I first heard of Spark in late 2013 when I became interested in Scala, the language in which Spark is written. Some time later, I did a fun data science project trying to predict survival on the Titanic. This turned out to be a great way to get further introduced to Spark concepts and programming. I highly recommend it for any aspiring Spark developers looking for a place to get started.
Today, Spark is being adopted by major players like Amazon, eBay, and Yahoo! Many organizations run Spark on clusters with thousands of nodes. According to the Spark FAQ, the largest known cluster has over 8000 nodes. Indeed, Spark is a technology well worth taking note of and learning about.

This article provides an introduction to Spark including use cases and examples. It contains information from the Apache Spark website as well as the book Learning Spark – Lightning-Fast Big Data Analysis.
What is Apache Spark? An Introduction
Spark is an Apache project advertised as “lightning fast cluster computing”. It has a thriving open-source community and is the most active Apache project at the moment.
Spark provides a faster and more general data processing platform. Spark lets you run programs up to 100x faster in memory, or 10x faster on disk, than Hadoop. Last year, Spark took over Hadoop by completing the 100 TB Daytona GraySort contest 3x faster on one tenth the number of machines and it also became the fastest open source engine for sorting a petabyte.
Spark also makes it possible to write code more quickly as you have over 80 high-level operators at your disposal. To demonstrate this, let’s have a look at the “Hello World!” of BigData: the Word Count example. Written in Java for MapReduce it has around 50 lines of code, whereas in Spark (and Scala) you can do it as simply as this:
1 2 3 4 | sparkContext.textFile("hdfs://...") .flatMap(line => line.split(" ")) .map(word => (word, 1)).reduceByKey(_ + _) .saveAsTextFile("hdfs://...") |
Another important aspect when learning how to use Apache Spark is the interactive shell (REPL) which it provides out-of-the box. Using REPL, one can test the outcome of each line of code without first needing to code and execute the entire job. The path to working code is thus much shorter and ad-hoc data analysis is made possible.
Additional key features of Spark include:
- Currently provides APIs in Scala, Java, and Python, with support for other languages (such as R) on the way
- Integrates well with the Hadoop ecosystem and data sources (HDFS, Amazon S3, Hive, HBase, Cassandra, etc.)
- Can run on clusters managed by Hadoop YARN or Apache Mesos, and can also run standalone
The Spark core is complemented by a set of powerful, higher-level libraries which can be seamlessly used in the same application. These libraries currently include SparkSQL, Spark Streaming, MLlib (for machine learning), and GraphX, each of which is further detailed in this article. Additional Spark libraries and extensions are currently under development as well.
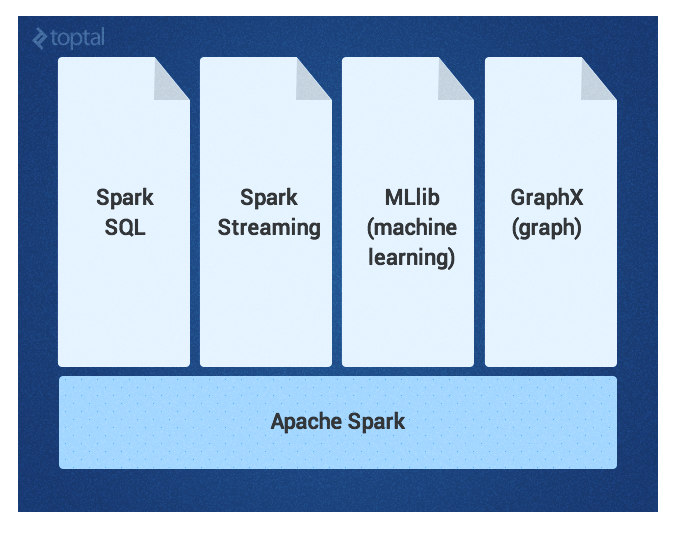
Spark Core
Spark Core is the base engine for large-scale parallel and distributed data processing. It is responsible for:
- memory management and fault recovery
- scheduling, distributing and monitoring jobs on a cluster
- interacting with storage systems
Spark introduces the concept of an RDD (Resilient Distributed Dataset), an immutable fault-tolerant, distributed collection of objects that can be operated on in parallel. An RDD can contain any type of object and is created by loading an external dataset or distributing a collection from the driver program.
RDDs support two types of operations:
Transformations in Spark are “lazy”, meaning that they do not compute their results right away. Instead, they just “remember” the operation to be performed and the dataset (e.g., file) to which the operation is to be performed. The transformations are only actually computed when an action is called and the result is returned to the driver program. This design enables Spark to run more efficiently. For example, if a big file was transformed in various ways and passed to first action, Spark would only process and return the result for the first line, rather than do the work for the entire file.
By default, each transformed RDD may be recomputed each time you run an action on it. However, you may also persist an RDD in memory using the persist or cache method, in which case Spark will keep the elements around on the cluster for much faster access the next time you query it.
SparkSQL
SparkSQL is a Spark component that supports querying data either via SQL or via the Hive Query Language. It originated as the Apache Hive port to run on top of Spark (in place of MapReduce) and is now integrated with the Spark stack. In addition to providing support for various data sources, it makes it possible to weave SQL queries with code transformations which results in a very powerful tool. Below is an example of a Hive compatible query:
1 2 3 4 5 6 7 8 | // sc is an existing SparkContext.val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")sqlContext.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")// Queries are expressed in HiveQLsqlContext.sql("FROM src SELECT key, value").collect().foreach(println) |
Spark Streaming
Spark Streaming supports near real time processing of streaming data, such as production web server log files (e.g. Apache Flume and HDFS/S3), social media like Twitter, and various messaging queues like Kafka. Under the hood, Spark Streaming receives the input data streams and divides the data into batches. Next, they get processed by the Spark engine and generate final stream of results in batches, as depicted below.
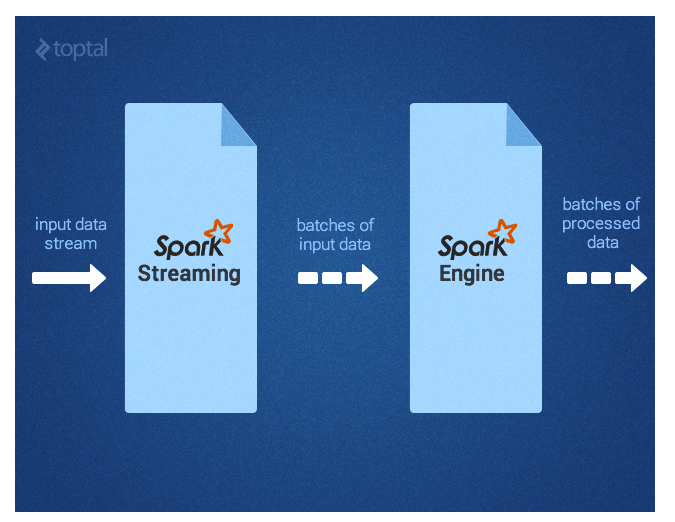
The Spark Streaming API closely matches that of the Spark Core, making it easy for programmers to work in the worlds of both batch and streaming data.
MLlib
MLlib is a machine learning library that provides various algorithms designed to scale out on a cluster for classification, regression, clustering, collaborative filtering, and so on (check out Toptal’s article on machine learning for more information on that topic). Some of these algorithms also work with streaming data, such as linear regression using ordinary least squares or k-means clustering (and more on the way). Apache Mahout (a machine learning library for Hadoop) has already turned away from MapReduce and joined forces on Spark MLlib.
GraphX
GraphX is a library for manipulating graphs and performing graph-parallel operations. It provides a uniform tool for ETL, exploratory analysis and iterative graph computations. Apart from built-in operations for graph manipulation, it provides a library of common graph algorithms such as PageRank.
How to Use Apache Spark: Event Detection Use Case
Now that we have answered the question “What is Apache Spark?”, let’s think of what kind of problems or challenges it could be used for most effectively.
I came across an article recently about an experiment to detect an earthquake by analyzing a Twitter stream. Interestingly, it was shown that this technique was likely to inform you of an earthquake in Japan quicker than the Japan Meteorological Agency. Even though they used different technology in their article, I think it is a great example to see how we could put Spark to use with simplified code snippets and without the glue code.
First, we would have to filter tweets which seem relevant like “earthquake” or “shaking”. We could easily use Spark Streaming for that purpose as follows:
1 2 | TwitterUtils.createStream(...) .filter(_.getText.contains("earthquake") || _.getText.contains("shaking")) |
Then, we would have to run some semantic analysis on the tweets to determine if they appear to be referencing a current earthquake occurrence. Tweets like ”Earthquake!” or ”Now it is shaking”, for example, would be consider positive matches, whereas tweets like “Attending an Earthquake Conference” or ”The earthquake yesterday was scary” would not. The authors of the paper used a support vector machine (SVM) for this purpose. We’ll do the same here, but can also try a streaming version. A resulting code example from MLlib would look like the following:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | // We would prepare some earthquake tweet data and load it in LIBSVM format.val data = MLUtils.loadLibSVMFile(sc, "sample_earthquate_tweets.txt")// Split data into training (60%) and test (40%).val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L)val training = splits(0).cache()val test = splits(1)// Run training algorithm to build the modelval numIterations = 100val model = SVMWithSGD.train(training, numIterations)// Clear the default threshold.model.clearThreshold()// Compute raw scores on the test set. val scoreAndLabels = test.map { point => val score = model.predict(point.features) (score, point.label)}// Get evaluation metrics.val metrics = new BinaryClassificationMetrics(scoreAndLabels)val auROC = metrics.areaUnderROC()println("Area under ROC = " + auROC) |
If we are happy with the prediction rate of the model, we could move onto the next stage and react whenever we discover an earthquake. To detect one we need a certain number (i.e., density) of positive tweets in a defined time window (as described in the article). Note that, for tweets with Twitter location services enabled, we would also extract the location of the earthquake. Armed with this knowledge, we could use SparkSQL and query an existing Hive table (storing users interested in receiving earthquake notifications) to retrieve their email addresses and send them a personalized warning email, as follows:
1 2 3 4 5 | // sc is an existing SparkContext.val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)// sendEmail is a custom functionsqlContext.sql("FROM earthquake_warning_users SELECT firstName, lastName, city, email") .collect().foreach(sendEmail) |
Other Apache Spark Use Cases
Potential use cases for Spark extend far beyond detection of earthquakes of course.
Here’s a quick (but certainly nowhere near exhaustive!) sampling of other use cases that require dealing with the velocity, variety and volume of Big Data, for which Spark is so well suited:
In the game industry, processing and discovering patterns from the potential firehose of real-time in-game events and being able to respond to them immediately is a capability that could yield a lucrative business, for purposes such as player retention, targeted advertising, auto-adjustment of complexity level, and so on.
In the e-commerce industry, real-time transaction information could be passed to a streaming clustering algorithm like k-means or collaborative filtering like ALS. Results could then even be combined with other unstructured data sources, such as customer comments or product reviews, and used to constantly improve and adapt recommendations over time with new trends.
In the finance or security industry, the Spark stack could be applied to a fraud or intrusion detection system or risk-based authentication. It could achieve top-notch results by harvesting huge amounts of archived logs, combining it with external data sources like information about data breaches and compromised accounts (see, for example, https://haveibeenpwned.com/) and information from the connection/request such as IP geolocation or time.
Conclusion
To sum up, Spark helps to simplify the challenging and compute-intensive task of processing high volumes of real-time or archived data, both structured and unstructured, seamlessly integrating relevant complex capabilities such as machine learning and graph algorithms. Spark brings Big Data processing to the masses. Check it out!
- Transformations are operations (such as map, filter, join, union, and so on) that are performed on an RDD and which yield a new RDD containing the result.
- Actions are operations (such as reduce, count, first, and so on) that return a value after running a computation on an RDD.
| Reference: | Introduction to Apache Spark with Examples and Use Cases from our JCG partner Radek Ostrowski at the Mapr blog. |
