Apache Flink is a top-level Apache project that allows unifying distributed stream and batch processing. In the core of Apache Flink is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams.
On August 27, the Bay Area Apache Flink Meetup had another event hosted by MapR. This time, the main topics were around the distributed stateful streaming and graph analysis with Apache Flink. We are fortunate enough to have three special guests from Sweden, which are researchers from several academic institutions that focus on research and enhancing Apache Flink. Gyula Fóra is a Project Management Committee (PMC) member for Apache Flink, and is currently working as a researcher at the Swedish Institute of Computer Science. Vasia Kalavri is a PhD student at KTH, Stockholm and is also a PMC member of Apache Flink who focuses on working on Apache Flink’s graph processing API, Gelly. Last but not least, Paris Carbone is a PhD student in distributed computing at the Royal Institute of Technology in Sweden and a committer for Apache Flink.
In addition, we were also honored by guest speaker Ted Dunning from MapR, who is the Chief Application Architect at MapR Technologies and a committer and PMC member of the Apache Mahout, Apache ZooKeeper, and Apache Drill projects. He was also the mentor for Apache Flink during the incubation period. Ted shared his expertise and knowledge on the caveats of using micro batching and what a true streaming solution needs to provide for solving these problems.
Like many other Apache Flink meetups around the globe, the evening opened with community updates about Apache Flink since last meetup. Some notable new updates include a new UI for the Job Manager dashboard, more documentation updates, Gelly Scala API, high availability support, and the dropping of Java 6 in the master branch. There was also an announcement of the first conference dedicated to Flink, called “Flink Forward” that will take place in Berlin, Germany on October 12-13 (http://flink-forward.org).
For the first talk, Gyula Fóra presented a talk about stateful distributed stream processing (slides here) in several different popular stream frameworks. He showed different approaches each framework takes to support the concept of stateful streaming processing. The talk discusses basic concepts of stateful processing and high-level use cases and examples.
Stateful processing of data requires the computation to maintain a state during transition to another set of data. Some examples of stateful processing include Window-based operations on streaming data, machine learning to calculate the fitting of the model to the sample data, and finite state machines to do pattern recognition such as regular expressions.
All of the examples of stateful processing and algorithms mentioned before rely on one common pattern, which is a stateful operator. In the talk, the stateful operator was essence defined as: f: (in, state) → (out, state’)
The statement above means that a stateful operator is a function that takes an input data and the current state, and produces an output with an updated state of the processing system. Maintaining the state consistency for doing stateful stream processing at a large scale provides some challenges, since it has to deal with large scales of states and input data while maintaining correctness and fault tolerance of the system.
Some of the important issues that need to be addressed with stateful stream processing include:
- Expressivity
- Exactly-once semantics
- Scalability on large inputs
- Scalability on large states
Some frameworks that were included as comparisons are Apache Storm, Apache Spark Streaming, Samza, and last but not least Apache Flink. Firgure1 shows the summary of the positives and negatives of the approaches for Apache Storm (via Trident APIs), Apache Spark Streaming, and Samza to support stateful stream processing.

Apache Flink tries to get the good parts and reduce the bad parts for supporting stateful stream processing. Figure 2 shows the screenshot from the slide that listing all the things that Apache Flink supports to make it useful.

The exactly-once semantics are supported by Apache Flink using the fast checkpointing mechanim that was inspired by the Chandy-Lamport algorithm for distributed snapshots. This allows Apache Flink to store states as part of a data stream without overtaking the records and give low runtime overhead to store and retrieved the saved states.
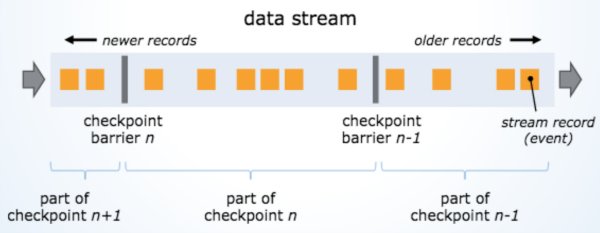
Next, Ted discussed when micro-batching, the approach that Apache Spark Streaming takes for its stream processing, is not good enough compared to a true streaming approach. Ellen Friedman from MapR has written an excellent blog about this talk and I encourage everyone to read it here: https://www.mapr.com/blog/apache-flink-new-way-handle-streaming-data.
Vasia then talked about the latest and greatest large-scale graph processing APIs and library in Apache Flink called Gelly (slides here). Vasia discussed Apache Flink native iterations support, and other notable features such as memory management and fast serialization algorithms, which make it a perfect choice for building a distributed large-scale graph processing library. Vasica showed the audience Gelly graph APIs and use case examples of how the algorithms solve the problems in efficient ways.
Graph processing can be seen in many situations such as in machine learning algorithms, operations research, and big data analysis pipelines. Figure 4 shows the typical big data analysis pipeline from the talk. In a typical flow, there are lots of specialized components that need to be stitched together to make the whole process work.
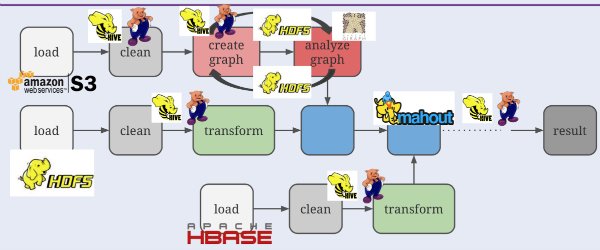
There always some tradeoffs between building a highly specialized vs. a general-purpose component when building a data processing system. Apache Flink tries to balance the tradeoffs of the positives and negatives of a general-purpose and specialized approach. Figure 5 shows the comparison for building a Graph processing framework, and Figure 6 shows what the big data analysis pipeline should look like with Apache Flink to make it easier to manage.


One of the main reasons to build a Graph API on top of Apache Flink is the native iteration operator that is optimized as a top-level operation in Apache Flink. Because of it, the runtime engine is aware of the iterative executions and allows optimization to reduce the scheduling overhead between iterations. On top of that, the cache and state maintenance are automatically handled by the core framework.
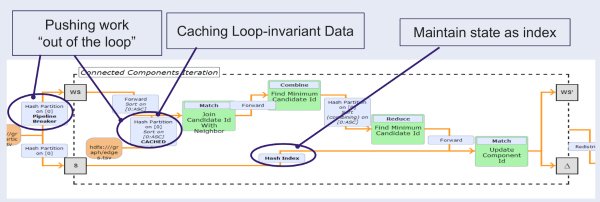
Gelly provides graph APIs on top of the Apache Flink core to allow manipulation and virtualization of the graph data structure of the data source, and provided distributing computing to process large-scale data. Figure 8 shows the available methods in Gelly APIs, and Figure 9 shows the code example of how to start with Gelly.


Paris Carbone shared the previews of the research on Apache Flink (slides here) which included an introduction to incremental checkpointing, windowing optimizations, machine learning pipeline design and streaming graph analytics on Flink. Paris also introduced and showed a demo video of Karamel, which is a new project to help deploy and orchestrate distributed systems such as Apache Flink.
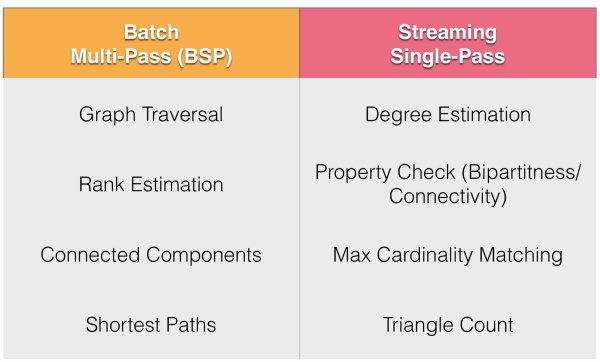
One of the new features that I am looking forward to seeing is the machine learning pipeline for stream data. This will allow us to apply machine learning algorithms to unbounded data with low latency, as well as instant application of certain machine learning algorithms for the clustering of classification. Another exciting possibility is streaming graph processing, which would allow single-pass graph algorithms on stream data.

It was a successful meetup and a very exciting evening for Bay Area Apache Flink enthusiasts. Most importantly, it generated lots of interest about Apache Flink as a next generation distributed streaming platform.
Please register and join the Bay Area Apache Flink meetup community for future knowledge sharing and to hear informational talks from more amazing speakers: http://www.meetup.com/Bay-Area-Apache-Flink-Meetup
| Reference: | Distributed Stream and Graph Processing with Apache Flink from our JCG partner Henry Saputra at the Mapr blog. |
