Editor’s Note: Don’t miss our new free on-demand training course about how to create data pipeline applications using Apache Spark – learn more here.
This post will help you get started using Apache Spark GraphX with Scala on the MapR Sandbox. GraphX is the Apache Spark component for graph-parallel computations, built upon a branch of mathematics called graph theory. It is a distributed graph processing framework that sits on top of the Spark core.
Overview of some graph concepts
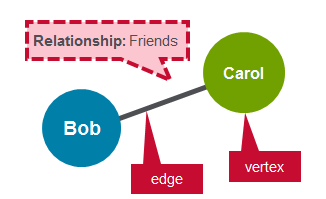
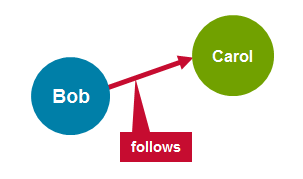
A graph is a mathematical structure used to model relations between objects. A graph is made up of vertices and edges that connect them. The vertices are the objects and the edges are the relationships between them.
A directed graph is a graph where the edges have a direction associated with them. An example of a directed graph is a Twitter follower. User Bob can follow user Carol without implying that user Carol follows user Bob.
A regular graph is a graph where each vertex has the same number of edges. An example of a regular graph is Facebook friends. If Bob is a friend of Carol, then Carol is also a friend of Bob.
GraphX Property Graph
GraphX extends the Spark RDD with a Resilient Distributed Property Graph.
The property graph is a directed multigraph which can have multiple edges in parallel. Every edge and vertex has user defined properties associated with it. The parallel edges allow multiple relationships between the same vertices.
In this activity, you will use GraphX to analyze flight data.
Scenario
As a starting simple example, we will analyze three flights. For each flight, we have the following information:
| Originating Airport | Destination Airport | Distance |
| SFO | ORD | 1800 miles |
| ORD | DFW> | 800 miles |
| DFW | SFO> | 1400 miles |
In this scenario, we are going to represent the airports as vertices and routes as edges. For our graph we will have three vertices, each representing an airport. The distance between the airports is a route property, as shown below: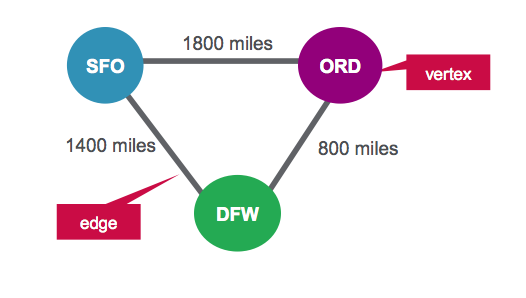
Vertex Table for Airports
| ID | Property |
| 1 | SFO |
| 2 | ORD |
| 3 | DFW |
Edges Table for Routes
| SrcId | DestId | Property |
| 1 | 2 | 1800 |
| 2 | 3 | 800 |
| 3 | 1 | 1400 |
Software
This tutorial will run on the MapR Sandbox, which includes Spark.
- You can download the code and data to run these examples from here:
- The examples in this post can be run in the Spark shell, after launching with the spark-shell command.
- You can also run the code as a standalone application as described in the tutorial on Getting Started with Spark on MapR Sandbox.
Launch the Spark Interactive Shell
Log into the MapR Sandbox, as explained in Getting Started with Spark on MapR Sandbox, using userid user01, password mapr. Start the spark shell with:
1 | $ spark-shell |
Define Vertices
First we will import the GraphX packages.
(In the code boxes, comments are in Green and output is in Blue)
1 2 3 4 | import org.apache.spark._import org.apache.spark.rdd.RDD// import classes required for using GraphXimport org.apache.spark.graphx._ |
We define airports as vertices. Vertices have an Id and can have properties or attributes associated with them. Each vertex consists of :
- Vertex id → Id (Long)
- Vertex Property → name (String)
Vertex Table for Airports
| ID | Property(V) |
| 1 | SFO |
We define an RDD with the above properties that is then used for the vertexes.
1 2 3 4 5 6 7 | // create vertices RDD with ID and Nameval vertices=Array((1L, ("SFO")),(2L, ("ORD")),(3L,("DFW")))val vRDD= sc.parallelize(vertices)vRDD.take(1)// Array((1,SFO)) // Defining a default vertex called nowhereval nowhere = "nowhere" |
Define Edges
Edges are the routes between airports. An edge must have a source, a destination, and can have properties. In our example, an edge consists of:
- Edge origin id → src (Long)
- Edge destination id → dest (Long)
- Edge Property distance → distance (Long)
Edges Table for Routes
| srcid | destid | Property(E) |
| 1 | 12 | 1800 |
We define an RDD with the above properties that is then used for the edges. The edge RDD has the form (src id, dest id, distance ).
1 2 3 4 5 | // create routes RDD with srcid, destid, distanceval edges = Array(Edge(1L,2L,1800),Edge(2L,3L,800),Edge(3L,1L,1400))val eRDD= sc.parallelize(edges) eRDD.take(2)// Array(Edge(1,2,1800), Edge(2,3,800)) |
Create Property Graph
To create a graph, you need to have a Vertex RDD, Edge RDD, and a Default vertex.
Create a property graph called graph.
01 02 03 04 05 06 07 08 09 10 11 12 | // define the graphval graph = Graph(vRDD,eRDD, nowhere)// graph verticesgraph.vertices.collect.foreach(println)// (2,ORD)// (1,SFO)// (3,DFW) // graph edgesgraph.edges.collect.foreach(println) // Edge(1,2,1800)// Edge(2,3,800)// Edge(3,1,1400) |
1. How many airports are there?
1 2 3 | // How many airports?val numairports = graph.numVertices// Long = 3 |
2. How many routes are there?
1 2 3 | // How many routes?val numroutes = graph.numEdges// Long = 3 |
3. which routes > 1000 miles distance?
1 2 3 4 | // routes > 1000 miles distance?graph.edges.filter { case Edge(src, dst, prop) => prop > 1000 }.collect.foreach(println)// Edge(1,2,1800)// Edge(3,1,1400) |
4. The EdgeTriplet class extends the Edge class by adding the srcAttr and dstAttr members which contain the source and destination properties, respectively.
1 2 3 4 5 | // tripletsgraph.triplets.take(3).foreach(println)((1,SFO),(2,ORD),1800)((2,ORD),(3,DFW),800)((3,DFW),(1,SFO),1400) |
5. Sort and print out the longest distance routes
1 2 3 4 5 6 | // print out longest routesgraph.triplets.sortBy(_.attr, ascending=false).map(triplet => "Distance " + triplet.attr.toString + " from " + triplet.srcAttr + " to " + triplet.dstAttr + ".").collect.foreach(println) Distance 1800 from SFO to ORD.Distance 1400 from DFW to SFO.Distance 800 from ORD to DFW. |
Analyze Real Flight Data with GraphX
Scenario
Our data is from http://www.transtats.bts.gov/DL_SelectFields.asp?Table_ID=236&DB_Short_Name=On-Time. We are using flight information for January 2015. For each flight, we have the following information:
| Field | Description | Example Value |
| dOfM(String) | Day of month | 1 |
| dOfW (String) | Day of week | 4 |
| carrier (String) | Carrier code | AA |
| tailNum (String) | Unique identifier for the plane – tail number | N787AA |
| flnum(Int) | Flight number | 21 |
| org_id(String) | Origin airport ID | 12478 |
| origin(String) | Origin Airport Code | JFK |
| dest_id (String) | Destination airport ID | 12892 |
| dest (String) | Destination airport code | LAX |
| crsdeptime(Double) | Scheduled departure time | 900 |
| deptime (Double) | Actual departure time | 855 |
| depdelaymins (Double) | Departure delay in minutes | 0 |
| crsarrtime (Double) | Scheduled arrival time | 1230 |
| arrtime (Double) | Actual arrival time | 1237 |
| arrdelaymins (Double) | Arrival delay minutes | 7 |
| crselapsedtime (Double) | Elapsed time | 390 |
| dist (Int) | Distance | 2475 |
In this scenario, we are going to represent the airports as vertices and routes as edges. We are interested in visualizing airports and routes and would like to see the number of airports that have departures or arrivals.
- You can download the code and data to run these examples from here: https://github.com/caroljmcdonald/sparkgraphxexample
Log into the MapR Sandbox, as explained in Getting Started with Spark on MapR Sandbox, using userid user01, password mapr. Copy the sample data file rita2014jan.csv to your sandbox home directory /user/user01 using scp.
Start the Spark shell with:
1 | $ spark-shell |
Define Vertices
First we will import the GraphX packages.
(In the code boxes, comments are in Green and output is in Blue)
1 2 3 4 5 6 | import org.apache.spark._import org.apache.spark.rdd.RDDimport org.apache.spark.util.IntParam// import classes required for using GraphXimport org.apache.spark.graphx._import org.apache.spark.graphx.util.GraphGenerators |
Below we use Scala case classes to define the flight schema corresponding to the csv data file.
1 2 | // define the Flight Schemacase class Flight(dofM:String, dofW:String, carrier:String, tailnum:String, flnum:Int, org_id:Long, origin:String, dest_id:Long, dest:String, crsdeptime:Double, deptime:Double, depdelaymins:Double, crsarrtime:Double, arrtime:Double, arrdelay:Double,crselapsedtime:Double,dist:Int) |
The function below parses a line from the data file into the flight class.
1 2 3 4 5 | // function to parse input into Flight classdef parseFlight(str: String): Flight = { val line = str.split(",") Flight(line(0), line(1), line(2), line(3), line(4).toInt, line(5).toLong, line(6), line(7).toLong, line(8), line(9).toDouble, line(10).toDouble, line(11).toDouble, line(12).toDouble, line(13).toDouble, line(14).toDouble, line(15).toDouble, line(16).toInt)} |
Below we load the data from the csv file into a Resilient Distributed Dataset (RDD). RDDs can have transformations and actions, the first() action returns the first element in the RDD.
1 2 3 4 5 | // load the data into a RDDval textRDD = sc.textFile("/user/user01/data/rita2014jan.csv")// MapPartitionsRDD[1] at textFile // parse the RDD of csv lines into an RDD of flight classesval flightsRDD = textRDD.map(parseFlight).cache() |
We define airports as vertices. Vertices can have properties or attributes associated with them. Each vertex has the following property:
- Airport name (String)
Vertex Table for Airports
| ID | Property(V) |
| 10397 | ATL |
We define an RDD with the above properties that is then used for the vertexes.
1 2 3 4 5 6 7 8 9 | // create airports RDD with ID and Nameval airports = flightsRDD.map(flight => (flight.org_id, flight.origin)).distinct airports.take(1)// Array((14057,PDX)) // Defining a default vertex called nowhereval nowhere = "nowhere"// Map airport ID to the 3-letter code to use for printlnsval airportMap = airports.map { case ((org_id), name) => (org_id -> name) }.collect.toList.toMap// Map(13024 -> LMT, 10785 -> BTV,…) |
Define Edges
Edges are the routes between airports. An edge must have a source, a destination, and can have properties. In our example, an edge consists of:
- Edge origin id → src (Long)
- Edge destination id → dest (Long)
- Edge property distance → distance (Long)
Edges Table for Routes
| srcid | destid | Property(E) |
| 14869 | 14683 | 1087 |
We define an RDD with the above properties that is then used for the edges. The edge RDD has the form (src id, dest id, distance).
1 2 3 4 5 6 7 8 9 | // create routes RDD with srcid, destid, distanceval routes = flightsRDD.map(flight => ((flight.org_id, flight.dest_id), flight.dist)).distinctdistinct routes.take(2)// Array(((14869,14683),1087), ((14683,14771),1482)) // create edges RDD with srcid, destid , distanceval edges = routes.map { case ((org_id, dest_id), distance) =>Edge(org_id.toLong, dest_id.toLong, distance) } edges.take(1)//Array(Edge(10299,10926,160)) |
Create Property Graph
To create a graph, you need to have a Vertex RDD, Edge RDD and a Default vertex.
Create a property graph called graph.
1 2 3 4 5 6 7 8 | // define the graphval graph = Graph(airports, edges, nowhere) // graph verticesgraph.vertices.take(2)Array((10208,AGS), (10268,ALO)) // graph edgesgraph.edges.take(2)Array(Edge(10135,10397,692), Edge(10135,13930,654)) |
6. How many airports are there?
1 2 3 | // How many airports?val numairports = graph.numVertices// Long = 301 |
7. How many routes are there?
1 2 3 | // How many airports?val numroutes = graph.numEdges// Long = 4090 |
8. Which routes > 1000 miles distance?
1 2 3 | // routes > 1000 miles distance?graph.edges.filter { case ( Edge(org_id, dest_id,distance))=> distance > 1000}.take(3)// Array(Edge(10140,10397,1269), Edge(10140,10821,1670), Edge(10140,12264,1628)) |
9. The EdgeTriplet class extends the edge class by adding the srcAttr and dstAttr members which contain the source and destination properties, respectively.
1 2 3 4 5 | // tripletsgraph.triplets.take(3).foreach(println)((10135,ABE),(10397,ATL),692)((10135,ABE),(13930,ORD),654)((10140,ABQ),(10397,ATL),1269) |
10. Sort and print out the longest distance routes
01 02 03 04 05 06 07 08 09 10 11 12 13 | // print out longest routesgraph.triplets.sortBy(_.attr, ascending=false).map(triplet => "Distance " + triplet.attr.toString + " from " + triplet.srcAttr + " to " + triplet.dstAttr + ".").take(10).foreach(println) Distance 4983 from JFK to HNL.Distance 4983 from HNL to JFK.Distance 4963 from EWR to HNL.Distance 4963 from HNL to EWR.Distance 4817 from HNL to IAD.Distance 4817 from IAD to HNL.Distance 4502 from ATL to HNL.Distance 4502 from HNL to ATL.Distance 4243 from HNL to ORD.Distance 4243 from ORD to HNL. |
11. Compute the highest degree vertex
01 02 03 04 05 06 07 08 09 10 11 12 13 | // Define a reduce operation to compute the highest degree vertexdef max(a: (VertexId, Int), b: (VertexId, Int)): (VertexId, Int) = { if (a._2 > b._2) a else b}val maxInDegree: (VertexId, Int) = graph.inDegrees.reduce(max)//maxInDegree: (org.apache.spark.graphx.VertexId, Int) = (10397,152) val maxOutDegree: (VertexId, Int) = graph.outDegrees.reduce(max)//maxOutDegree: (org.apache.spark.graphx.VertexId, Int) = (10397,153) val maxDegrees: (VertexId, Int) = graph.degrees.reduce(max)//maxDegrees: (org.apache.spark.graphx.VertexId, Int) = (10397,305) // Get the name for the airport with id 10397airportMap(10397)//res70: String = ATL |
12. Which airport has the most incoming flights?
01 02 03 04 05 06 07 08 09 10 11 12 | // get top 3val maxIncoming = graph.inDegrees.collect.sortWith(_._2 > _._2).map(x => (airportMap(x._1), x._2)).take(3) maxIncoming.foreach(println)(ATL,152)(ORD,145)(DFW,143) // which airport has the most outgoing flights?val maxout= graph.outDegrees.join(airports).sortBy(_._2._1, ascending=false).take(3) maxout.foreach(println)(10397,(153,ATL))(13930,(146,ORD))(11298,(143,DFW)) |
PageRank
Another GraphX operator is PageRank. which is based on the Google PageRank algorithm.
PageRank measures the importance of each vertex in a graph, by determining which vertexes have the most edges with other vertexes. In our example, we can use PageRank to determine which airports are the most important by measuring which airports have the most connections to other airports.
We have to specify the tolerance, which is the measure of convergence.
13. What are the most important airports according to PageRank?
01 02 03 04 05 06 07 08 09 10 11 12 13 14 | // use pageRankval ranks = graph.pageRank(0.1).vertices// join the ranks with the map of airport id to nameval temp= ranks.join(airports)temp.take(1)// Array((15370,(0.5365013694244737,TUL))) // sort by rankingval temp2 = temp.sortBy(_._2._1, false)temp2.take(2)//Array((10397,(5.431032677813346,ATL)), (13930,(5.4148119418905765,ORD))) // get just the airport namesval impAirports =temp2.map(_._2._2)impAirports.take(4)//res6: Array[String] = Array(ATL, ORD, DFW, DEN) |
Pregel
Many important graph algorithms are iterative algorithms, since properties of vertices depend on properties of their neighbors, which depend on properties of their neighbors. Pregel is an iterative graph processing model, developed at Google, which uses a sequence of iterations of messages passing between vertices in a graph. GraphX implements a Pregel-like bulk-synchronous message-passing API.
With the Pregel implementation in GraphX, vertices can only send messages to neighboring vertices.
The Pregel operator is executed in a series of super steps. In each super step:
- The vertices receive the sum of their inbound messages from the previous super step
- They compute a new value for the vertex property
- They send messages to the neighboring vertices in the next super step
When there are no more messages remaining, the Pregel operator will end the iteration and the final graph is returned.
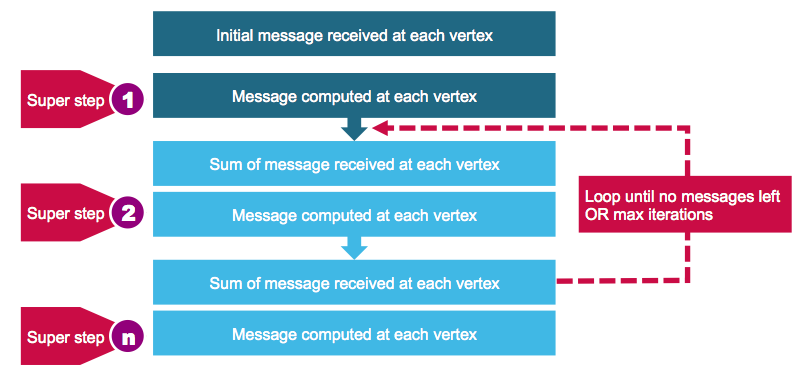
The code below computes the cheapest airfare using Pregel with the following formula to compute airfare.
50 + distance / 20
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | // starting vertexval sourceId: VertexId = 13024// a graph with edges containing airfare cost calculationval gg = graph.mapEdges(e => 50.toDouble + e.attr.toDouble/20 )// initialize graph, all vertices except source have distance infinityval initialGraph = gg.mapVertices((id, _) => if (id == sourceId) 0.0 else Double.PositiveInfinity)// call pregel on graphval sssp = initialGraph.pregel(Double.PositiveInfinity)( // Vertex Program (id, dist, newDist) => math.min(dist, newDist), triplet => { // Send Message if (triplet.srcAttr + triplet.attr < triplet.dstAttr) { Iterator((triplet.dstId, triplet.srcAttr + triplet.attr)) } else { Iterator.empty } }, // Merge Message (a,b) => math.min(a,b)) // routes , lowest flight costprintln(sssp.edges.take(4).mkString("\n"))Edge(10135,10397,84.6)Edge(10135,13930,82.7)Edge(10140,10397,113.45)Edge(10140,10821,133.5) // routes with airport codes , lowest flight costssp.edges.map{ case ( Edge(org_id, dest_id,price))=> ( (airportMap(org_id), airportMap(dest_id), price)) }.takeOrdered(10)(Ordering.by(_._3))Array((WRG,PSG,51.55), (PSG,WRG,51.55), (CEC,ACV,52.8), (ACV,CEC,52.8), (ORD,MKE,53.35), (IMT,RHI,53.35), (MKE,ORD,53.35), (RHI,IMT,53.35), (STT,SJU,53.4), (SJU,STT,53.4)) // airports , lowest flight costprintln(sssp.vertices.take(4).mkString("\n")) (10208,277.79)(10268,260.7)(14828,261.65)(14698,125.25) // airport codes , sorted lowest flight costsssp.vertices.collect.map(x => (airportMap(x._1), x._2)).sortWith(_._2 < _._2)res21: Array[(String, Double)] = Array(PDX,62.05), (SFO,65.75), (EUG,117.35) |
Want to learn more?
- GraphX Programming Guide
- MapR announces Free Complete Apache Spark Training and Developer Certification
- Free Spark On Demand Training
- Get Certified on Spark with MapR Spark Certification
- MapR Certified Spark Developer Study Guide
In this blog post, you learned how to get started using Apache Spark GraphX with Scala on the MapR Sandbox. If you have any questions about GraphX, please ask them in the comments section below.
| Reference: | How to Get Started Using Apache Spark GraphX with Scala from our JCG partner Carol McDonald at the Mapr blog. |
