A previous post noted that source code structure decays because there are many more ways to build a poorly structured system than a well-structured one, and so, without strict structural guidelines, a system will inevitably explore deeper into disorder state-space until it finds the dark nirvana of ball-of-mud-ness from which few escape. This short post merely demonstrates the phenomenon graphically.
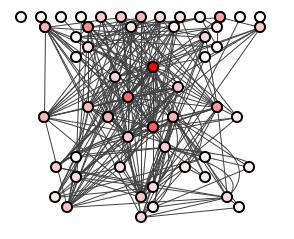
Figure 1 shows a spoiklin diagram of a well-structured system.
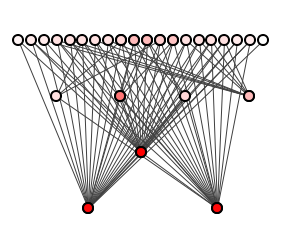
In figure 1, each circle is a package, each straight line a dependency from a package above to one below, each curved line (there are none yet) from a package below to one above.
A system is well-structured when its package dependencies are easy-to-trace, when it readily suggests how updates to any package may ripple to others. The dark red packages at the bottom of Figure 1 are heavily-depended upon, and hence may be expensive to modify; the packages along the top are relatively isolated and thus may be cheap to modify.
Now, let’s say the team responsible for this system a terrible programmer – a Mister Ropy, “Do call me ‘Ent’!” – one who disregards the structural guidelines evidently in place. This chap knows better. He does his own thing. To impress management, Ent initiates a batch of 10 “refactorings”: he moves ten classes to packages in which he thinks they more correctly “belong”.
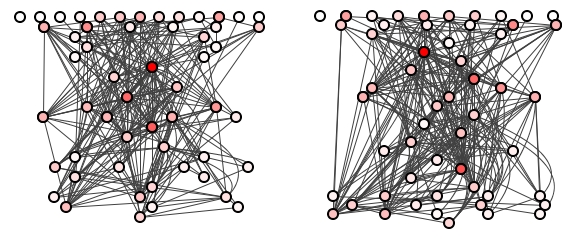
The result of this first batch of refactorings is shown in figure 2, side-by-side with the original for comparison.
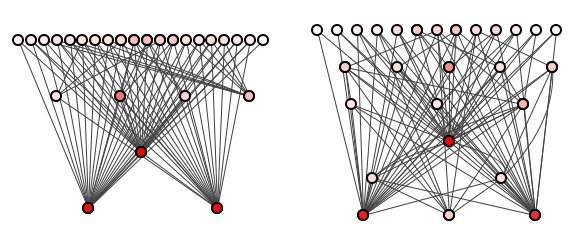
What is your immediate reaction to this? Can you see the difference between the system in this before- and after-refactoring figure? And which system do you think is more well-structured? Specifically, which system’s dependencies are more easily traced?
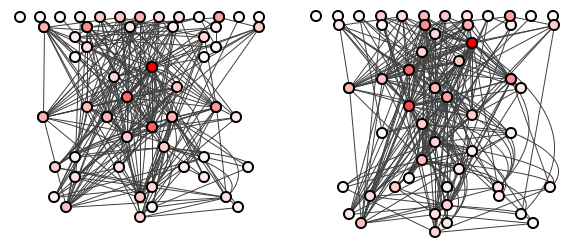
The team quickly reviews this batch of “refactorings” and votes to refuse permission to commit to trunk. Not to be dismissed, however, our new young go-getter comes up with another batch of 10 refactorings – this batch even more correct than the previous. Figure 3 shows the original system side-by-side with the results of this second batch
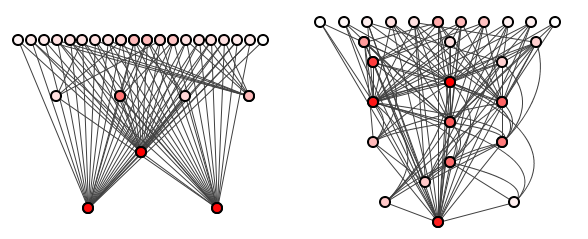
Again: which system do you think is better? Which system’s dependencies are more easily traced?
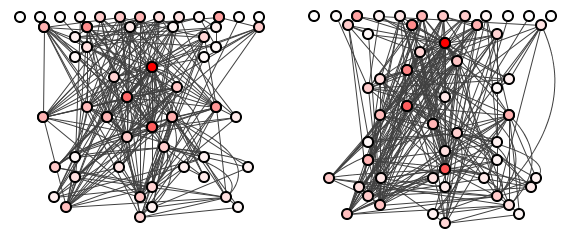
The team quickly deletes the branch again. Mr Ropy, astounded, spends all weekend perfecting a final bestest ever batch of 10 refactorings, once more moving just 10 classes between packages. Figure 4 shows the results.
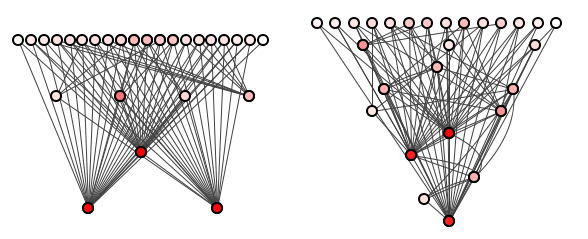
Ent is fired.
He is fired because his “refactorings” were nothing of the sort. Refactorings improve system structure: they make dependencies easier to trace, not harder. Ent’s refactorings simply sucked.
Undeterred, Ent finds employment elsewhere. Figure 5 shows the package-structure of the new system he’s to work on, the recently reviewed Fitnesse.
No sooner is he in door then he embarks on a brave new batch of 10 refactorings, a batch that will make the product just so much easier to work with and leave his manager gob-smacked. The refactorings again simply migrate 10 classes to different packages, and figure 6 shows the result, alongside the original system.
Immediate reaction time: has this batch of refactorings made the system better or worse? Are dependencies more easily traced before the refactorings or after?
The product team declines the kind offer and deletes the branch. Ent, predictably, ruminates and devises batch number 2, see figure 7.
And this time, he’s thought ahead. He’s prepared an alternatve third batch of refactorings simultaneously, for extra bedazzlement. See figure 8.
What do you think of Mister Ropy’s efforts on this second system?
Few programmers could easily tell whether any of these batches made the system’s structure better or worse. You could probably guess (the third seems worse, perhaps?) but it is not immediately obvious.
Now, the shocking reveal: Mister Ropy does not exist! The six batches above were chosen entirely randomly: the class to be moved was randomly selected, as was the target package.
Of course, no one would actually make changes like this, but the point here is that your system should be so well-structured that the degradation brought about by batches of random refactorings should be immediately, screamingly obvious to all. In this sense, good structure is fragile and unstable, in that even small changes can produce large harmful effect. Poor structure, on the other, is remarkably stable: you can make great series of changes to it, but it’s properties will remain more or less the same. Order tends to disorder, and disorder tends to stay just where it is, thank you very much.
If you were developing that first system above and arrived in on Monday morning to see any of those “refactored” package diagrams, you’d mash the emergency WTF-alarm and lock-down the entire building to hunt for the culprit.
If you worked on the second system, honestly, would you even know anything had changed when you started your week’s work?
To put it another way: if you can make random structural changes to your system without noticing a clear degradation, then your system’s structure is random. It is maximally disordered. Your ability to predict modification costs will be minimized, and the actual costs will bear little relation to the size of the modification you wish to effect.
The question is: would you want a Mister Ropy to join your organization? Are you confident enough in system’s structure to believe that his incompetence would be exposed? And would you know if he were already working beside you?
Summary
The universe hates programmers.
When it comes to behaviour, we want our programs to be stable: we want them to react uniformly and predictably under widely varying conditions. But all programs want to do – as every programmers knows – is throw NullPointerExceptions as far and as fast as their digital arms allow.
When it comes to structure, we want our source code organization to be as unstable as possible so that we can clearly see how modifications to one part might affect others. But all source code structure wants to do – as every programmer knows – is collapse at the speed of light into the most widely deployed source-code structure on earth: the ball-of-mud.
And when it comes to refactoring, life’s a batch.
| Reference: | The spectacular instability of good code structure from our JCG partner Edmund Kirwan at the A blog about software. blog. |

Thanks for writing and posting that. It’s good to know that I am not alone in my struggle against entropy, and that the company I keep can express ideas so well. The diagrams made things clear too. ;-) I have bookmarked your article for future reference.
I thoroughly enjoyed this article. I’ve never had the thought, before, that I should have my program’s structure to be as unstable as possible. That sounds so strange, but I get it now, and it is similar to how I’ve been doing things, after hard-won lessons. In my test runner, I already declare which of my classes has no dependencies, so they can all be tested together. Then, the list of classes that depends on just those. And so on, in layers.
nice article