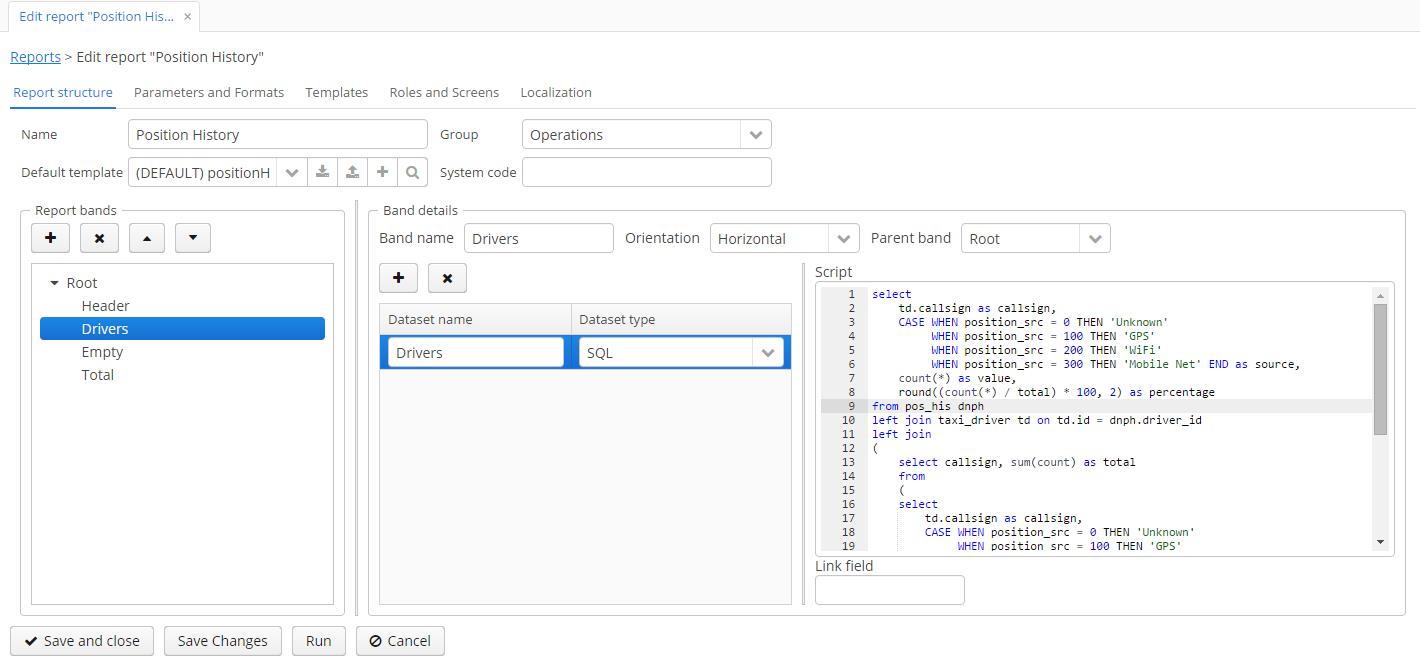
- The Report Editor allows you to create reports of any complexity (define bands, input parameters, manage templates, use Groovy, SQL, and JPQL to select the data):

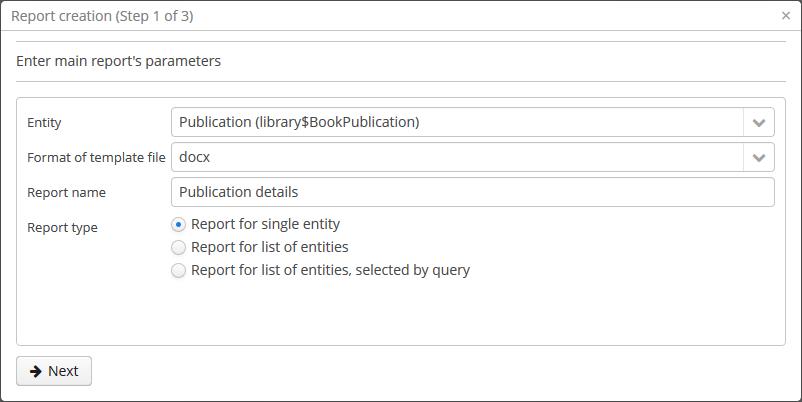
- CUBA introduces the report wizard functionality. With the help of the wizard, any user can rapidly create a report, even with limited knowledge of programming:

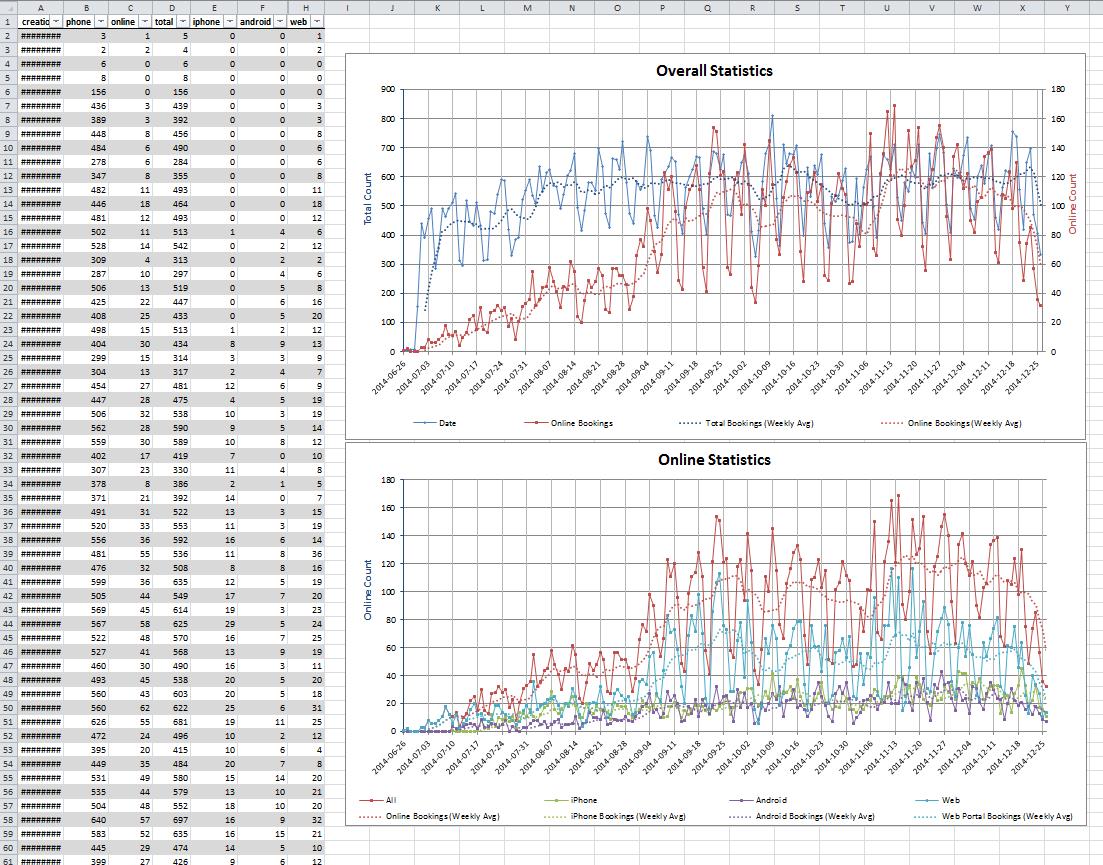
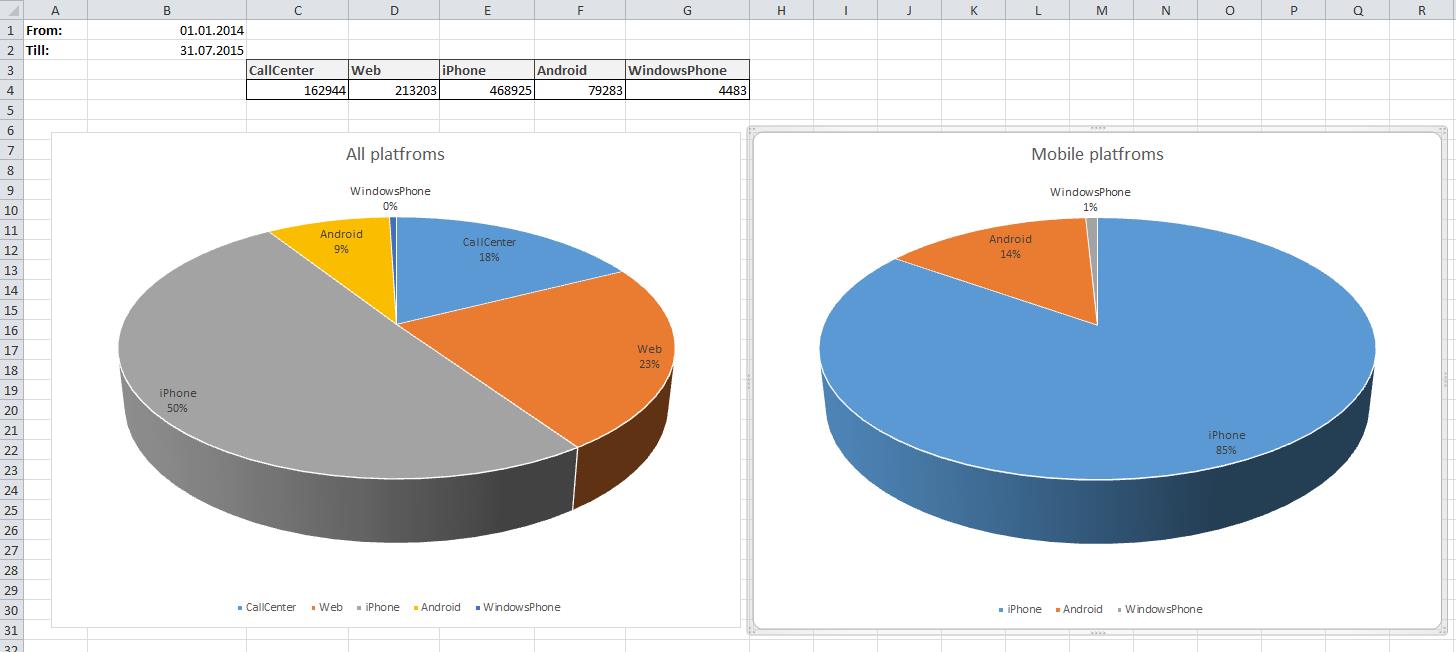
To conclude the article let me skip usual boring deep thoughts (especially because all the information can be found here) and throw in a couple of my favourite reports:
So, if you are interested follow the link and learn more! Note that YARG is completely free and available on GitHub.

I just start a new project. Somehow we have same ideas: e.g. separate presentation from data tiers, creating reports with template and data etc, but implementation is different. I’m developing a jsf component which can both display the report in web and export it as Excel spreadsheet. Actually this article give me more ideas for how to enhance it as reporting tool. Thank you.
Please check my showcase: http://showcase-tiefaces.rhcloud.com/showcase/sheet/WebSheetReports.xhtml
Thanks
Jason