Introduction
In this article I will show an example of how to use the JDBC bulk insert features supported by Oracle — and which are specific to Oracle.
For more details on why one might like to resort to using bulk inserts in general, e.g., performance considerations when certain circumstances warrant, see the JCG article, “JDBC Batch Insert Example ” by Joormana Brahma published on April 12th 2015.
There Ms. Brahma gives 3 examples of how to accomplish this feat in JDBC using MySQL, but the Oracle-specific way which I show in this article can be viewed as a cross between her second and third example, e.g., a hybrid between the PreparedStatement and Batching the Batch.
Oracle Setup
To leverage the Oracle-specific features supporting JDBC bulk insert which I show in this example, you will first need to create a couple of user-defined types in your Oracle database.
The first type maps to a record in the table into which you are bulk inserting, and the second type maps to a variable array of the first type. In other words, you can think of the first type as a row in the table, and the second type is just an array of those rows.
It is this array which you are bulk inserting into the table, using Oracle-specific features which support JDBC bulk operations that I will demonstrate in this article.
So the first thing to create in this example is the table in Oracle (see Listing 1 below).
DROP TABLE "SYSTEM"."EMPLOYEE";
CREATE TABLE "SYSTEM"."EMPLOYEE"
( "FIRST_NAME" VARCHAR2(20 BYTE),
"LAST_NAME" VARCHAR2(20 BYTE),
"EMP_NO" NUMBER,
"JOIN_DATE" DATE
)
TABLESPACE "SYSTEM" ;
Listing 1. DDL to create the “Employee” table
This table is a simplified version of the Employees table in the HR schema which Oracle uses for its examples in Application Express. Note the example in Listing 1 is created by the System user — which is not realistic for actual usage, but will suffice for our purposes here, e.g., there is a mix of SQL types in the fields such as number and date in addition to varchar2.
Next we need to create a user-defined type which maps to a row in this table (see Listing 2 below), e.g., note that it has a direct correlation to the fields in the Employee table in Listing 1.
create or replace TYPE t_type AS OBJECT ( first_name varchar2(20), last_name varchar2(20), emp_no number, join_date date );
Listing 2. PL/SQL to create the “ t_type ” object
Then we need to create another user-defined type which maps to a variable array of the first type (see Listing 3 below).
create or replace type tb_t_type as varray (1000000) of t_type;
Listing 3. PL/SQL to create the “ tb_t_type ” object
Note that here we define this array to have a maximum size of 1 million,. You can adjust this size to fit your own needs — within your own resource constraints, of course — but we will indeed bulk insert 1 million records in our JDBC example here.
Finally, we will need to create the stored procedure which is invoked by the bulk operation (see Listing 4 below).
create or replace
procedure add_employees (emparray in tb_t_type) as
begin
forall i in emparray.first .. emparray.last
insert into EMPLOYEE( first_name,
last_name,
emp_no,
join_date )
values( emparray(i).first_name,
emparray(i).last_name,
emparray(i).emp_no,
emparray(i).join_date );
end add_employees;
Listing 4. PL/SQL to create the “add_employees” stored procedure
Note the use of the forall idiom in this PL/SQL, which makes the actual bulk insert operation about half an order of magnitude faster than otherwise possible if only using a plain-vanilla “for loop.” Specifically in my own demo runs, I have noticed the forall idiom yields results which are about 5 times faster.
N.B. — In this example I have used Oracle Database Express Edition 11g Release 2 on a Dell laptop running Windows 7 Home Premium with an Intel i5 processor @ 1.7GHz with 8GB RAM. For the Oracle JDBC driver, I used ojdbc6.jar.
JDBC
With the Oracle setup done, now we can take a look at how to leverage the Oracle-specific features supporting JDBC bulk insert operations (see Listing 5 below).
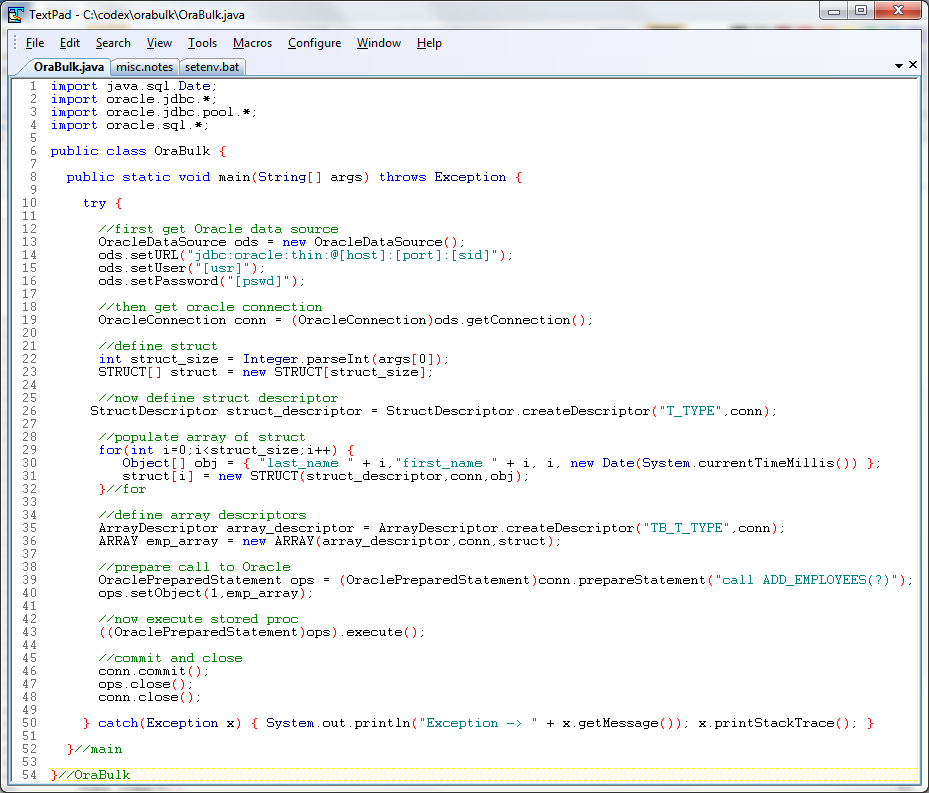
Listing 5. Java example illustrating the Oracle-specific features supporting JDBC bulk insert operations
Analysis
Notice the import statements on lines 2-4, i.e., these are Oracle-specific types as defined in ojdbc6.jar, and this goes to my point earlier on this example is leveraging Oracle-specific features for the JDBC bulk insert.
As denoted in the comment on line 12, the first thing to do is to get our data source. Note that for lines 14-16, you will need to substitute your own values for the host, port, and service id (“sid”) — though if you use the default port, that will just be 1521.
On lines 22-23, we define an array of Oracle STRUCT which maps to the user-defined type we created earlier in our Oracle database, “tb_t_type” (see Listing 3). Also on line 22, we get the size of this variable array from the command line, i.e., we run this example with 1 million records in the bulk insert operation as follows:
java OraBulk 1000000
On line 26, we define the Oracle struct descriptor which maps to the user-defined type we created earlier in our Oracle database, “t_type” (see Listing 2).
Next on lines 29-31, we populate the array of records we are preparing to bulk insert. The way it is done in this example is a bit contrived, e.g., the joining date for the employee is simply the time when that element is iterated over in the loop, but it will suffice for our purposes here, its artifice notwithstanding.
On lines 35-36, we define the Oracle array descriptor which maps to the user-defined type, “tb_t_type” (see Listing 3), and instantiate the Oracle array by referencing the Oracle struct we defined on line 23.
With all the prerequisite work out of the way, we next create the Oracle prepared statement on line 39 to reference the stored procedure we defined earlier in our Oracle database (see Listing 4). Then it sets the Oracle array as its first parameter (see line 40).
Finally, having set up everything, we execute the prepared statement with little fanfare on line 43.
Having accomplished the main event, the anti-climactic denouement on lines 46-48 are for the obligatory commit and closing to release resources. Note that if an exception occurred during the bulk insert, then everything would have been rolled back as the autocommit would have been off by default.
Summary
On my benchmark runs, bulk inserting 1 million records in Oracle Database Express Edition 11g Release 2 using this code took 12.55 seconds on my Dell laptop running Windows 7 Home Premium with an Intel i5 processor @ 1.7GHz with 8GB RAM. For the Oracle JDBC driver, I used ojdbc6.jar.
- You can download the code and the sample PL/SQL here on JCG

how to do that for update
You would use bulk update rather than bulk insert. For instance, see https://ittutorial.org/bulk-insert-and-bulk-update-bulk-delete-in-oracle-database/