Someone on your team has an exciting suggestion, a new technology to introduce. But is it a good idea?
It’s often easier to see the immediate benefits than the immediate risks or the long-term anything. This article looks at questions to ask and precautions to take when implementing new technologies in the development and running of software.
First, recognize that different technologies carry different risks. Ask yourself — what’s the worst that could happen? and what pain is inevitable? Also ask — what’s the best that could happen? And finally, how can I implement this with minimum danger?
The biggest distinguishing factor in the risk profile is where in the technology stack this new idea falls:
- Programs used by one person are low-risk.
- Testing tools are fairly safe for exploration.
- There is more risk in anything that runs in production (including monitoring and logging)…
- Or anything that gets code into production (provisioning, build, deployment).
- A new programming language brings special burdens.
- Components that move data around need diligent support.
- And finally, beware granting trust to a new system of record for production data.
This spectrum is illustrated below.
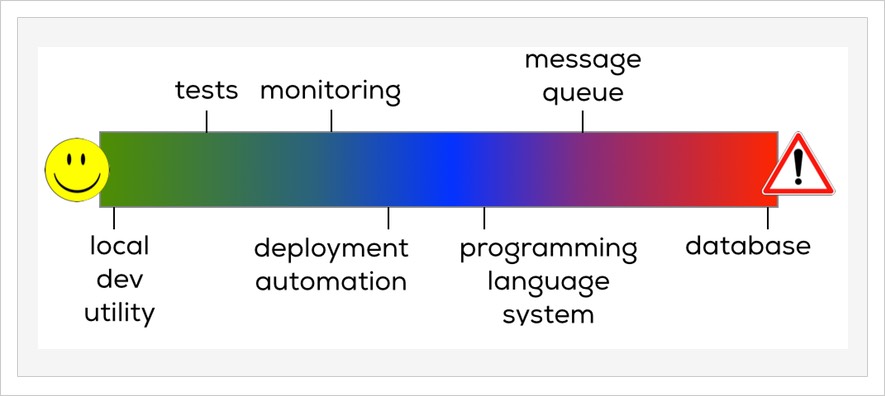
Not scared yet? Let’s consider in detail four points on this risk spectrum.
Very Low Risk: Local Developer Utilities
Development is automation, and fast developers automate development. The lowest-risk technologies are run by us, on our own machines. Any repetitive task that I can speed up adds a few seconds to my day, with very little cost.
Here’s an extreme example: a command line alias. I type “git status” a hundred times per day, so I configure my shell with “alias gs=’git status’”. It’s a tiny optimization. It affects only me: no one else on my team, no customers.
When I hit a good optimization, it can spread across the team. That’s the best that can happen. The whole team gets a productivity boost for the rest of their lives.
What’s the worst that can happen? I use another computer and can’t remember how to ask which files have local changes — seems unlikely.
Actually, it’s a little worse: On some Linuxy VMs, my reflex of typing “gs” at every command prompt drops me into a program called “ghostscript,” which is totally NOT what I wanted, and then I have to remember how to exit it, and then I’m all frustrated and distracted and cursing about stupid ghostscript. After enough times, I edit the shell configuration for that machine to add the alias.
Now my fingerprints are on it; uniformity is sacrificed, and command prompts across the company are a bit less predictable. Even a tool this tiny has some consequences.
Should you forbid your developers from creating aliases or installing programs that they personally find productive? No! Only if you like developers who prefer repetition to automation. And if a person eschews automation, can they be a good automator?
Before saying “no” to a technology, consider the effects on retention. What kind of developer will want to stay or leave? I once worked at a company where the correct process for installing a text editor included filling out forms and waiting a month for approval. I didn’t work there very long.
Low-risk category
- Affects only the person who chooses to use it
- If we stop using it, we’re exactly where we were before
Pro: Others on the team learn a tool they didn’t know, and the productivity of the whole team goes up.
Con: It’s tough to switch environments, therefore harder to pair.
Inevitable cost: Just the set up.
Incentives: Developers feel empowered to automate.
Moderate Risk 1: Deployment Infrastructure
What’s better than automating my work? Automating tasks for my whole team. What’s risky about this? My whole team is thrown off if this tool breaks.
The output of development is not code: It’s working software in production. There’s a broad gulf between the two. DevOps bridges this with automation. Infrastructure tools build executables, run tests, push new versions into production, and watch to make sure they keep working.
These are hot areas of innovation lately. Constant improvement has a big impact here — any company that isn’t making advancements here is falling behind and losing competitive advantage. But what are the costs?
The new tech could be small: GitHub webhooks to trigger CI builds to start whenever code is committed. Or a quality-check commit hook that enforces code formatting.
It could be bigger: Splunk for log aggregation or Ansible for declarative provisioning. It could even be Docker — a whole ecosystem to worry about. That little bash script that you wrote counts too! Anything that runs for every build/test/deploy is part of your team’s core operation.
What’s the worst that can happen? It breaks, and you can’t deploy. That’s bad. Very bad, if it coincides with some urgent production bug.
When the deployment process breaks for some other reason, each new tool is an item that we have to check on. It’s another thing a person has to understand about how code gets to production. Mitigate this risk by running deploys frequently, so latent surprises can’t linger.
What’s the inevitable drudgery? One more thing to set up when we spin up. Modern architecture trends include more, smaller projects, so spin-up is more frequent. Either we add this to our project setup automation, or we do it and troubleshoot it each time.
Here’s the crucial bit: Someone in the company has to understand this tool. Someone must know how it works, where it fits, and why it is here.
If you’re introducing this innovation, that person is you. For risk mitigation, it can’t stay just you. Are your teammates interested in learning about it? How good is the documentation, so that they can learn about it from sources other than you? How readable is that bash script?
Every piece of our tooling requires ownership. For tools I use, I own it, no problem. For tools everyone uses, the answer to “Who owns this?” is less obvious and more important.
Any program in the path to production needs care and maintenance; if its code doesn’t change, the world changes around it. Tools are upgraded. Environments change, business constraints shift. Responsibility does not end with implementation: Responsibility ends when a program is no longer run.
If this sounds painful, don’t forget to ask, what’s the best that can happen? Deployment automation is much bigger than time saved. It shifts incentives, making change safer and more appealing. The impact of this reaches far outside the team: The whole business is empowered to experiment and move faster.
The highest-impact development tools are shared, and yet sharing them creates an ownership question. When you already have a DevOps mindset, a DevOps team can help. They can raise the productivity of all the other developers by offering infrastructure and taking responsibility for these shared tools. They study the benefits and take on the risks. They sell development teams on using them.
Twitter, Netflix, Lyft, and many other companies do this. For less software-focused companies, individual developer initiative makes the difference.
Moderate risk category
- Deployment automation
- Used by many developers
- In verification or deployment path
Pro: Change becomes less risky and less painful.
Con: Something breaks, production deploys are blocked.
Inevitable cost: Ongoing ownership and maintenance
Incentives: Developers are empowered to improve the whole department.
Moderate Risk 2: Programming Language
Programming languages are sprouting up all over the place lately. Add in microservice architecture, and variation in language gets practical. What does it mean to bring a new language into your production environment?
A programming language does not work alone. We develop in programming systems, and the language is a part of that. With a new language comes new syntax… and new build tools, new dependency management, new libraries, new packaging, new test frameworks, and new internal DSLs.
Any of these may be a reason for bringing in the language. For instance, ScalaTest is great for testing Java code. Python has fast number-crunching with its Pandas library. Go makes it easy to create binaries.
What’s the worst that could happen? Code in production that no one understands. If the original enthusiasts leave, someone else will need to learn the language or else rewrite it all.
Careful isolation can mitigate the risk by making the experimental code replaceable. For instance, Richard Feldman introduced Elm at NoRedInk by selecting a piece of business logic with a clear interface. That left a contingency plan (“write it again in JavaScript”) and limited cost to time spent on the Elm implementation.
When you introduce a new language to your company, you’re taking on another full-time job. You become the local expert, the troubleshooter. All problems are your problem until the rest of the team is up to speed. And if you don’t get them up to speed quickly, that’s irresponsible.
As Camille Fournier pointed out, some companies use polyglot microservices to avoid having to communicate between teams. “When they do this, they’re sharding their humans.” If they’re not also replicating this knowledge among people, then one person quits, and essential knowledge is lost.
What’s the inevitable pain that will happen? Integrating the language system. That new code must be built and tested and packaged for deployment. How will it be monitored? Debugged? Many factors affect how painful this will be.
If you’re bringing Scala into a Java environment, both JVM languages work the same once compiled. Adding Ruby to a Java environment is harder. If your deployment pipeline is based around containers, that limits the pain. If the infrastructure is language-specific, this is going to hurt. At NoRedInk, building Elm into a Rails ecosystem was a lot of work.
Consider how well-developed the tooling around a language is and whether other people have integrated this language into a stack like yours and documented it.
Here’s another piece of definite pain: Code that is written will be read.
When troubleshooting a data flow that crosses language boundaries, there is a cost to switching back and forth. Even when I know all the languages involved, it hurts my head to move back and forth between Bash scripts, Scala, Ruby, cloud-init, AWS Cloud Formation… every piece of the tech stack contributes to the cognitive overhead of debugging. “The right tool for the job” is only worth it when the complexity reduction is greater than the overhead of switching my brain into that tool.
Avdi Grimm once deliberately used all the best-suited utilities (awk, sed, make, perl) for each piece of a process and found that the burden of switching between them far overshadowed the benefit of each piece being maximally concise. The extreme of “right tool” can be as painful as the extreme of “only tool.”
If you do add a whole new language to your stack, you gain access to all its strengths. What’s the best that could happen? You can learn more from a language than syntax. You gain access to its community.
Consider the incentives for recruiting — what kind of people will want to work here, knowing they can use Clojure or F# or Elm? A small startup like NoRedInk attracts enthusiastic developers who want to work in Elm. Sure, there are fewer Scala developers than Java developers in the world. But there’s a talent differential between those groups, too. Which developers do you want to attract?
Moderate risk category
- Programming language
- A new option for how to write code
- Variety in production systems
Pro: Access to new capabilities and a new community of developers, with new ideas.
Con: Code in production that no one understands.
Inevitable cost: Deployment automation, learning an entire system of tools and libraries.
Incentives: Retain and attract eager learners.
Serious Risk: Database
If we put code in production and later regret it, we can rewrite that code. Start the new one, stop the old one.
That’s painful, but it’s not any more work than writing it this way in the first place would have been. This is not true of replacing a database. A stateful system of record is a serious commitment.
Once a database starts up in production, it has your data. You can’t start a new one, stop the old one, and have everything continue as before. You have to do a migration. You have to extract all the data from the old database, insert it into the new one, then get all the data that was inserted into the old database during this process, put that into the new one.
There’s nothing easy about cutting over from one database to another.
On a past team, we wanted to implement a better-suited database, but writing the new code took time, and all our time was eaten by propping up an overburdened, outdated, insufficiently configured deployment of ElasticSearch (not intended as a system of record! Our bad!). We couldn’t wipe it out; we needed that data. We couldn’t get it out; the load was too much.
What’s the worst that can happen? You lose data. Please implement some form of replication. Backups, restores, migration automation — a database is part of a whole system, as well. All of these should be in place and tested before production data enters.
What’s the inevitable small pain? You’re going to learn all the quirks of storing and querying. Please isolate this behind a service; the most essential part of microservices is this isolation.
Then there’s maintenance: monitoring, upgrading, re-provisioning as load increases and storage expands. Don’t be fooled by a fast time-to-hello-world story. That initial “Hey, I can store data!” is very different from a smoothly running database with increasing production load.
All of this is hard, and it’s business-critical. Any technology that is entrusted with your data — even ephemerally, as in a queue — needs a team behind it.
What’s the best that can happen? A well-chosen datastore enables queries that couldn’t happen otherwise. Always ask, “Now that we have this, what else can we do?” Perhaps graph queries are now fast. Perhaps what was once a batch process can now be realtime. Maybe now we can dynamically update some insightful visualizations for customers.
Serious risk category
- Database
- Trusted to retain essential state
Pro: Questions that were impossible to answer become easy.
Con: Data is lost or inaccessible, business stops.
Inevitable cost: Learning every configuration option, quirks of querying, automating migrations and backups and restores.
Incentives: Thinking carefully about storage tradeoffs for each
business situation.
Conclusion
The tradeoffs are different for every team, every context, and every possible technology. Make this choice consciously. Research the tech, map out your own needs, and be careful.
If you are parsimonious about adding to your stack, it is still crucial that your team continues to learn about new technology and ways of thinking.
Consider isolating this function from feature development. One company sets aside the first hour of each day to mob-program on some new technology. An hour of focused work can take a lot of the shine off, while surfacing useful ideas. Other companies have Fridays for hacking on a project of choice. Internal tools can be low-risk ways of exploring otherwise high-risk technologies.
When you do accept a technology into your stack, make sure it has an owner. Spread knowledge through pairing, documentation, and communication. Make responsibility explicit and set aside time for maintenance, upgrades, and reassessment. The right technology today will be the wrong technology at some point.
The developers you want will want to be productive for the business. Give them the freedom and the information to choose the right tools, not for what they’re doing today, but for what the company will do in the future. Consider the best, the worst, and the inevitable. And always appreciate excitement when you see it.
| Reference: | Growing Your Tech Stack: When to Say No from our JCG partner Jessica Kerr at the Codeship Blog blog. |
