To be honest, ‘scalability’ is an exhaustive topic and generally not well understood. More often than not, its assumed to be same as High Availability. I have seen both novice programmers and ‘experienced’ architects suggest ‘clustering‘ as the solution for scalability and HA. There is actually nothing wrong with it, but the problem is that it is often done by googling rather than actually understanding the application itself ;-)
I do not claim to be an ‘expert’, just by writing this post ;-) It just (briefly) lays out some strategies for scaling Java EE applications in general.
The problem…
Scalability is not a standardized component within the Java EE Platform specification. The associated techniques are mostly vendor (application server) specific and often involve using more than one products (apart from the app server itself). That’s why, architecting Java EE applications to be scalable can be a little tricky. There is no ‘cookbook’ to do the trick for you. One really needs to understand the application inside out.
Types of Scaling
I am sure it is not the first time you are reading this. Generally, scaling is classified into two broad categories – Scale Up, Scale Out
The first natural step towards scaling, is to scale up
- Scaling Up: This involves adding more resources to your servers e.g. RAM, disk space, processors etc. It is useful in certain scenarios, but will turn out to be expensive after a particular point and you will discover that it’s better to resort to Scaling Out
- Scaling Out: In this process, more machines or additional server instances/nodes are added. This is also called clustering because all the servers are supposed to work together in unison (as a Group or Cluster) and should be transparent to the client.
High Availability!=Scalability
Yes! Just because a system is Highly Available (by having multiple servers nodes to fail over to), does not mean it is scalable as well. HA just means that, if the current processing node crashes, the request would be passed on or failed over to a different node in the cluster so that it can continue from where it started – that’s pretty much it! Scalability is the ability to improve specific characteristics of the system (e.g. number of users, throughput, performance) by increasing the available resources (RAM, processor etc.) Even if the failed request is passed on to another node, you cannot guarantee that the application will behave correctly in that scenario (read on to understand why)
Lets look at some of the options and related discussions
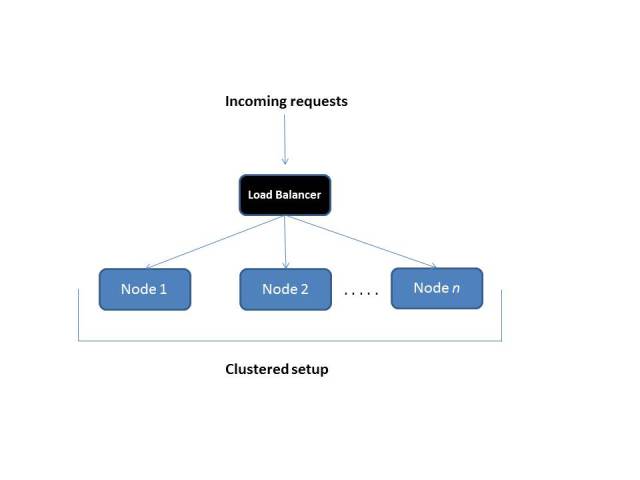
Load Balance your scaled out cluster
Let’s assume that you have scaled up to your maximum capacity and now you have scaled out your system by having multiple nodes forming a cluster. Now what you would do is put a Load Balancer in front of your clustered infrastructure so that you can distribute the load among your cluster members. Load balancing is not covered in detail since I do not have too much insight except for the basics :-) But knowing this is good enough for this post
Is my application stateless or stateful ?
Ok so now you have scaled out – is that enough ? Scaling out is fine if your application is stateless i.e. your application logic does not depend on existing server state to process a request e.g. RESTful API back end over JAX-RS, Messaging based application exposing remote EJBs as the entry point which use JMS in the back ground etc.
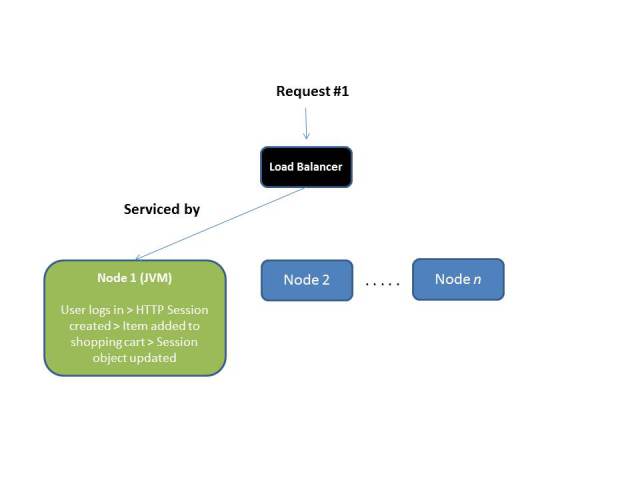
What if you have an application which has components like HTTP session objects, Stateful EJBs, Session scoped beans (CDI, JSF) etc. ? These are specific to a client (to be more specific, the calling thread), store specific state and depend on that state being present in order to be able to execute the request e.g. a HTTP session object might store a user’s authentication state, shopping cart information etc.
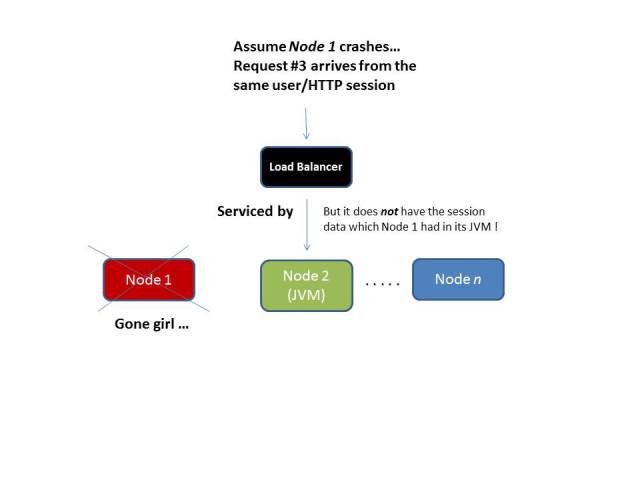
In a scaled out or clustered application, subsequent requests might be served by any cluster in the node. How will the other node handle the request without the state data which was created in the JVM of the instance to which the first request was passed to?
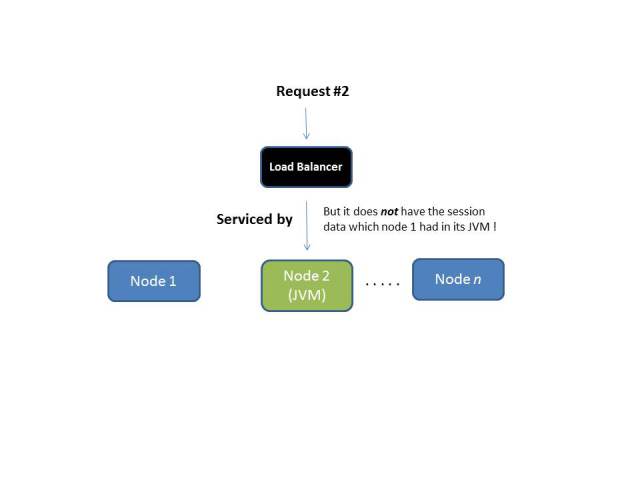
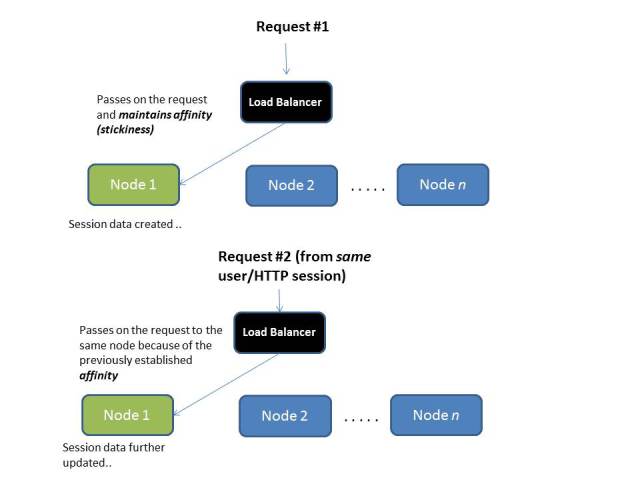
Hello Sticky Sessions!
Sticky Session configuration can be done on the load balancer level to ensure that a request from a specific client/end user is always forwarded to the same instance/application server node i.e server affinity is maintained. Thus, we alleviate the problem of the required state not being present. But there is a catch here – what if that node crashes ? The state will be destroyed and the user will be forwarded to an instance where there is no existing state on which the server side request processing depends.
Enter Replicated Clustering
In order to resolve the above problem, you can configure your application server clustering mechanism to support replication for your stateful components. By doing this you can ensure that your HTTP session data (and other stateful objects) are present on all the server instances. Thus the end user request can be forwarded to any server node now. Even if a server instance crashes or is unavailable, any other node in the cluster can handle the request. Now, your cluster is not ordinary cluster – it’s a replicated cluster
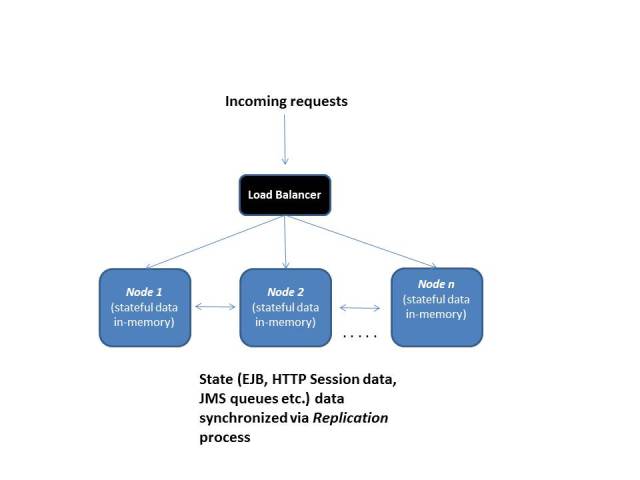
Cluster replication is specific to your Java EE container/app server and its best to consult its related documentation on how to go about this. Generally, most application servers support clustering of Java EE components like stateful and stateless EJBs, HTTP sessions, JMS queues etc.
This creates another problem though – Now each node in the application server handles session data resulting in more JVM heap storage and hence more garbage collection. Also, there is an amount of processing power spent in replication as well
External store for stateful components
This can be avoided by storing session data and stateful objects in another tier. You can do so using RDBMS. Again, most application servers have inbuilt support for this.
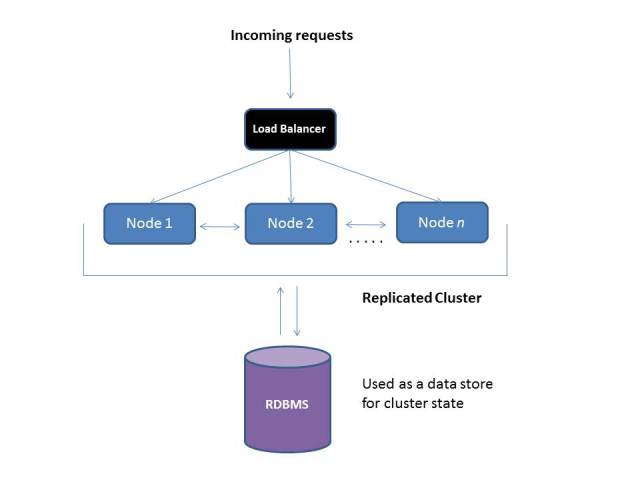
If you notice, we have moved the storage from an in-memory tier to a persistent tier – at the end of the day, you might end up facing scalability issues because of the Database. I am not saying this will happen for sure, but depending upon your application, your DB might get overloaded and latency might creep in e.g. in case of a fail over scenario, think about recreating the entire user session state from the DB for use within another cluster instance – this can take time and affect end user experience during peak loads.
Final frontier: Distributed In-Memory Cache
It is the final frontier – at least in my opinion, since it moves us back to the in-memory approach. Yo can’t get better than that! Products like Oracle Coherence, Hazelcast or any other distributed caching/in-memory grid product can be used to offload the stateful state storage and replication/distribution – this is nothing but a Caching Tier. The good part is that most of these products support HTTP session storage as a default feature
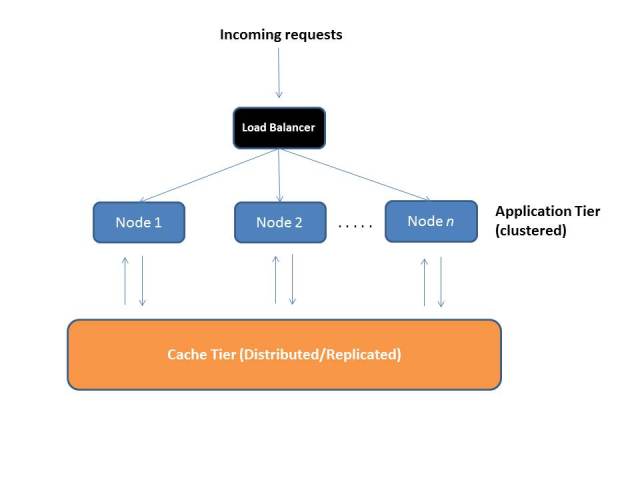
This kind of architectural setup means that application server restarts do not effect existing user sessions – it’s always nice to patch your systems without downtime and end user outage (not as easy as it sounds but definitely and option!). In general, the idea is that the app tier and web session caching tier can work and scale independently and not interfere each other.
Distributed!=Replicated
There a a huge difference b/w these words and it’s vital to understand the difference in terms of your caching tier. Both have their pros and cons
- Distributed: Members of the cache share data i.e. the data set is partitioned among cache cluster nodes (using a product specific algorithm)
- Replicated: All cache nodes have ALL the data i.e. each cache server contains a copy of the entire data set.
Further reading (mostly Weblogic specific)
- Clustering configuration
- RDBMS configuration for session persistence
- Distributed Web Session replication – Oracle Coherence, Hazelcast
- High Scalability – great resource!
Before I sign off…
- High/Extreme Scalability might not be a requirement for every Java EE application out there. But it will be definitely useful to factor that into your design if you are planning on building internet/public facing applications
- Scalable design is a must for applications which want to leverage the Cloud Platforms (mostly PaaS) like automated elasticity (economically viable!) and HA
- Its not too hard to figure out that stateful applications are often more challenging to scale. Complete ‘statelessness’ might not be possible, but one should strive towards that
Feel free to share tips and techniques which you have used to scale your Java EE apps.
Cheers!
| Reference: | Basics of scaling Java EE applications from our JCG partner Abhishek Gupta at the Object Oriented.. blog. |

“In a scaled out or clustered application, subsequent requests might be served by any cluster in the node”. I suppose it should’ve been “..any node in the cluster” :)