Are you ready to start streaming all the events in your business? What happens to your streaming solution when you outgrow your single data center? What happens when you are at a company that is already running multiple data centers and you need to implement streaming across data centers? What about when you need to scale to a trillion events per day? Jim Scott, Director of Enterprise Strategy and Architecture at MapR, gave an informative presentation at Strata+Hadoop World, where he answered these questions and discussed technologies that can be used to accomplish real-time, lossless messaging that work in both single and multiple globally dispersed data centers. He also described how to handle the data coming in through these streams in batch processes as well as real-time processes.
https://www.youtube.com/watch?v=PVRhT-iakeE
What Does “Streaming to the Extreme” Really Mean?
- You’re able to support a trillion events every day. Let’s say that I want a streaming system that can handle a trillion events per day. Now, you might think that that sounds like a lot, but in actuality, when you start looking at different use cases and different types of logs and different instrumentation data that may come out of your data center or your given use case, these numbers add up very quickly. From my personal experience in digital advertising, we supported 60 billion transactions a day. Sixty billion is quite a ways off from a trillion, but when you start looking at all the servers that we had and all of the instrumentation data that we had coming out of all the different points of those servers, we had probably a good 100 different points that we measured data coming out of those servers. We were sampling that on the scale of one to five seconds depending on the server. On a 24 hour operation, it adds up really fast. We have to be able to support a trillion events per day to get to this model that really gets to where I consider streaming to be extreme.
- Your use case involves millions of producers. With enterprise use cases, where you want to cover everybody’s use cases with the platform, you’ll want easy administration, and you’ll need to be able to handle potentially millions of producers; this does equate out to billions of events per second.
- You have multiple consumers. These multiple consumers may actually all consume the same events. If you have a trillion events coming in, this is going to fan out into however many potential consumers you’re going to have for each data stream. When you start seeing complicated use cases in web-driven companies, it’s not really unexpected. This is something that you have to plan for.
- You want to be able to have multiple data centers. What happens when you build this and it works? You’re going to need to scale it. If you can’t handle multiple data centers for a web-driven company, you’re probably going to have to go back to the drawing board and re-architect your solution. Also, in a streaming model where you have trillions of events and multiple data centers, you have to be able to have a plan in case you encounter failures.
- You need to have a completely secure system. This is an important factor in order to have a safe environment where streaming systems can be used easily in regulatory environments.
What’s Under the Hood of a Streaming System?
Messaging persistence/messaging platform. A streaming system includes a messaging platform. Underneath that messaging platform, you have storage. There are different platforms available for this, some of which are very popular these days, like Kafka. I don’t include Flume in the messaging category, as it really is for log shipping. ZeroMQ, RabbitMQ, and Qpid are some other options, but none of them really scale the same way that a solution like Kafka or MapR Streams does. [Editor’s note: A new event streaming system, MapR Streams, was announced in December. It’s the first big data-scale streaming system built into a converged data platform, and the only big data streaming system to support global event replication reliably at IoT scale.]
Streaming engine. On the streaming engine side, there are a lot of streaming engines available, such as Flink, Samza, Spark Streaming, and Storm. It’s important to keep in mind that Spark is not real time; it is micro-batch and is not event-based.
Logical Dataflow
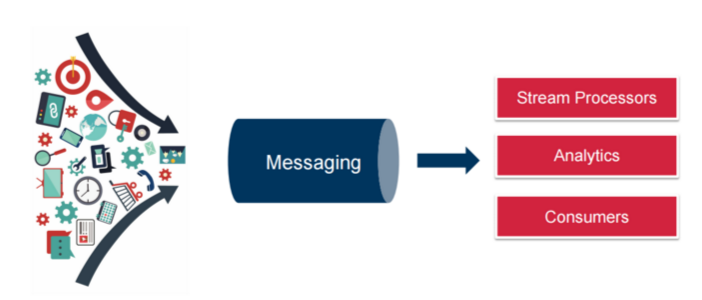
As we start looking at this use case, we’ve got a lot of data coming in from a lot of potential sources through a messaging system that’s going to go out to different types of consumers. Conceptually, stream processing is what people think about when they think about a messaging platform. Ideally, you should be able to have any application you want out there working with this messaging platform, as it’s something that’s going to help you build scalable components in your platform.
Putting Goals in Perspective
This is an “as-it-happens” world. I’ve work on too many systems in the past, where we get started and everybody thinks it’s going to be good enough. Within a month after productionizing it, the response is, “This is great. This is 10X faster than it ever was before. We need it even faster now that we know what’s capable.” This type of scenario happens all the time, so you have to prepare for it.
On-demand TV, taxi, everything. When we start looking at services that are out there, really everything is “on-demand” and rightfully so. We’ve built technology to be able to support this. What’s important to understand is that if you don’t start moving in the right direction, you’re going to get left behind; it only takes little steps to get moving in this direction. You don’t have to tackle the biggest initiative in your company to start using a messaging system, but you don’t just get to a trillion events a day by installing a streaming and messaging platform tomorrow and crossing your fingers that it works. Get started sooner than later. Take something easy that you can tackle and have success with. It’s the best way to move forward with these new technologies.
IoT will bury you. If you’re doing anything in IoT and you’re not preparing for this, it will bury you, as the volume of data IoT generates is ridiculous. Of course, you may choose to have down-sampled streams, where you might not be capturing everything that’s generated —that’s okay. However, if you’re picking up sensor readings every 100 milliseconds or every second every day, it adds up very fast. You’ll need to choose the right platform in order to properly ingest this data.
Messaging Platforms
The weakest link in a chain is what causes failures. A messaging platform is the most important link in the chain. If you don’t choose right, it’s going to be the bottleneck of the whole platform. Your messaging platform needs to have certain key capabilities in order for a stream processing engine to meet business needs of your organization. What happens, however, is that people often get bogged down with message delivery semantics; a lot of people think, “The only thing that’s acceptable is exactly once.”
Don’t Get Bogged Down with Message Delivery Semantics
At-most-once. First, there’s at-most-once, which most people that I know say, “This will never work. You can never do at-most-once.” However, when you’re dealing with sensor data, that’s perhaps not life threatening sensor data, or life administering sensor data, it doesn’t matter if you handle every sensor reading that comes through every 10 milliseconds. You can miss some. Not a big deal. Reprocessing it, not a big deal. There’s a big difference between receiving none and receiving almost all. That’s the main point of at-most-once. This is usually the least desirable outcome.
At-least-once. Additionally, at-least-once is the one that actually can deliver the best performance and the best guarantee in your system for most use cases. Logically, it is a considerable better way to go than exactly-once because of the overhead that is required to implement exactly-once.
Exactly-once. Exactly-once requires extra write-ahead logs at different tiers of your system to ensure that no data is lost, each datum is processed exactly one time, and you must have some context around a transaction that can occur to make sure it happens one time and one time only.
If you’re looking at these models, you should be thinking if at all possible, follow an at-least-once model and make sure that the code handling your data are idempotent because you can replay the message a million times if your function is idempotent and you don’t have to worry about the result changing.
If you take time series data as an example, by inserting a metric with a time-stamp into my database a million times and that time-stamp and metric ID can never change, my result in the database will never change if I continue inserting that time-stamped value. Considerably different than running it through a function where you say, “Add two values together” or “Add the last two values together,” and if you don’t add exactly the last two items together, you may end up with different sums than you anticipated.
These message delivery semantics apply to both the messaging platform and the streaming platform. I can’t encourage enough that you need to make “idempotent” part of your vocabulary when you’re dealing in this space. If it is at all possible for you to make sure your functions are idempotent, you should go that route. The performance difference between at-least-once and exactly-once is drastic.
Platform Options
Qpid. Six years ago, I used Apache Qpid, and we used to get 60,000 events per second through the system. We were ecstatic. That was so awesome. It’s really nothing now. The volume just isn’t even competitive with the other technologies, but exactly-once is the sweet spot of those queues.
Flume. I architected a solution for Flume and the team put it in place. Flume was handing 50 to 60 billion log lines per day getting shipped across the network. Now, the problem is that means it’s basically doing little batches of data, and it takes longer to get things moved around appropriately. You have to set up a lot of special configuration for your environment. While Flume is very capable, it does not come close to meeting an expectation that I have to get to extreme messaging. It can do high volumes, but as you start to scale it, administration will kill you.
Kafka. Kafka’s really become one of the most dominant in the space, as it scales so easily. It’s got a decent API to work with and it’s not ridiculously complicated from a programmatic standpoint.
Opportunities for Improvement
Disaster recovery. Disaster recovery is a big area for improvement. You don’t want to worry about losing an entire data center.
Distributed queues. You want to make sure that your data coming into your messaging platform is resilient, and that you have distributed queues and topics.
Security. Security is probably one of the biggest holes that exists in Kafka. It’s a really big opportunity for the open source space or for any platform provider to deliver security on that model. We need authentication, wire-level encryption, and granular user access controls.
Administration. From an administration standpoint, if it takes too long for people to set up something like a general record definition store, it will be difficult to get more people to use the technology.
If you start thinking about the use cases here, there’s a huge opportunity in delivering more benefits from a streaming platform and a messaging platform than what we’re currently seeing. One of the things that, again, all too often I hear is that people confuse pure streaming processing engines with everything else. All of these other applications out there, they could still benefit from a messaging platform without being what we would typically define as a streaming application. There are really big opportunities when you ask yourself, “I need to inspect what’s going on. I need to see the data that’s coming through the topic. What happened yesterday? I have a bad result in my output from my stream processing engine. What were the events that went into it? I want to go back and replay it. I want to query it and I want to build analytic tools around it.”
Here’s one more scenario: if you want to add more capacity to your application stack and if you start thinking about micro services or other types of services, this is a great example of being able to pass things through a messaging system. If it’s not capable of handling extremely large volumes of messages, you’re going to have a problem scaling these services out.
Stream Processing Engines
Stream processing engines seem to be garnering the most attention these days. In general, streaming is simple, fundamentally. Optimizations are the real killer when it comes to stream processing. Just like I mentioned with the messaging platform, getting it configured properly, and managing it within your environment can be a challenge.
Apache Flink. Apache Flink has a streaming first approach. They built a stream processing engine and wrapped APIs around the stream processing to create batch processing capabilities. The thing that I personally like about Flink is that it has pretty simple APIs and it’s built around event-based streaming. Event by event, it can process it and move on.
Apache Samza. Samza is a distributed stream processing system built on Kafka and YARN. The general consensus is that it’s not as easy to get started with Samza as it is to get started with others such as Flink or Spark streaming.

Spark Streaming. Spark came out of UC Berkeley. It is a batch-first model with streaming added on later. It’s very easy to get started with. However, it’s not a perfect fit for every use case. If you want to do event-based streaming, don’t use it, as it’s not built for that. Spark Streaming isn’t real-time; it’s near-time.
Apache Storm. Storm has been the dominant choice for productionization of stream processing up until recently. Twitter announced early in 2015 that they have migrated off Storm, and they’re now on their own engine called Heron. There are things about it that people like. It is event-based. I think the best way that I’ve heard it said is, “It scales up pretty easily, but scaling down is a little bit of a pain.” It’s got decent documentation, and a lot of people have used it in production environments.
Why It Doesn’t Make Sense to Compare Streaming Performance
It’s just not fair to do the comparisons between the different streaming engines that are out there for the most part. It’s not to say that there can’t be some nice comparisons drawn between them, but it’s really tough. You’ll probably see Flink is about the fastest for event processing streaming engines. There are a good number of people who have started using Flink who have gotten some great results for event-based performance. Samza and Storm will follow very closely behind in most of those cases. Please note that when it comes to stream processing engine comparisons, payload size is going to vary drastically. If the payload size is not reasonably close to what you care about, you can probably throw the performance comparison out the window, as it’s going to have a big impact on your use case and how you’re handing events and the type of business logic you’re running.
Also, keep in mind that you can’t make a comparison for something that was running through an at-least-once model and compare it to the performance of an exactly-once model. There’s a lot of extra infrastructure to support the exactly-once model, and if anyone ever shows you that exactly-once is faster than at-least-once, they probably cheated somewhere and didn’t show you everything. For me to say that X, Y, or Z is better would be kind of like comparing a Tesla in Ludicrous Mode with a VW car undergoing an emissions test. The bottom line? Be skeptical of streaming performance comparisons.
In this blog post, you learned about real-time messaging technologies that Jim Scott referenced at Strata+Hadoop World. Please note that in the following month after the conference, MapR announced MapR Streams, the first big data-scale event streaming system built into a converged data platform.
| Reference: | Streaming in the Extreme from our JCG partner Jim Scott at the Mapr blog. |
